
The Splunk is a technology that is used for searching, monitoring, picturing, and analyzing machine data on an actual source. It is a tool for log supervision and analysis. The Splunk is not a SIEM but can be used it for similar purposes. It is mainly for log management and stores the actual data as events in the form of indexers. It helps to visualize data in the form of dashboards.

The SIEM cannot keep pace with the complexity and rate of recent cyber threats. This is an analytically ambitious security solution that goes beyond SIEM to deal with advanced threat detection, security monitoring, incident management, and forensics on an actual basis. This analytics-driven system can recover your discernibility across multiple systems and with cross-collaboration it provides a strong security system.
Interview Questions and Answers:-
1) Define Splunk
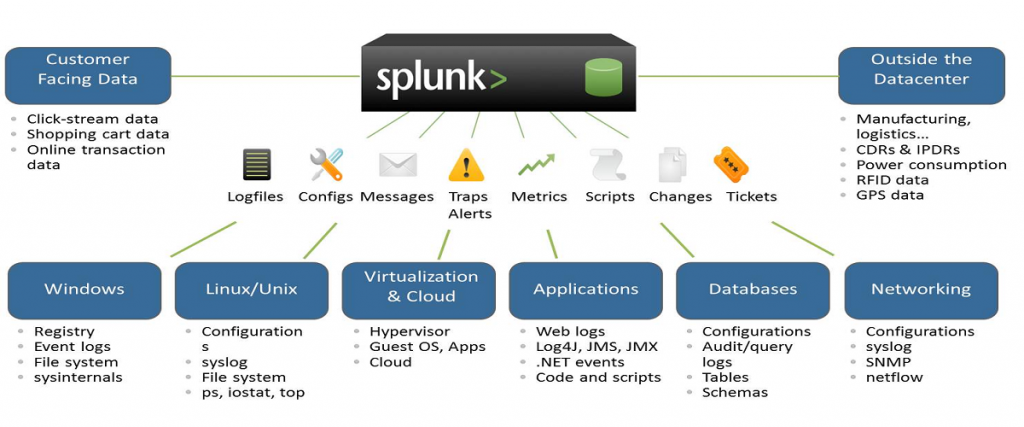
It is a software technology that is used for searching, visualizing, and monitoring machine-generated big data. It monitors and different types of log files and stores data in Indexers.
2) List out common ports used by Splunk.
Common ports used by Splunk are as follows:
- Web Port: 8000
- Management Port: 8089
- Network port: 514
- Index Replication Port: 8080
- Indexing Port: 9997
- KV store: 8191
3) Explain Splunk components
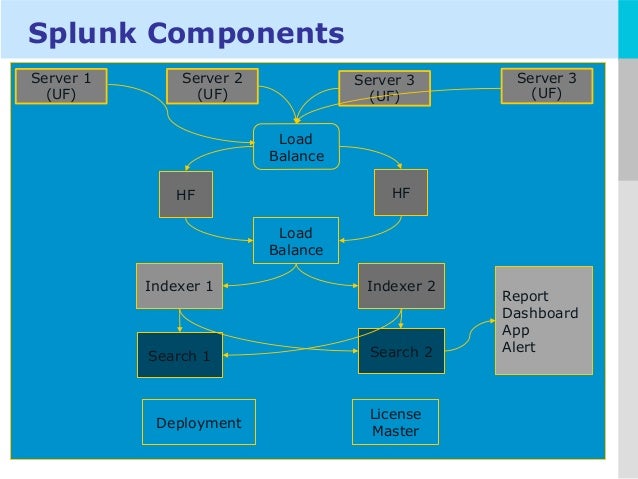
The fundamental components of Splunk are:
- Universal forward: It is a lightweight component which inserts data to Splunk forwarder.
- Heavy forward: It is a heavy component that allows you to filter the required data.
- Search head: This component is used to gain intelligence and perform reporting.
- License manager: The license is based on volume & usage. It allows you to use 50 GB per day. Splunk regular checks the licensing details.
- Load Balancer: In addition to the functionality of default Splunk loader, it also enables you to use your personalized load balancer.
4) What do you mean by Splunk indexer?
It is a component of Splunk Enterprise which creates and manages indexes. The primary functions of an indexer are 1) Indexing raw data into an index and 2) Search and manage Indexed data.
5) What are the disadvantages of using Splunk?
Some disadvantages of using Splunk tool are:
- Splunk can prove expensive for large data volumes.
- Dashboards are functional but not as effective as some other monitoring tools.
- Its learning curve is stiff, and you need Splunk training as it’s a multi-tier architecture. So, you need to spend lots of time to learn this tool.
- Searches are difficult to understand, especially regular expressions and search syntax.
6) What are the pros of getting data into a Splunk instance using forwarders?
The advantages of getting data into Splunk via forwarders are TCP connection, bandwidth throttling, and secure SSL connection for transferring crucial data from a forwarder to an indexer.
7) What is the importance of license master in Splunk?
License master in Splunk ensures that the right amount of data gets indexed. It ensures that the environment remains within the limits of the purchased volume as Splunk license depends on the data volume, which comes to the platform within a 24-hour window.
8) Name some important configuration files of Splunk
Commonly used Splunk configuration files are:
- Inputs file
- Transforms file
- Server file
- Indexes file
- Props file
9) Explain license violation in Splunk.
It is a warning error that occurs when you exceed the data limit. This warning error will persist for 14 days. In a commercial license, you may have 5 warnings within a 1-month rolling window before which your Indexer search results and reports stop triggering.
However, in a free version, license violation warning shows only 3 counts of warning.
10) What is the use of Splunk alert?
Alerts can be used when you have to monitor for and respond to specific events. For example, sending an email notification to the user when there are more than three failed login attempts in a 24-hour period.
11) Explain map-reduce algorithm
Map-reduce algorithm is a technique used by Splunk to increase data searching speed. It is inspired by two functional programming functions 1) reduce () 2) map().
Here map() function is associated with Mapper class and reduce() function is associated with a Reducer class.
12) Explain different types of data inputs in Splunk?
Following are different types of data inputs in Splunk:
- Using files and directories as input
- Configuring Network ports to receive inputs automatically
- Add windows inputs. These windows inputs are of four types: 1) active directory monitor, 2) printer monitor, 3) network monitor, and 4) registry inputs monitor.
13) How Splunk avoids duplicate log indexing?
Splunk allows you to keep track of indexed events in a fish buckets directory. It contains CRCs and seeks pointers for the files you are indexing, so Splunk can’t if it has read them already.
14) Explain pivot and data models.
Pivots are used to create the front views of your output and then choose the proper filter for a better view of this output. Both options are beneficial for the people from a semi-technical or non-technical background.
Data models are most commonly used for creating a hierarchical model of data. However, it can also be used when you have a large amount of unstructured data. It helps you make use of that information without using complicated search queries.
15) Explain search factor and replication factor?
Search factor determines the number of data maintained by the indexer cluster. It determines the number of searchable copies available in the bucket.
Replication factor determines the number of copies maintained by the cluster as well as the number of copies that each site maintains.
16) What is the use of lookup command?
Lookup command is generally used when you want to get some fields from an external file. It helps you to narrow the search results as it helps to reference fields in an external file that match fields in your event data.
17) Explain default fields for an event in Splunk
There are 5 default fields which are barcoded with every event into Splunk. They are: 1) host, 2) source, 3) source type, 4) index, and 5) timestamp.
18) How can you extract fields?
In order to extract fields from either sidebar, event lists or the settings menu using UI.
Another way to extract fields in Splunk is to write your regular expressions in a props configuration file.
19) What do you mean by summary index?
A summary index is a special index that stores that result calculated by Splunk. It is a fast and cheap way to run a query over a longer period of time.
20) How to prevent events from being indexed by Splunk?
You can prevent the event from being indexed by Splunk by excluding debug messages by putting them in the null queue. You have to keep the null queue in transforms.conf file at the forwarder level itself.
21) Define Splunk DB connect
It is a SQL database plugin which enables to import tables, rows, and columns from a database add the database. Splunk DB connect helps in providing reliable and scalable integration between databases and Splunk Enterprises.
22) Define Splunk buckets
It is the directory used by Splunk enterprise to store data and indexed files into the data. These index files contain various buckets managed by the age of the data.
23) What is the function of Alert Manager?
The alert manager adds workflow to Splunk. The purpose of alert manager o provides a common app with dashboards to search for alerts or events.
24) How can you troubleshoot Splunk performance issues?
Three ways to troubleshoot Splunk performance issue.
- See server performance issues.
- See for errors in splunkd.log.
- Install Splunk app and check for warnings and errors in the dashboard.
25) What is the difference between Index time and Search time?
Index time is a period when the data is consumed and the point when it is written to disk. Search time take place while the search is run as events are composed by the search.
26) How to reset the Splunk administrator password?
In order to reset the administrator password, perform the following steps:
- Login into the server on which Splunk is installed
- Rename the password file and then again start the Splunk.
- After this, you can sign into the server by using username either administrator or admin with a password changeme.
27) Name the command which is used to the “filtering results” category
The command which is used to the “filtering results” category is: “where,” “Sort,” “rex,” and “search.”
28) List out different types of Splunk licenses
The types of Splunk licenses are as follows:
- Free license
- Beta license
- Search heads license
- Cluster members license
- Forwarder license
- Enterprise license
29) List out the number of categories of the SPL commands.
The SPL commands are classified into five categories:
1) Filtering Results, 2) Sorting Results, 3) Filtering Grouping Results, 4) Adding Fields, and 5) Reporting Results.
30) What is eval command?
This command is used to calculate an expression. Eval command evaluates boolean expressions, string, and mathematical articulations. You can use multiple eval expressions in a single search using a comma.
31. How to reset Splunk Admin password?
Resetting the Splunk Admin password depends on the version of Splunk. If we are using Splunk 7.1 and above, then we have to follow the below steps:
- First, we have to stop our Splunk Enterprise
- Now, we need to find the ‘passwd’ file and rename it to ‘passwd.bk’
- Then, we have to create a file named ‘user-seed.conf’ in the below directory:
- $SPLUNK_HOME/etc/system/local/
- In the file, we will have to use the following command (here, in the place of ‘NEW_PASSWORD’, we will add our own new password):
- [user_info]
- PASSWORD = NEW_PASSWORD
- After that, we can just restart the Splunk Enterprise and use the new password to log in
- Now, if we are using the versions prior to 7.1, we will follow the below steps:
- First, stop the Splunk Enterprise
- Find the passwd file and rename it to ‘passw.bk’
- Start Splunk Enterprise and log in using the default credentials of admin/changeme
- Here, when asked to enter a new password for our admin account, we will follow the instructions
- Note: In case we have created other users earlier and know their login details, copy and paste their credentials from the passwd.bk file into the passwd file and restart Splunk.
32. How to disable Splunk Launch Message?
Set value OFFENSIVE=Less in splunk_launch.conf
33. How to clear Splunk Search History?
We can clear Splunk search history by deleting the following file from the Splunk server:
$splunk_home/var/log/splunk/searches.log
34. What is Btool? How will you troubleshoot Splunk configuration files?
Splunk Btool is a command-line tool that helps us troubleshoot configuration file issues or just see what values are being used by our Splunk Enterprise installation in the existing environment.
35. What is the difference between Splunk App and Splunk Add-on?
In fact, both contain preconfigured configuration, reports, etc., but the Splunk add-on does not have a visual app. On the other hand, a Splunk app has a preconfigured visual app.
36. What is .conf files precedence in Splunk?
File precedence is as follows:
System local directory — highest priority
App local directories
App default directories
System default directory — lowest priority
37. What is Fishbucket? What is Fishbucket Index?
Fishbucket is a directory or index at the default location:
/opt/splunk/var/lib/splunk
It contains seek pointers and CRCs for the files we are indexing, so ‘splunkd’ can tell us if it has read them already. We can access it through the GUI by searching for:
index=_thefishbucket
38. How do I exclude some events from being indexed by Splunk?
This can be done by defining a regex to match the necessary event(s) and sending everything else to NullQueue. Here is a basic example that will drop everything except events that contain the string login:
In props.conf:
<code>[source::/var/log/foo]
# Transforms must be applied in this order
# to make sure events are dropped on the
# floor prior to making their way to the
# index processor
TRANSFORMS-set= setnull,setparsing
</code>
In transforms.conf:
[setnull] REGEX = . DEST_KEY = queue FORMAT = nullQueue
[setparsing]
REGEX = login
DEST_KEY = queue
FORMAT = indexQueue
39. How can I understand when Splunk has finished indexing a log file?
We can figure this out:
By watching data from Splunk’s metrics log in real-time:
index=”_internal” source=”*metrics.log” group=”per_sourcetype_thruput” series=”<your_sourcetype_here>” |
eval MB=kb/1024 | chart sum(MB)
By watching everything split by source type:
index=”_internal” source=”*metrics.log” group=”per_sourcetype_thruput” | eval MB=kb/1024 | chart sum(MB) avg(eps) over series
If we are having trouble with data input and we want a way to troubleshoot it, particularly if our whitelist/blacklist rules are not working the way we expected, we will go to the following URL:
For more on these, visit our Splunk Community!
40. How to set the default search time in Splunk 6?
To do this in Splunk Enterprise 6.0, we have to use ‘ui-prefs.conf’. If we set the value in the following, all our users would see it as the default setting:
$SPLUNK_HOME/etc/system/local
For example, if our
$SPLUNK_HOME/etc/system/local/ui-prefs.conf file
includes:
[search]
dispatch.earliest_time = @d
dispatch.latest_time = now
The default time range that all users will see in the search app will be today.
The configuration file reference for ui-prefs.conf is here:
http://docs.splunk.com/Documentation/Splunk/latest/Admin/Ui-prefsconf
41. What is Dispatch Directory?
$SPLUNK_HOME/var/run/splunk/dispatch
contains a directory for each search that is running or has completed. For example, a directory named 1434308943.358 will contain a CSV file of its search results, a search.log with details about the search execution, and other stuff. Using the defaults (which we can override in limits.conf), these directories will be deleted 10 minutes after the search completes—unless the user saves the search results, in which case the results will be deleted after 7 days.
42. What is the difference between Search Head Pooling and Search Head Clustering?
Both are features provided by Splunk for the high availability of Splunk search head in case any search head goes down. However, the search head cluster is newly introduced and search head pooling will be removed in the next upcoming versions.
The search head cluster is managed by a captain, and the captain controls its slaves. The search head cluster is more reliable and efficient than the search head pooling.
43. If I want to add folder access logs from a windows machine to Splunk, how do I do it?
Below are the steps to add folder access logs to Splunk:
Enable Object Access Audit through group policy on the Windows machine on which the folder is located
Enable auditing on a specific folder for which we want to monitor logs
Install Splunk universal forwarder on the Windows machine
Configure universal forwarder to send security logs to Splunk indexer
44. How would you handle/troubleshoot Splunk License Violation Warning?
A license violation warning means that Splunk has indexed more data than our purchased license quota. We have to identify which index/source type has received more data recently than the usual daily data volume. We can check the Splunk license master pool-wise available quota and identify the pool for which the violation has occurred. Once we know the pool for which we are receiving more data, then we have to identify the top source type for which we are receiving more data than the usual data. Once the source type is identified, then we have to find out the source machine which is sending the huge number of logs and the root cause for the same and troubleshoot it, accordingly.
45. What is MapReduce algorithm?
MapReduce algorithm is the secret behind Splunk’s faster data searching. It’s an algorithm typically used for batch-based large-scale parallelization. It’s inspired by functional programming’s map() and reduce() functions.
46. How does Splunk avoid the duplicate indexing of logs?
At the indexer, Splunk keeps track of the indexed events in a directory called fishbucket with the default location:
/opt/splunk/var/lib/splunk
It contains seek pointers and CRCs for the files we are indexing, so splunkd can tell us if it has read them already.
47. What is the difference between Splunk SDK and Splunk Framework?
Splunk SDKs are designed to allow us to develop applications from scratch and they do not require Splunk Web or any components from the Splunk App Framework. These are separately licensed from Splunk and do not alter the Splunk Software.
Splunk App Framework resides within the Splunk web server and permits us to customize the Splunk Web UI that comes with the product and develop Splunk apps using the Splunk web server. It is an important part of the features and functionalities of Splunk, which does not license users to modify anything in Splunk.
48. For what purpose inputlookup and outputlookup are used in Splunk Search?
The inputlookup command is used to search the contents of a Splunk lookup table. The lookup table can be a CSV lookup or a KV store lookup. The inputlookup command is considered to be an event-generating command. An event-generating command generates events or reports from one or more indexes without transforming them. There are many commands that come under the event-generating commands such as metadata, loadjob, inputcsv, etc. The inputlookup command is one of them.
Syntax:
inputlookup [append=] [start=] [max=] [ | ] [WHERE ]
Now coming to the outputlookup command, it writes the search results to a static lookup table, or KV store collection, that we specify. The outputlookup command is not being used with external lookups.
Syntax:
outputlookup [append=<bool>] [create_empty=<bool>] [max=<int>] [key_field=<field_name>] [createinapp=<bool>] [override_if_empty=<bool>] (<filename> | <tablename>)
49. Explain how Splunk works?
We can divide the working of Splunk into three main parts:
Forwarder: You can see it as a dumb agent whose main task is to collect the data from various sources like remote machines and transfer it to the indexer.
Indexer: The indexer will then process the data in real-time and store & index it on the localhost or cloud server.
Search Head: It allows the end-user to interact with the data and perform various operations like searching, analyzing, and visualizing the information.
50. How to add the colors in Splunk UI based on the field names?
Splunk UI has a number of features that allow the administrator to make the reports more presentable. One such feature that proves to be very useful for presenting distinguished results is the custom colors. For example, if the sales of a product drop below a threshold value, then as an administrator you can set the chart to display the values in red color.
The administrator can also change chart colors in the Splunk Web UI by editing the panels from the panel settings mentioned above the dashboard. Moreover, you can write the codes and use hexadecimal values to choose a color from the palette.
Video Reference:-

- DevOps Certified Professionals (DCP)
- Site Reliability Engineering Certified Professionals (SRECP)
- Master in DevOps Engineering (MDE)
- DevSecOps Certified Professionals (DSOCP)
URL - https://www.devopsschool.com/certification/
My Linkedin - https://www.linkedin.com/in/rajeshkumarin
- Installing Jupyter: Get up and running on your computer - November 2, 2024
- An Introduction of SymOps by SymOps.com - October 30, 2024
- Introduction to System Operations (SymOps) - October 30, 2024
