A machine learning algorithm is a set of rules or procedures that a computer follows to learn from data. It’s the underlying mechanism that builds the model.
Machine Learning (ML) is at the heart of many modern technologies, driving advancements in fields like natural language processing, computer vision, and predictive analytics. Central to the power of ML are the algorithms—the mathematical frameworks and techniques that allow machines to learn from data, identify patterns, and make decisions. This blog provides a detailed exploration of various machine learning algorithms, covering their types, how they work, their applications, and when to use them.
What are Machine Learning Algorithms?
Machine learning algorithms are a set of rules and statistical techniques used to perform a specific task by learning from data. These algorithms are designed to identify patterns, relationships, or trends within a dataset and use this information to make predictions, classifications, or decisions. They are the building blocks of machine learning models.
Types of Machine Learning Algorithms
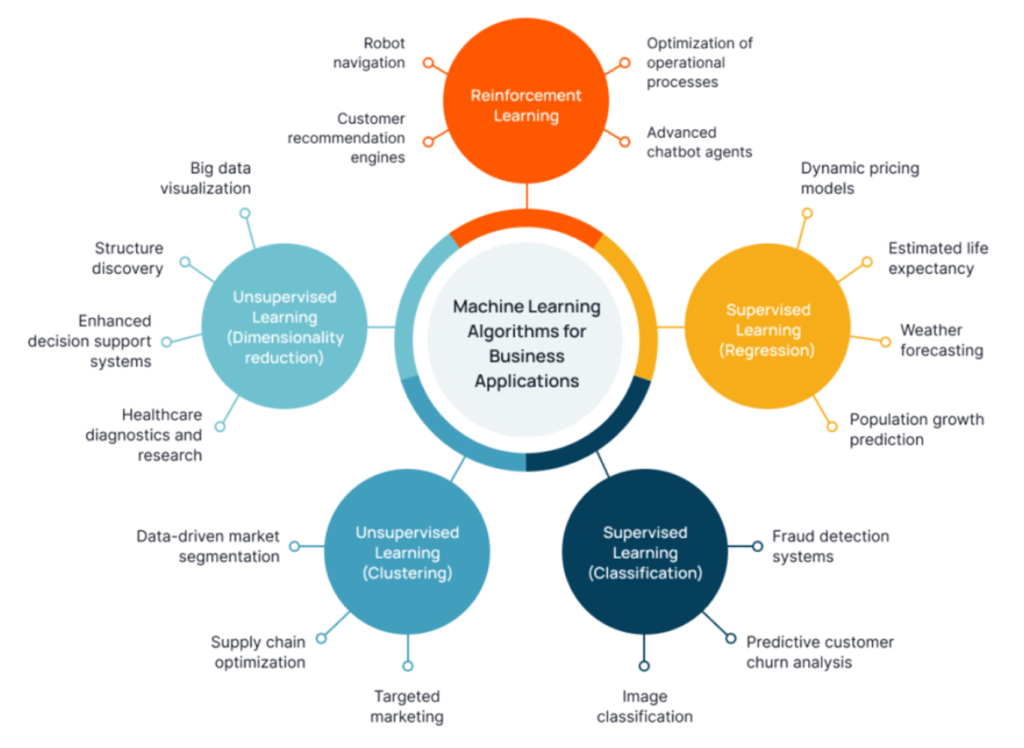
Machine learning algorithms can be broadly categorized into three types based on the nature of the task they are designed to perform:
- Supervised Learning Algorithms
- Unsupervised Learning Algorithms
- Reinforcement Learning Algorithms
Here is a tabular representation of the key algorithms used in machine learning, categorized by their type (Supervised Learning, Unsupervised Learning, and Reinforcement Learning):

| Type of Learning | Algorithm | Description | Common Applications |
|---|---|---|---|
| Supervised Learning | Linear Regression | Models the relationship between a dependent variable and one or more independent variables using a linear equation. | Predicting house prices, sales forecasting, risk assessment |
| Logistic Regression | Used for binary classification; predicts the probability of an instance belonging to a particular class using a logistic curve. | Spam detection, credit scoring, disease diagnosis | |
| Decision Trees | Splits data into subsets based on feature values, creating a tree-like structure of decisions and outcomes. | Customer segmentation, fraud detection, loan approval | |
| Support Vector Machines (SVM) | Finds the optimal hyperplane that best separates different classes in the feature space. | Image classification, text categorization, bioinformatics | |
| k-Nearest Neighbors (k-NN) | Classifies data points based on the majority vote of their k-nearest neighbors in the feature space. | Recommender systems, anomaly detection, stock market prediction | |
| Random Forest | An ensemble method that builds multiple decision trees and merges their predictions to improve accuracy and reduce overfitting. | Diagnosing diseases, predicting customer churn, classification of emails | |
| Neural Networks | Computational models inspired by the human brain, consisting of interconnected layers of neurons that process data hierarchically. | Image and speech recognition, natural language processing, self-driving cars | |
| Gradient Boosting Machines | Sequentially builds trees, each one correcting the errors of its predecessor, to create a strong learner from weak learners. | Ranking, classification, and regression tasks, including credit scoring and marketing | |
| Naive Bayes | A probabilistic classifier based on Bayes’ theorem with strong independence assumptions between the features. | Text classification, spam filtering, sentiment analysis | |
| AdaBoost | Combines weak learners to create a strong classifier, focusing more on hard-to-classify cases. | Image detection, text classification, customer churn prediction | |
| XGBoost | An optimized implementation of gradient boosting with a focus on speed and performance. | Structured data tasks, such as fraud detection and churn prediction | |
| Unsupervised Learning | k-Means Clustering | Partitions the data into k distinct clusters based on similarity, with each data point assigned to the nearest cluster center (mean). | Market segmentation, document clustering, image compression |
| Hierarchical Clustering | Builds a tree of clusters by either merging smaller clusters into larger ones (agglomerative) or splitting larger clusters into smaller ones (divisive). | Gene expression data analysis, customer segmentation, social network analysis | |
| Principal Component Analysis (PCA) | Reduces the dimensionality of a dataset by transforming it into a set of linearly uncorrelated variables called principal components. | Image compression, exploratory data analysis, noise reduction | |
| t-Distributed Stochastic Neighbor Embedding (t-SNE) | A technique for visualizing high-dimensional data by reducing it to two or three dimensions while preserving local structure. | Visualizing complex datasets, exploring high-dimensional data, understanding model predictions | |
| Autoencoders | Neural networks that learn efficient representations of data, typically for dimensionality reduction or feature learning. | Data denoising, anomaly detection, feature extraction | |
| Apriori Algorithm | Used to find frequent itemsets and generate association rules in large datasets, often used in market basket analysis. | Recommender systems, market basket analysis, inventory management | |
| Gaussian Mixture Models (GMM) | Models data as a mixture of multiple Gaussian distributions, used for clustering by assuming that each cluster follows a Gaussian distribution. | Density estimation, anomaly detection, image segmentation | |
| DBSCAN (Density-Based Spatial Clustering of Applications with Noise) | A clustering algorithm that groups together closely packed points and marks outliers in low-density regions. | Geospatial data analysis, anomaly detection, cluster analysis in noisy data | |
| Latent Dirichlet Allocation (LDA) | A generative statistical model that explains observations by identifying a small number of unobserved groups (topics) that describe the data. | Topic modeling in text mining, document classification, feature extraction | |
| Reinforcement Learning | Q-Learning | A model-free, off-policy algorithm that seeks to learn the optimal action-selection policy by learning the value of actions in a given state. | Game playing, robotics, autonomous vehicles |
| Deep Q-Networks (DQN) | Combines Q-Learning with deep learning, allowing an agent to learn optimal policies directly from high-dimensional inputs like images. | Video games, robotics, real-time decision making | |
| SARSA (State-Action-Reward-State-Action) | An on-policy algorithm that updates the Q-values based on the action actually taken by the agent, rather than the optimal action. | Online learning environments, real-time decision making | |
| Policy Gradient Methods | Optimizes the policy directly by maximizing the expected reward, making them suitable for environments with continuous action spaces. | Robotics control, game playing, continuous action spaces | |
| Actor-Critic Methods | Combines the benefits of value-based and policy-based approaches by having two components: the actor, which updates the policy, and the critic, which evaluates the action. | Autonomous driving, resource management, robotic manipulation | |
| Proximal Policy Optimization (PPO) | A policy gradient method that improves training stability by limiting the change in policy update through a clipped objective function. | Robotics, game AI, resource management | |
| Monte Carlo Methods | A class of algorithms that rely on repeated random sampling to compute their results, used in situations where modeling all possible outcomes is infeasible. | Financial modeling, risk assessment, stochastic optimization |

Let’s dive into each of these categories.
1. Supervised Learning Algorithms
Supervised Learning algorithms are used when the model is trained on a labeled dataset, which means the input data is paired with the correct output. The goal is to learn a mapping from inputs to outputs so that the model can predict the output for new, unseen data.
Common Supervised Learning Algorithms:
- Linear Regression
- Type: Regression
- Description: Linear regression models the relationship between a dependent variable and one or more independent variables using a linear equation. It’s used for predicting continuous outcomes.
- Applications: Predicting house prices, sales forecasting, risk assessment.
- Logistic Regression
- Type: Classification
- Description: Despite its name, logistic regression is used for binary classification tasks. It predicts the probability of an instance belonging to a particular class by fitting data to a logistic curve.
- Applications: Spam detection, credit scoring, disease diagnosis.
- Decision Trees
- Type: Classification and Regression
- Description: Decision trees split the data into subsets based on feature values, creating a tree-like structure where each branch represents a decision rule and each leaf represents an outcome.
- Applications: Customer segmentation, fraud detection, loan approval.
- Support Vector Machines (SVM)
- Type: Classification
- Description: SVMs find the hyperplane that best separates different classes in the feature space. It’s effective in high-dimensional spaces and with clear margin separation.
- Applications: Image classification, text categorization, bioinformatics.
- k-Nearest Neighbors (k-NN)
- Type: Classification and Regression
- Description: k-NN is a simple algorithm that classifies data points based on the majority vote of their k-nearest neighbors in the feature space. It’s also used for regression by averaging the values of the k-nearest neighbors.
- Applications: Recommender systems, anomaly detection, stock market prediction.
- Random Forest
- Type: Classification and Regression
- Description: Random Forest is an ensemble method that builds multiple decision trees and merges their predictions to improve accuracy and reduce overfitting.
- Applications: Diagnosing diseases, predicting customer churn, classification of emails.
- Neural Networks
- Type: Classification and Regression
- Description: Neural Networks are computational models inspired by the human brain, consisting of interconnected layers of neurons that process data in a hierarchical manner. They are particularly powerful for complex pattern recognition tasks.
- Applications: Image and speech recognition, natural language processing, self-driving cars.
2. Unsupervised Learning Algorithms
Unsupervised Learning algorithms are used when the model is trained on data that is not labeled. The goal is to discover the underlying structure of the data, such as grouping similar items together or reducing the dimensionality of the data.
Common Unsupervised Learning Algorithms:
- k-Means Clustering
- Type: Clustering
- Description: k-Means clustering partitions the data into k distinct clusters based on similarity. Each data point belongs to the cluster with the nearest mean.
- Applications: Market segmentation, document clustering, image compression.
- Hierarchical Clustering
- Type: Clustering
- Description: Hierarchical clustering builds a tree of clusters by either merging smaller clusters into larger ones (agglomerative) or splitting larger clusters into smaller ones (divisive).
- Applications: Gene expression data analysis, customer segmentation, social network analysis.
- Principal Component Analysis (PCA)
- Type: Dimensionality Reduction
- Description: PCA reduces the dimensionality of a dataset by transforming it into a set of linearly uncorrelated variables called principal components. It’s used for simplifying data while retaining as much variability as possible.
- Applications: Image compression, exploratory data analysis, noise reduction.
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Type: Dimensionality Reduction
- Description: t-SNE is a technique for visualizing high-dimensional data by reducing it to two or three dimensions. It’s particularly useful for visualizing clusters.
- Applications: Visualizing complex datasets, exploring high-dimensional data, understanding model predictions.
- Autoencoders
- Type: Dimensionality Reduction
- Description: Autoencoders are a type of neural network used to learn efficient representations of data, typically for the purpose of dimensionality reduction or feature learning.
- Applications: Data denoising, anomaly detection, feature extraction.
- Apriori Algorithm
- Type: Association Rule Learning
- Description: The Apriori algorithm is used to find frequent itemsets and generate association rules in large datasets. It’s commonly used in market basket analysis.
- Applications: Recommender systems, market basket analysis, inventory management.
3. Reinforcement Learning Algorithms
Reinforcement Learning algorithms are used when an agent interacts with an environment and learns to make decisions by receiving rewards or penalties. The goal is to learn a policy that maximizes cumulative rewards over time.
Common Reinforcement Learning Algorithms:
- Q-Learning
- Type: Model-Free, Off-Policy
- Description: Q-Learning is a value-based reinforcement learning algorithm that seeks to find the optimal action-selection policy by learning the value of actions in a given state.
- Applications: Game playing, robotics, autonomous vehicles.
- Deep Q-Networks (DQN)
- Type: Model-Free, Off-Policy
- Description: DQNs combine Q-Learning with deep learning, allowing the agent to learn optimal policies directly from high-dimensional inputs like images.
- Applications: Video games, robotics, real-time decision making.
- SARSA (State-Action-Reward-State-Action)
- Type: Model-Free, On-Policy
- Description: SARSA is an on-policy algorithm that updates the Q-values based on the action actually taken by the agent, rather than the optimal action.
- Applications: Online learning environments, real-time decision making.
- Policy Gradient Methods
- Type: Model-Free, On-Policy
- Description: Policy Gradient methods optimize the policy directly by maximizing the expected reward, making them suitable for environments with continuous action spaces.
- Applications: Robotics control, game playing, continuous action spaces.
- Actor-Critic Methods
- Type: Model-Free, On-Policy or Off-Policy
- Description: Actor-Critic methods combine the benefits of value-based and policy-based approaches by having two components: the actor, which updates the policy, and the critic, which evaluates the action.
- Applications: Autonomous driving, resource management, robotic manipulation.
Choosing the Right Algorithm
The choice of algorithm depends on several factors, including the nature of the problem, the type of data available, and the specific requirements of the task. Here are some general guidelines:
- Supervised Learning: Use supervised learning algorithms when you have labeled data and the goal is to predict an outcome or classify data into categories.
- Unsupervised Learning: Use unsupervised learning algorithms when you need to find patterns or structure in unlabeled data, such as clustering similar items or reducing the dimensionality of the data.
- Reinforcement Learning: Use reinforcement learning when the problem involves sequential decision-making in an environment where actions have consequences over time.
Conclusion
Machine learning algorithms are the engines that drive the predictive power of models. Understanding the different types of algorithms and their applications is crucial for building effective machine learning systems. Whether you’re working on a classification problem with supervised learning, exploring data with unsupervised learning, or developing intelligent agents with reinforcement learning, selecting the right algorithm is key to achieving your goals. By mastering these algorithms, you can unlock the full potential of machine learning in solving complex problems across various domains.

- DevOps Certified Professionals (DCP)
- Site Reliability Engineering Certified Professionals (SRECP)
- Master in DevOps Engineering (MDE)
- DevSecOps Certified Professionals (DSOCP)
URL - https://www.devopsschool.com/certification/
My Linkedin - https://www.linkedin.com/in/rajeshkumarin
- Best AI tools for Software Engineers - November 4, 2024
- Installing Jupyter: Get up and running on your computer - November 2, 2024
- An Introduction of SymOps by SymOps.com - October 30, 2024
