What is Big Data :- The term ‘big data’ is self-explanatory − a collection of huge data sets that normal computing techniques cannot process. The term not only refers to the data, but also to the various frameworks, tools, and techniques involved. Technological advancement and the advent of new channels of communication (like social networking) and new, stronger devices have presented a challenge to industry players in the sense that they have to find other ways to handle the data.
As Gartner defines it – “Big Data are high volume, high velocity, or high-variety information assets that require new forms of processing to enable enhanced decision making, insight discovery, and process optimization. Let’s dig deeper and understand this in simpler terms.
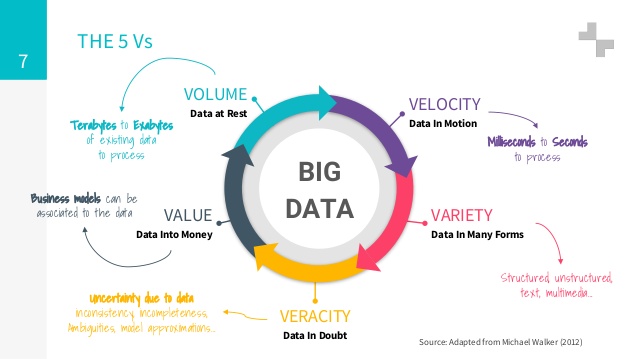
Current usage of the term big data tends to refer to the use of predictive annalistic ,user behavior analytics or certain other advanced data analytics methods that extract value from data, and seldom to a particular size of data set. “There is little doubt that the quantities of data now available are indeed large, but that’s not the most relevant characteristic of this new data ecosystem. Analysis of data sets can find new correlations to “spot business trends, prevent diseases, combat crime and so on
Sources of Big Data :- There are several sources of Big Data and some of them are mentioned below,
- Black Box Data :-This is the data generated by airplanes, including jets and helicopters. Black box data includes flight crew voices, microphone recordings, and aircraft performance information.
2.Social Media Data :-This is data developed by such social media sites as Twitter, Facebook, Instagram, Pinterest, and Google+.
3.Stock Exchange Data :- This is data from stock exchanges about the share selling and buying decisions made by customers.
4.Power Grid Data :- This is data from power grids. It holds information on particular nodes, such as usage information.
5.Transport Data :- This includes possible capacity, vehicle model, availability, and distance covered by a vehicle.
6.Search Engine Data :- This is one of the most significant sources of big data. Search engines have vast databases where they get their data.
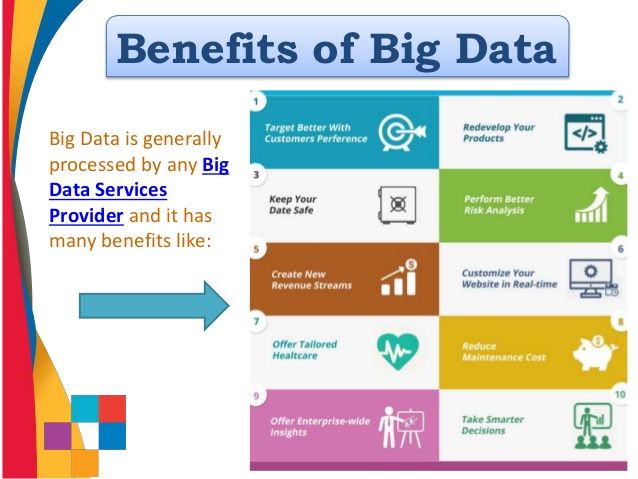
Big Data Benefits :- Usages of Big Data have enabled humans in many ways and benefitted us in many areas of services and technologies. Some of the benefits of Big Data are mentioned below,
- Big data allows you to diversify your revenue streams. Analyzing big data can give you trend-data that could help you come up with a completely new revenue stream.
- Your website needs to be dynamic if it is to compete favorably in the crowded online space. Analysis of big data helps you personalize the look/content and feel of your site to suit every visitor based on, for example, nationality and sex. An example of this is Amazon’s IBCF (item-based collaborative filtering) that drives its “People you may know” and “Frequently bought together” features.
- One of the most important use of Big Data is for healthcare sector. which is one of the last few industries still stuck with a generalized, conventional approach. As an example, if you have cancer, you will go through one therapy, and if it does not work, your doctor will recommend another therapy. Big data allows a cancer patient to get medication that is developed based on his/her genes.
- Today’s consumer is very demanding. He talks to pass customers on social media and looks at different options before buying. A customer wants to be treated as an individual and to be thanked after buying a product. With big data, you will get actionable data that you can use to engage with your customers one-on-one in real-time. One way big data allows you to do this is that you will be able to check a complaining customer’s profile in real-time and get info on the product/s he/she is complaining about. You will then be able to perform reputation management.
- Big data allows you to re-develop the products/services you are selling. Information on what others think about your products -such as through unstructured social networking site text- helps you in product development.
- Predictive analysis will keep you ahead of your competitors. Big data can facilitate this by, as an example, scanning and analyzing social media feeds and newspaper reports. Big data also helps you do health-tests on your customers, suppliers, and other stakeholders to help you reduce risks such as default.
Top 9 best & most popular Big Data Hadoop tools:
To save your time and help you pick the right tool, we have constructed a list of top Big Data Hadoop tools in the areas of data extracting, storing, cleaning, mining, visualizing, analyzing and integrating.
- Talend :- Talend is a software vendor specializing in Big Data Integration. Talend Open Studio for Data Integration helps you to efficiently and effectively manage all facets of data extraction, data transformation, and data loading using of their ETL system. In computing, Extract, Transform, Load (ETL) refers to a process in database usage and especially in data warehousing. Data extraction is where data is extracted from data sources; data transformation where the data is transformed for storing in the proper format; data loading where the data is loaded into the final target database.
2.Pentaho :- Also called as Kettle is the component of Pentaho responsible for the Extract, Transform and Load (ETL) processes. PDI is created with a graphical tool where you specify what to do without writing code to indicate how to do it. Pentaho can be used as a standalone application, or it can be used as part of the larger Pentaho Suite. As an ETL tool, it is the most popular open source tool available. PDI supports a vast array of input and output formats, including text files, data sheets, and commercial and free database engines.
3.Hive :- Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop. It supports queries expressed in a language called HiveQL, which automatically translates SQL-like queries into MapReduce jobs executed on Hadoop.
Apache Hive supports analysis of large datasets stored in Hadoop’s HDFS and compatible file systems such as Amazon S3 file system. Other features of Hive include:
- Index type including compaction and Bitmap index as of 0.10
- Variety of storage types such as plain text, RCFile, HBase, ORC, and others
- Operating on algorithms including DEFLATE, BWT, snappy, etc.
4. Sqoop :- Saqoop which is a SQL to Hadoop is a big data tool that offers the capability to extract data from non-Hadoop data stores, transform the data into a form usable by Hadoop, and then load the data into HDFS. It supports incremental loads of a single table or a free form SQL query as well as saved jobs which can be run multiple times to import updates made to a database since the last import.
5. MongoDB :- MongoDB is an open source database that uses a document-oriented data model. MongoDB. MongoDB can be used as a file system with load balancing and data replication features over multiple machines for storing files. MongoDB stores data using a flexible document data model that is similar to JSON. Documents contain one or more fields, including arrays, binary data and sub-documents.
6. Oracle Data Mining :- (ODM), a component of the Oracle Advanced Analytics Database Option, provides powerful data mining algorithms that enable data analysts to discover insights, make predictions and leverage their Oracle data and investment. Oracle Corporation has implemented a variety of data mining algorithms inside the Oracle relational database. you can build and apply predictive models inside the Oracle Database to help you predict customer behavior, develop customer profiles, identify cross-selling opportunities and detect potential fraud by using Oracle Data Mining System.
7. HBase :- It is an open source, non-relational, distributed database and is written in Java. It is developed as part of Apache Software Foundation’s Apache Hadoop project and runs on top of HDFS (Hadoop Distributed File System). Apache HBase is a NoSQL database that runs on top of Hadoop as a distributed and scalable big data store. HBase can leverage the distributed processing of the Hadoop Distributed File System. It is meant to host large tables with billions of rows with potentially millions of columns and run across a cluster of commodity hardware. It have several features such as :
- Linear and modular scalability
- Convenient base classes for backing Hadoop
- Easy to use Java API for client access
- Block cache and Bloom Filters for real-time queries
- Query predicate push down via server side Filters
- Support for exporting metrics
8. Pig :- Apache Pig is a high-level platform for creating programs that run on Apache Hadoop. Pig is complete, so you can do all required data manipulations in Apache Hadoop with Pig. It have features such as :-
- It is trivial to achieve parallel execution of simple
- Permits the system to optimize their execution automatically
- Users can create their own functions to do special-purpose processing.
9. Zookeeper :- Apache Zookeeper is a coordination service for distributed application that enables synchronization across a cluster. Zookeeper in Hadoop can be viewed as centralized repository where distributed applications can put data and get data out of it. Also provides an infrastructure for cross-node synchronization and can be used by applications to ensure that tasks across the cluster are serialized or synchronized. Zookeeper allows developers to focus on core application logic without worrying about the distributed nature of the application. Zookeeper have features such as :
- Managing and configuration of nodes
- Implement reliable messaging
- Implement redundant services
- Synchronize process execution
Conclusion :- Data is everywhere so there is no doubt that by using this huge amount of data we are going to solve many problems or humans and but on the other side we are going to be dependent on it. Big Data is going to change the way we live in future I believe this article has helped you understand what is Big Data, and if you are still curious to know more then you can join the Masters in Big Data Program offered by Devopsschool, which will help you to master the concepts of the Hadoop framework.
Useful Reference:-
- Best SEO Online Courses
- Search Engine Optimization Crash Course
- Search Engine Optimization Training
- Search Engine Optimization Certification
- Best Courses for Machine Learning
- Best Courses for Artificial Intelligence
- Top Courses for Data Science Online
Best Artificial Intelligence Course

- DevOps Certified Professionals (DCP)
- Site Reliability Engineering Certified Professionals (SRECP)
- Master in DevOps Engineering (MDE)
- DevSecOps Certified Professionals (DSOCP)
URL - https://www.devopsschool.com/certification/
My Linkedin - https://www.linkedin.com/in/rajeshkumarin
- Installing Jupyter: Get up and running on your computer - November 2, 2024
- An Introduction of SymOps by SymOps.com - October 30, 2024
- Introduction to System Operations (SymOps) - October 30, 2024
