
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comMachine Learning (ML) is an expansive field within Artificial Intelligence (AI) that empowers computers to learn from data and make decisions with minimal human intervention. Among its various branches, Unsupervised Learning plays a crucial role in uncovering hidden patterns and structures within data that lack explicit labels. This blog provides a detailed exploration of Unsupervised Learning, covering its fundamental concepts, key algorithms, practical applications, and how to get started with implementing these techniques.
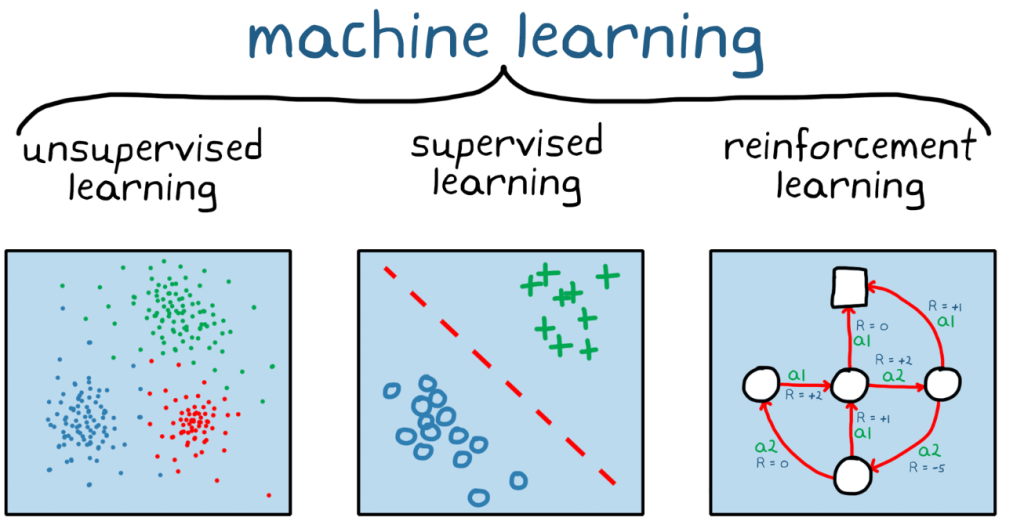
What is Unsupervised Learning?
Unsupervised Learning is a subset of Machine Learning where the model is trained on a dataset without labeled responses. Unlike Supervised Learning, where the model is guided by labeled input-output pairs, Unsupervised Learning involves discovering patterns, groupings, or structures within the data. The goal is to find the underlying structure of the data, be it through grouping similar data points, reducing dimensionality, or identifying outliers.
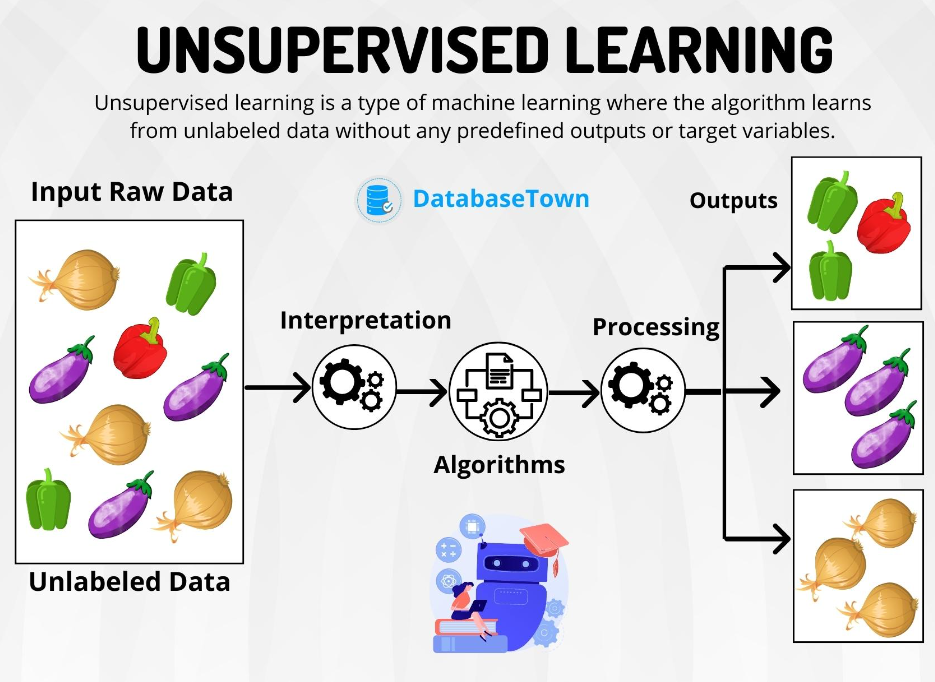
Unsupervised Learning is particularly useful when the dataset lacks labels or when manual labeling is too time-consuming, expensive, or impractical. It is commonly used for exploratory data analysis, feature discovery, and generating insights from data.
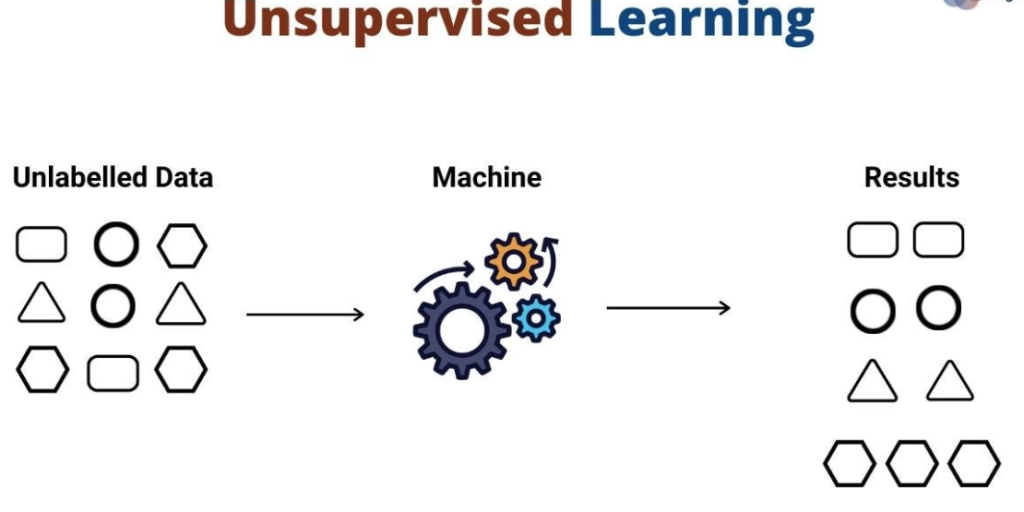
Key Concepts in Unsupervised Learning
1. Clustering
- Clustering is the process of grouping similar data points together based on their features. The idea is to ensure that points within the same group (cluster) are more similar to each other than to those in other groups. Clustering is one of the most widely used techniques in Unsupervised Learning.
2. Dimensionality Reduction
- Dimensionality Reduction involves reducing the number of features (dimensions) in a dataset while preserving as much information as possible. This technique is crucial for visualizing high-dimensional data and reducing computational complexity.
3. Anomaly Detection
- Anomaly Detection is the process of identifying rare items, events, or observations that do not conform to the general pattern of the data. These anomalies are often of interest because they may represent critical incidents, such as fraud or malfunction.
4. Association Rules
- Association Rules are used to discover relationships between variables in large datasets. This technique is often used in market basket analysis to identify items that frequently co-occur in transactions.
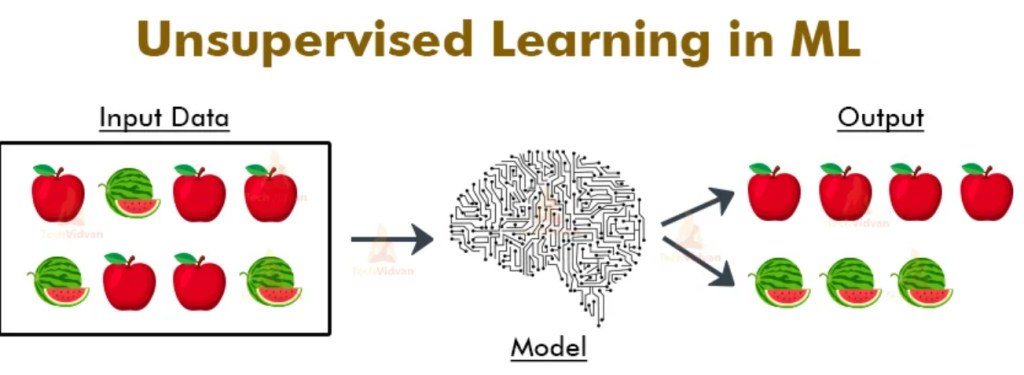
Common Algorithms in Unsupervised Learning
Several algorithms can be employed in Unsupervised Learning, each tailored to different types of tasks and data structures. Below are some of the most commonly used algorithms:
1. k-Means Clustering
- Type: Clustering
- Description: k-Means is one of the most popular clustering algorithms. It partitions the data into k clusters by minimizing the sum of squared distances between data points and the centroid of their assigned cluster.
- Use Case: Customer segmentation, where customers are grouped based on their purchasing behavior.
2. Hierarchical Clustering
- Type: Clustering
- Description: Hierarchical Clustering builds nested clusters by either merging smaller clusters into larger ones (agglomerative) or splitting larger clusters into smaller ones (divisive). The results are often represented in a dendrogram, a tree-like diagram.
- Use Case: Gene expression data analysis, where genes with similar expression patterns are grouped together.
3. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Type: Clustering
- Description: DBSCAN groups together points that are closely packed based on a distance metric and identifies points in low-density regions as outliers. Unlike k-Means, DBSCAN does not require specifying the number of clusters beforehand.
- Use Case: Identifying geographical clusters of disease outbreaks.
4. Principal Component Analysis (PCA)
- Type: Dimensionality Reduction
- Description: PCA reduces the dimensionality of a dataset by transforming it into a set of linearly uncorrelated variables called principal components. These components capture the most variance in the data.
- Use Case: Reducing the number of features in image compression while retaining essential information.
5. t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Type: Dimensionality Reduction
- Description: t-SNE is a non-linear dimensionality reduction technique that is particularly useful for visualizing high-dimensional datasets in 2D or 3D. It preserves the local structure of the data, making it ideal for visualizing clusters.
- Use Case: Visualizing clusters in high-dimensional datasets, such as word embeddings in natural language processing.
6. Autoencoders
- Type: Dimensionality Reduction
- Description: Autoencoders are neural networks that learn to compress data into a lower-dimensional representation and then reconstruct the original data from this compressed form. They are used for tasks like noise reduction and anomaly detection.
- Use Case: Image denoising, where the goal is to remove noise from images while preserving essential details.
7. Apriori Algorithm
- Type: Association Rules
- Description: The Apriori Algorithm is used to find frequent itemsets in transactional data and to generate association rules. It is based on the principle that any subset of a frequent itemset must also be frequent.
- Use Case: Market basket analysis, where the goal is to identify products frequently purchased together.
How to Implement Unsupervised Learning: A Step-by-Step Guide
Implementing Unsupervised Learning involves several steps, from data preparation to model evaluation. Here’s a basic outline:
1. Data Collection
- Gather data relevant to the problem you want to solve. The data should be comprehensive enough to reveal patterns and structures.
2. Data Preprocessing
- Cleaning: Handle missing values, remove duplicates, and address inconsistencies in the data.
- Normalization/Standardization: Scale features so that they contribute equally to the model’s predictions, especially in clustering tasks.
- Dimensionality Reduction: If dealing with high-dimensional data, consider applying PCA or another dimensionality reduction technique to simplify the data.
3. Choosing a Model
- Select an appropriate algorithm based on the problem type (clustering, dimensionality reduction, or association) and the characteristics of your data.
4. Training the Model
- Apply the chosen algorithm to the dataset. In Unsupervised Learning, “training” often involves identifying clusters, reducing dimensions, or discovering associations rather than optimizing a predictive model.
5. Evaluating the Model
- Silhouette Score: Used to evaluate the quality of clusters by measuring how similar a point is to its own cluster compared to other clusters.
- Explained Variance: In PCA, measures the proportion of the dataset’s variance captured by the principal components.
- Visual Inspection: Techniques like t-SNE often require visual inspection to assess the quality of the clusters or the data projection.
6. Interpreting Results
- Analyze the patterns, clusters, or associations discovered by the model. These insights can guide further analysis or decision-making.
7. Deploying the Model
- Once satisfied with the model’s results, deploy it to identify patterns, clusters, or anomalies in new data.
Applications of Unsupervised Learning
Unsupervised Learning is used in a variety of industries and domains:
- Marketing: Customer segmentation, targeted marketing, and identifying customer personas.
- Finance: Fraud detection, risk assessment, and market segmentation.
- Healthcare: Disease outbreak detection, patient clustering for personalized treatment, and gene expression analysis.
- Retail: Market basket analysis, inventory management, and product recommendation systems.
- Social Media: Topic modeling, sentiment analysis, and user clustering.
Challenges in Unsupervised Learning
Despite its potential, Unsupervised Learning comes with its own set of challenges:
- Interpretability: The results of Unsupervised Learning can be difficult to interpret, especially in high-dimensional spaces.
- Evaluation: Unlike Supervised Learning, there is no straightforward way to evaluate the performance of an Unsupervised Learning model, as there are no labels to compare against.
- Scalability: Some algorithms, like hierarchical clustering, struggle to scale to very large datasets.
- Choosing the Right Number of Clusters: In clustering, determining the optimal number of clusters can be challenging and often requires domain knowledge or heuristic methods.
Conclusion
Unsupervised Learning is a powerful tool for discovering hidden patterns, reducing the complexity of data, and gaining insights that would be difficult to obtain through manual analysis. By understanding the fundamental concepts, key algorithms, and best practices, you can harness the power of Unsupervised Learning to solve real-world problems effectively. As you explore the field, remember that the quality of your data, the choice of algorithms, and careful evaluation are all critical components of successful Unsupervised Learning. With continued learning and practice, you can master the art of Unsupervised Learning and contribute to the rapidly advancing field of Artificial Intelligence.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
