
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comDataOps
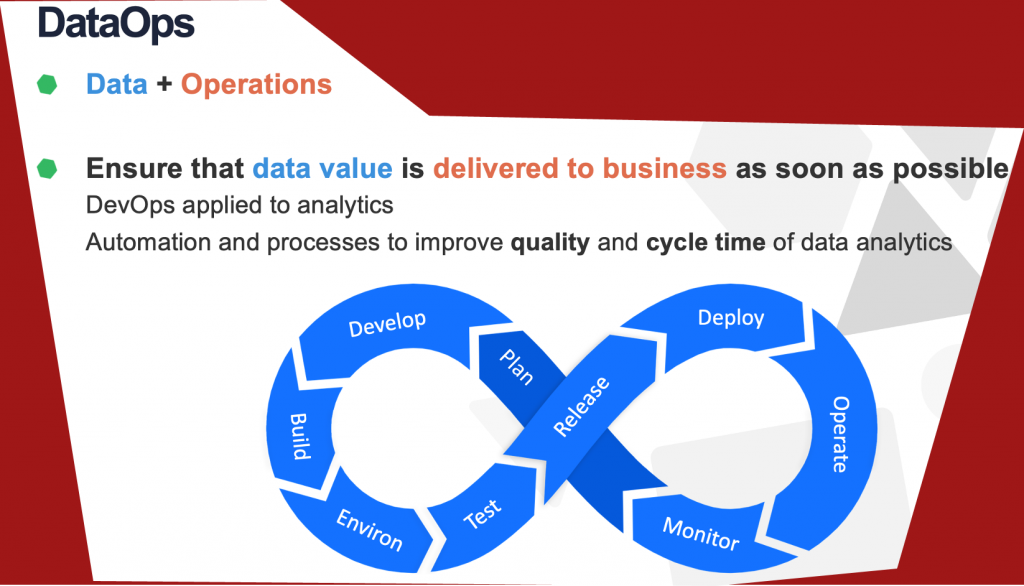
According to Gartner, DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization.
DataOps was introduced by Lenny Liebmann
The term DataOps was made famous by “Andy Palmer of Tamr and Steph Locke‘.
Advantage & Disadvantage of DataOps
Advantages
- End-to-end Efficiency –
The convergence of point-solution products into end-to-end platforms has made DataOps possible. Agile software that manages, rule, curates, and provisions data over the entire supply chain allows efficiencies, detailed lineage, collaboration, and data virtualization, to name a few benefits. While many point-solutions will continue, Today success comes from having a layer of abstraction that interacts and optimizes every stage of the data lifecycle, into vendors and clouds, to streamline and protect the full ecosystem.
- Analytic Collaboration –
As machine-learning and AI applications expand, the successful result of these initiatives depends on expert data curation, which comprise the preparation of the data, automated controls to deduct the risks implicit in data analysis, and collaborative access to as much information as possible. Data collaboration, like other types of collaboration, fosters better insights, new ideas, and overcomes analytic problems. While often considered a downstream discipline, providing collaboration features over data discovery, augmented data management, and provisioning results in better AI/ML results. In our COVID-19 age, collaboration has become even more important, and the best of today’s DataOps platforms offer benefits that break down the barriers of remote work, departmental divisions, and competing business goals.
Automated Data Quality In June of 2020, Gartner found that 55% of companies lack a standardized approach to governance. As ecosystems become more complex, data increasingly is exposed to a variety of data storage, compute, and analytic environments. Each touchpoint introduces security risks and the most effective way to reduce this risk is to establish automated data governance rules and workflows within a zone-based system that are applied across the entire supply chain. Modern DataOps platforms offer automated, customizable data quality, tokenization, masking, and other controls, across vendors and technologies, so that data is protected and compliance can be verified at every step of the journey.
- Self-service Data Marketplace –
May be no DataOps benefits offers more advantages to efficiency, cost savings and AI enablement than self-service data marketplaces. Modern DataOps platforms are offering a shopping cart experience for all organizations in the catalog, from standard data types to reports, files and other non-tabular formats. These marketplaces allow organizations to be easily found, selected, and provisioned to any destination, such as a repository like Snowflake, to direct integrations with analytics tools, like Tableau. The self-service marketplace dramatically minimizes the IT ticket load, boosts analytic results, and lowers data costs.
- Customizable Metadata –
A data catalog is useful as the narrative details applied to each entity. As repositories increase, analysts encounter challenges finding the exact data source they need when entities are not accompanied by precise labels, tags, and notes. Additionally, creating the ML-based proposal tools and other features to offer data to an analyst is most emphatic when these details are used to feed the models. To achieve data discovery and recommendation success, modern DataOps platforms have assemble customizable metadata fields, tags, and labels, which can be created by pre-permissioned analysts, data scientists, and engineers. Every company has differences in their data, comprising its use, source, or destination, and by bringing customizable fields into the catalog, analysts could use unique tags, labels, and notes to collaborate, easily search specific data sets, and recommend sets to their colleagues.
- Cloud Agnostic Integrations –
As organizations use DataOps improvements to bring data from more sources, types, and formats into lakes and catalogs, their data ecosystems often need to unified with a variety of data warehouses and storage platforms. Data stored with one vendor may be hosted on AWS, while another may be on Azure, and so on. In order to successfully unify data sources, find any entity within the catalog, and provision to the sandbox or destination of their choice, companies need an extensible, single pane of glass DataOps platform that link to every cloud or on-premises source and scales across new technologies over time.
- Extensibility Across Existing Infrastructure –
Extensibility is the root of today’s DataOps platforms. To achieve streamlined, accelerated, optimized data ecosystems, transparency across the entire supply chain is important. The only way to give complete data lineage, standardized enterprise-wide governance, and ML-based workflows and recommendations, is to have a platform that links to every technology and vendor in the data ecosystem. The best DataOps companies are able to take extensibility one step ahead by enabling enterprises to keep what is working in their data architecture and replace only what is necessary. This “stay and play” approach to both data and vendors reduces costs, accelerates timelines, and often overcomes hurdles that have previously blocked data project success.
Modern DataOps success gives data engineers, stewards, analysts and their managers both the bird’s eye view across their connected data ecosystem and the ability to quickly execute on new data products and advanced analytics. A strong DataOps base scales as data use cases arise, making it important for today’s highly data-driven enterprises.
Disadvantages
Done wrong, DataOps can create rigid to share silos of data as business units or departments create their own data hubs in relatively low-cost public cloud platforms without following enterprise standards in areas such as security, compliance or data definitions.
It also needs purchasing, implementing and supporting multiple tools to give everything from version control of code and data to data integration, metadata management, data governance, security and compliance, among other needs. Tools supporting operationalization of analytics and AI pipelines for purposes such as DataOps usually have overlapping capabilities that make it even more difficult to identify the right product and framework for implementation, says Gartner analyst Soyeb Barot in a January 2021 report.
DataOps implementations can also be hobbled by, among things, the over-reliance on fragile extract, transform and load (ETL) pipelines; a reluctance or inability to invest in data governance and management; the continued explosion of data to manage; and integration complexities, according to the Omdia report. For such reasons, Shimmin estimates that fewer than one in five enterprises has successfully implemented DataOps.

Best learning platform for DataOps
DevOpsSchool is the best institute to learn DataOps. It provides live and online classes that is the need in this pendamic to save ourselves. This institute has best IT trainers who are well trained and experienced to provide the training. A experience always share a valuable knowledge that helps in career road path. Pdf’s, slides videos so many things are there that is given by this institute. This institute is linked with so many IT companies. There are so many IT companies that is client of this institute that has got trained their employees from DevOpsSchool.
Reference
- What is DevOps?
- DataOps Certifications
- DataOps Consultants
- DataOps Consulting Company
- Best DataOps Courses
- Best DataOps Tools
- Best DataOps Trainer
- Best DataOps Training
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
