 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com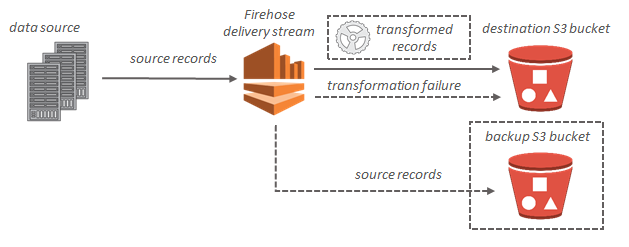
In an era where data is the new oil, the ability to capture and process streaming data efficiently has become critical for businesses. Whether it’s website activity logs, IoT sensor data, application events, or financial transactions, real-time insights are crucial for staying competitive. This is where Amazon Kinesis Data Firehose comes into play.
Amazon Kinesis Data Firehose (commonly referred to as Data Firehose) is a fully managed service designed to ingest, transform, and deliver streaming data to destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch Service, and third-party tools.
Let’s explore this powerful service in depth.
 What is Amazon Data Firehose?
What is Amazon Data Firehose?
Amazon Data Firehose is a fully managed, real-time data delivery service that allows users to automatically capture streaming data and send it to various storage and analytics destinations — without the need to write complex data-processing applications.
Unlike traditional data pipelines that require intermediate processing layers or batching, Data Firehose takes raw, real-time data and pipes it directly into target systems. It can optionally transform or compress the data before delivery, making it ideal for building data lakes, analytics dashboards, or operational monitoring systems.
It is a core component of AWS’s streaming data services under the Kinesis family, with the specific goal of simplifying streaming data ingestion and delivery.
 Why is Amazon Data Firehose Used?
Why is Amazon Data Firehose Used?
Amazon Data Firehose is used in scenarios where companies need to:
- Continuously ingest high-velocity data from distributed sources
- Minimize latency between data generation and storage/analytics
- Eliminate operational overhead related to managing streaming infrastructure
- Deliver data directly to data lakes, data warehouses, or visualization tools
- Simplify ETL pipelines using built-in transformations
With growing needs for real-time analysis and automation, businesses increasingly move from periodic batch processing to continuous data streaming, and Data Firehose offers a plug-and-play way to do that without managing any servers or workers.
 How Does Amazon Data Firehose Work?
How Does Amazon Data Firehose Work?
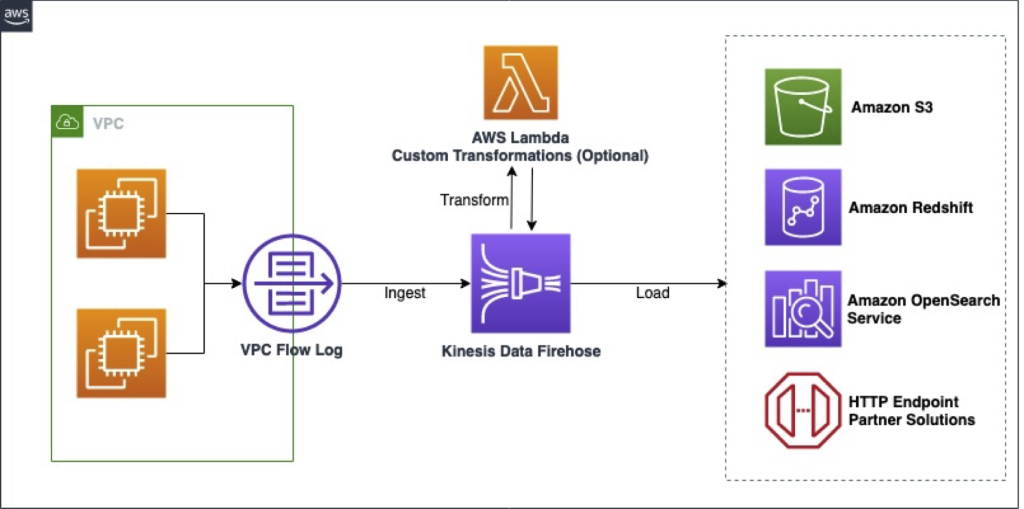
The working of Amazon Data Firehose can be visualized as a pipeline with four main stages:
- Data Ingestion
- Data is sent to Firehose from a source (e.g., application, server, IoT device).
- Producers can use AWS SDKs, Kinesis Agent, CloudWatch Logs, or direct API calls.
- Optional Data Transformation
- Firehose can transform data using AWS Lambda.
- For example, JSON to Parquet conversion, schema normalization, or filtering sensitive data.
- Buffering and Batching
- Firehose temporarily buffers data in memory.
- You can configure buffer size (MB) or buffer interval (seconds), whichever comes first.
- This reduces the number of write operations to your destination and improves efficiency.
- Delivery to Destination
- Firehose writes the data to the chosen destination: Amazon S3, Redshift, OpenSearch, or a custom endpoint.
- Data can be stored in various formats and optionally compressed using GZIP, Snappy, or ZIP.
Firehose abstracts away all the complexities, making streaming data pipelines easy to deploy even for non-expert teams.
 Key Features of Amazon Data Firehose
Key Features of Amazon Data Firehose
- Fully Managed: No need to provision, scale, or maintain infrastructure.
- Real-Time Delivery: Supports low-latency delivery to multiple destinations.
- Multiple Destinations: Delivers data to S3, Redshift, OpenSearch, or HTTP endpoints.
- Data Transformation: Uses AWS Lambda for real-time record-level transformation.
- Format Conversion: Automatically converts JSON to Parquet/ORC for efficient storage.
- Compression: Supports GZIP, Snappy, and ZIP to reduce storage costs.
- Dynamic Partitioning: Automatically partitions data in S3 using keys like timestamps or values.
- Retry and Error Handling: Automatically retries failed records and can log them to S3.
- Monitoring and Logging: Integrated with CloudWatch for metrics and error logs.
- VPC Integration: Secure data transfer within private networks using VPC endpoints.
These features make Firehose highly suited for both simple and enterprise-grade use cases.
 Main Components of Amazon Data Firehose
Main Components of Amazon Data Firehose
Firehose architecture includes the following components:
1. Data Producers
These are the sources that push data into Firehose. Examples:
- Web/mobile applications
- IoT sensors
- EC2 instances
- AWS services like CloudWatch or Lambda
2. Delivery Streams
The core entity in Firehose. Each stream defines:
- The target destination (S3, Redshift, etc.)
- Buffering and transformation settings
- Data format and compression options
3. Data Transformation (Optional)
An AWS Lambda function can be used to clean or modify incoming data before delivery.
4. Destinations
Supported destinations include:
- Amazon S3 (for raw storage or data lakes)
- Amazon Redshift (for structured analytics)
- Amazon OpenSearch Service (for full-text search)
- HTTP endpoints (for custom third-party tools)
5. Error Logging
Firehose stores failed records in an S3 bucket for later inspection and retrying.
 When Should You Use Amazon Data Firehose?
When Should You Use Amazon Data Firehose?
You should consider using Amazon Data Firehose if:
- Your application generates real-time data (e.g., logs, events, telemetry).
- You want a simple way to deliver data to storage or analytics platforms.
- You don’t want to manage a custom Kafka or Flink infrastructure.
- You want automatic partitioning, transformation, or format conversion on the fly.
- You are building a serverless architecture.
- You need to ingest large volumes of streaming data at scale with minimal effort.
In essence, Firehose is best for “data in → transform → destination” flows without complex stream manipulation logic.
 Benefits of Using Amazon Data Firehose
Benefits of Using Amazon Data Firehose
- Simplicity: Firehose eliminates the complexity of building streaming pipelines.
- Cost-Effective: No servers to run, and you only pay for the data volume processed.
- Integration-Ready: Works seamlessly with other AWS services and many external tools.
- Reliable Delivery: Built-in retry mechanisms ensure that data reaches the target.
- Security: Encryption (KMS), IAM roles, and VPC support ensure secure data transfer.
- Elastic Scaling: Automatically adjusts to match your data throughput.
- Format and Compression Handling: Reduces storage costs and boosts query performance.
 Limitations or Challenges of Amazon Data Firehose
Limitations or Challenges of Amazon Data Firehose
Even though Firehose is powerful, it has some limitations:
- Lack of Custom Stream Processing Logic: If you need to aggregate or join data streams, Firehose may not be sufficient — you might need Kinesis Data Analytics or Apache Flink.
- Latency: Although it’s near real-time, data delivery can be delayed up to 60 seconds based on buffering configurations.
- Transformation Complexity: Advanced transformations must be handled in Lambda, which adds complexity.
- Data Loss Possibility: Under heavy load or transformation failures, some data may be dropped unless error logging is enabled.
- Limited Destination Options: You can’t stream directly into some analytics tools unless routed through an intermediate storage service.
Understanding these limitations helps in choosing the right service or using Firehose in combination with others.
 How to Get Started with Amazon Data Firehose
How to Get Started with Amazon Data Firehose
Step 1: Create a Delivery Stream
- Choose your destination (e.g., S3 or Redshift).
- Define buffer settings, transformation options, and destination configurations.
Step 2: Configure Permissions
- Assign the IAM role Firehose will use to access S3, Lambda, and other services.
Step 3: Send Data
- Use AWS SDK, CLI, Kinesis Agent, or configure CloudWatch Logs to send data.
Step 4: (Optional) Add Data Transformation
- Attach a Lambda function to transform records before delivery.
Step 5: Monitor and Debug
- Use CloudWatch to monitor delivery stream metrics.
- Enable error logging to inspect failed data records.
This setup allows you to be up and running with a robust streaming pipeline in minutes.
 Alternatives to Amazon Data Firehose
Alternatives to Amazon Data Firehose
There are several tools and services that provide similar capabilities, either within or outside the AWS ecosystem:
| Alternative | Description |
|---|---|
| Apache Kafka | Open-source distributed streaming platform with high flexibility. Requires infrastructure management. |
| Amazon Kinesis Data Streams | For use cases needing more control, custom processing, or multiple consumer applications. |
| Google Cloud Dataflow / PubSub | Real-time data processing and delivery tools on Google Cloud. |
| Azure Event Hubs | Scalable real-time data ingestion for Microsoft Azure environments. |
| Confluent Cloud | Fully managed Kafka platform with enhanced enterprise features. |
Choosing between Firehose and alternatives depends on your technical needs, team expertise, and cloud strategy.
 Real-World Use Cases and Success Stories
Real-World Use Cases and Success Stories
1. E-commerce
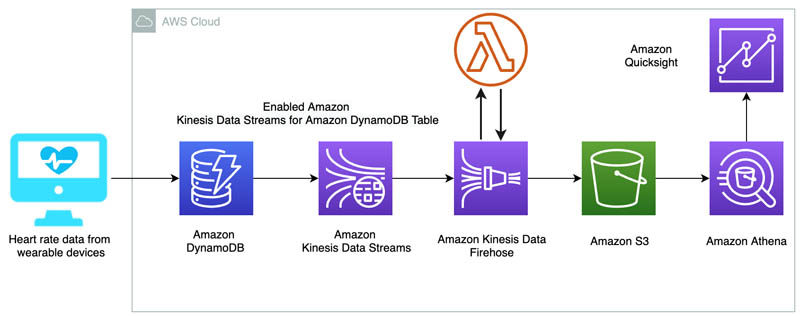
A large e-commerce company uses Firehose to ingest website clickstream data and send it to Amazon S3 in Parquet format. The data is then queried using Athena for customer behavior analysis.
2. IoT Devices
An industrial company deploys thousands of IoT sensors in its manufacturing units. Data is streamed via Firehose to a data lake, where real-time dashboards help detect anomalies.
3. Mobile App Monitoring
A popular mobile game collects user interaction data and logs. These logs are sent to Firehose and stored in S3. AWS Glue catalogs this data for deeper analysis.
4. Financial Services
Banks stream transaction data to Redshift through Firehose, enabling real-time fraud detection models to flag unusual behavior instantly.
5. Healthcare
Health-tech companies send telemetry from medical devices into Firehose, allowing real-time alerts for doctors and analytics on patient trends.
These examples show how companies in various industries leverage Firehose to modernize data workflows and make faster decisions.
 Conclusion
Conclusion
Amazon Kinesis Data Firehose is a game-changer for modern data architectures. It offers a simple, reliable, and scalable way to handle streaming data without managing infrastructure. Whether you’re just starting your real-time data journey or building large-scale data lakes and ML pipelines, Firehose can be a cornerstone of your solution.
Its ease of use, seamless integration with AWS, and rich features make it ideal for data engineers, developers, and even small teams looking to unlock real-time analytics with minimal overhead.
If your goal is to streamline streaming data, Firehose delivers — literally and figuratively.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
