
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com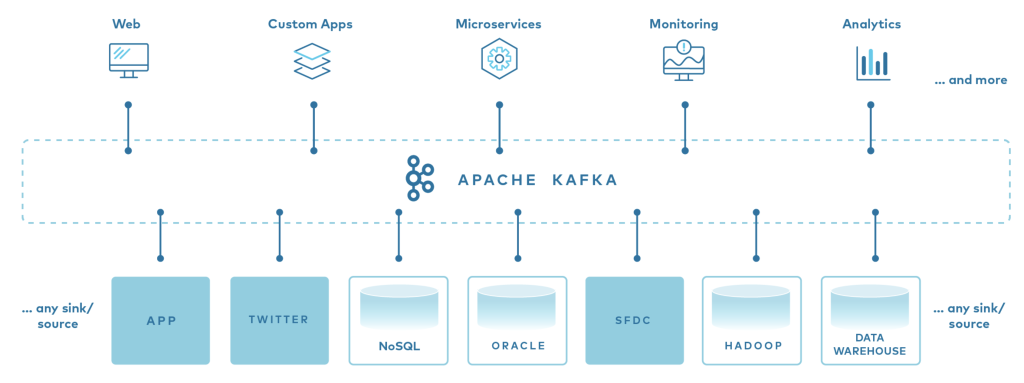
1. Introduction
In today’s data-driven world, real-time processing of large-scale streams of data has become critical. Apache Kafka, an open-source distributed event streaming platform, has emerged as one of the most popular solutions for building scalable, fault-tolerant, and high-throughput systems.
Kafka was originally developed by LinkedIn and later open-sourced as an Apache project. It serves as a backbone for data integration and event streaming architectures. This guide explores Kafka from the ground up—from its definition and use cases to its underlying architecture and workflow.
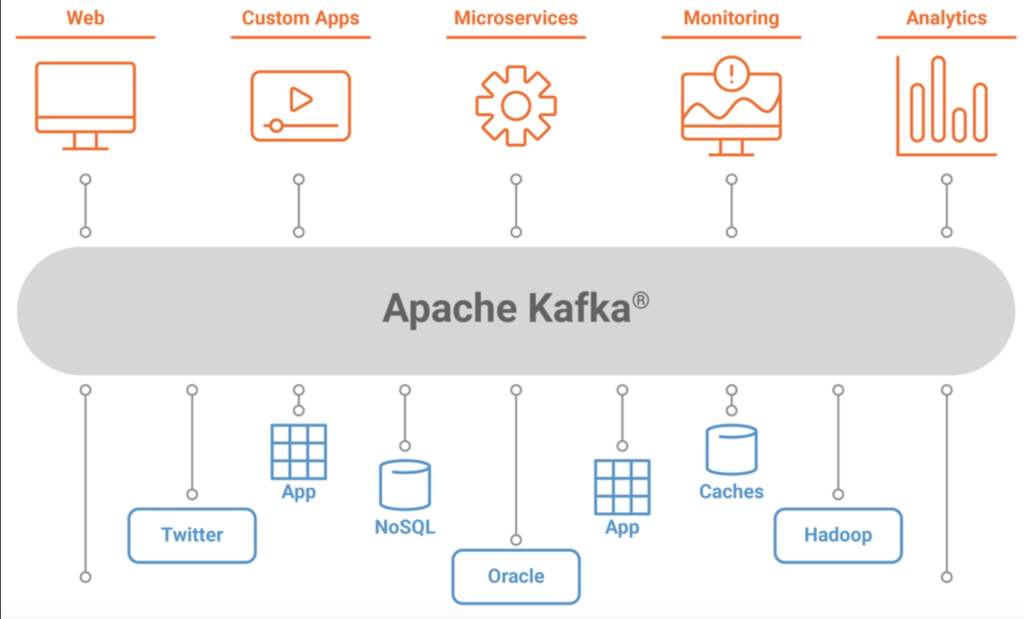
In this comprehensive guide, you will learn:
- What Kafka is and why it’s widely adopted.
- The top use cases where Kafka excels.
- Key alternatives to Kafka and a comparison of their pros and cons.
- The essential terminology needed to navigate Kafka’s ecosystem.
- How Kafka works internally and what the message workflow looks like.
- Design best practices and common challenges encountered in real-world deployments.
By the end of this guide, you’ll have a deep understanding of Apache Kafka and be well-equipped to evaluate it for your own data streaming needs.
Real-time data streaming means that data is continuously flowing and is processed immediately as it arrives, rather than being stored and processed later in batches. Imagine watching a live sports game on TV—every moment is broadcast and updated instantly. In data streaming, as soon as a piece of data (like a sensor reading or a user action) is generated, it’s sent through the system for processing without delay.
Event-driven means that a system is designed to react to specific events (like a button click, a purchase transaction, or a file upload) as soon as they occur. Instead of continuously checking for changes, the system “listens” for these events and then triggers the appropriate response immediately. Think of it like an alarm system that goes off the moment it detects motion.
In summary:
- Real-time Data Streaming: Continuous, live processing of data as soon as it’s produced—similar to a live video feed.
- Event-Driven Architecture: The system responds instantly to specific events or actions—like a light turning on when a motion sensor is triggered.
This approach makes systems more responsive and efficient, especially for applications that require immediate action based on incoming data.
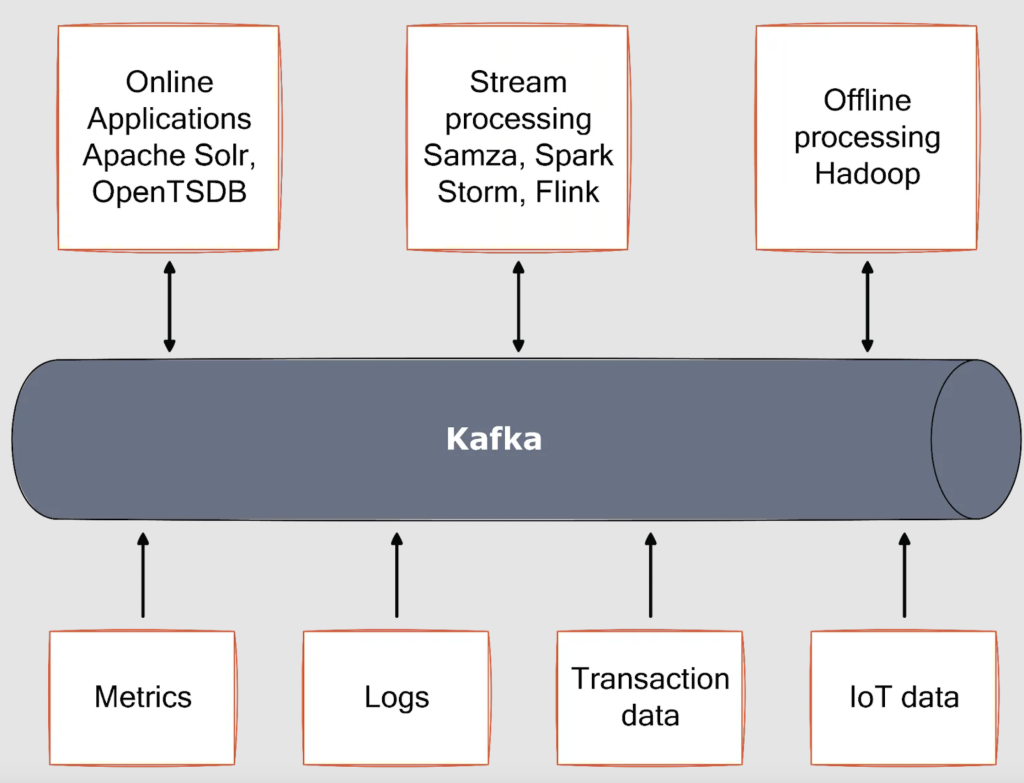
In Kafka, when we say “Real-time data streaming”, it consists of two key terms:
- Data
- Streaming
Let’s break these down in the context of Kafka:
Kafka Options
1. Meaning of Data
In Kafka, Data refers to any information that is produced, processed, or consumed in the system. This can be:
- Logs (Server logs, application logs)
- Metrics (CPU usage, memory usage)
- User Activity (Clicks, transactions, searches)
- IoT Sensor Data (Temperature, humidity)
- Financial Transactions (Stock prices, bank transactions)
- Social Media Feeds (Tweets, posts, comments)
In Kafka, data is structured as messages (events), which are produced by publishers (producers) and consumed by subscribers (consumers).
2. Meaning of Streaming
Streaming in Kafka means that data is processed as a continuous flow of events, instead of traditional batch processing.
In simple terms:
- Instead of collecting data in large chunks and processing it later, Kafka allows you to process each piece of data as it arrives.
- This enables real-time analytics, monitoring, and decision-making.
Example:
Imagine an online shopping website.
- Every time a user adds an item to the cart, searches for a product, or completes a purchase, an event is generated.
- Kafka streams these events in real-time to multiple services such as:
- Recommendation Engine (Suggest similar products)
- Inventory System (Update stock levels)
- Analytics Dashboard (Track sales and user activity live)
Putting it together:
- Data = Any meaningful event (like a user search, transaction, or sensor reading).
- Streaming = Continuously processing and transferring these events in real-time.
In Kafka, real-time data streaming means handling and processing a continuous flow of real-time events without waiting for batch processing.
2. What Is Kafka?
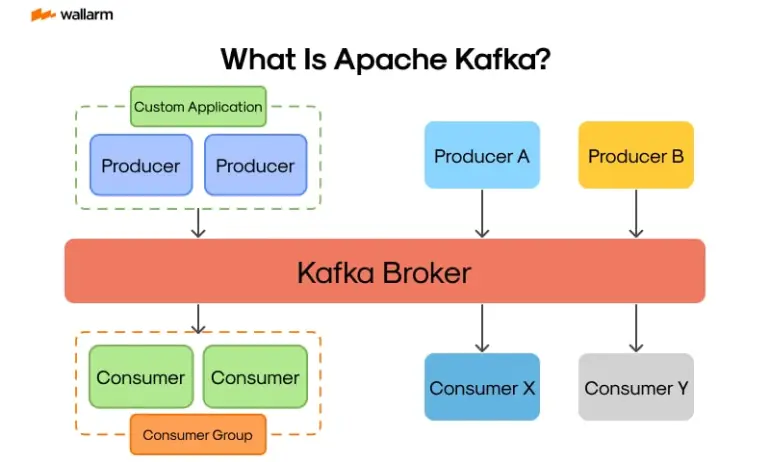
Apache Kafka is a distributed streaming platform that can handle real-time data feeds. At its core, Kafka is built for high-throughput, low-latency messaging and has three primary capabilities:
- Publish and Subscribe to Streams of Records:
Kafka allows producers (applications that write data) to send messages (or events) to Kafka topics, while consumers (applications that read data) subscribe to those topics and process the data. - Store Streams of Records in a Fault-Tolerant Manner:
Kafka persists data to disk and replicates it across a cluster, ensuring durability and reliability even if nodes fail. - Process Streams of Records in Real Time:
With Kafka Streams (its stream processing library) or integrations with frameworks like Apache Spark, Kafka enables real-time data processing and analytics.
Core Characteristics
- Scalability:
Kafka clusters can be easily expanded by adding new brokers. - High Throughput:
Capable of handling millions of messages per second, Kafka is designed for very high throughput. - Fault Tolerance:
Data replication across brokers ensures that data remains available even in the event of failures. - Low Latency:
Kafka delivers messages with low latency, making it suitable for real-time applications. - Durability:
Kafka persists messages on disk, ensuring that no data is lost.
Kafka’s architecture makes it ideal for a wide range of applications, from real-time analytics and monitoring systems to log aggregation and event sourcing.
3. Top Use Cases of Kafka
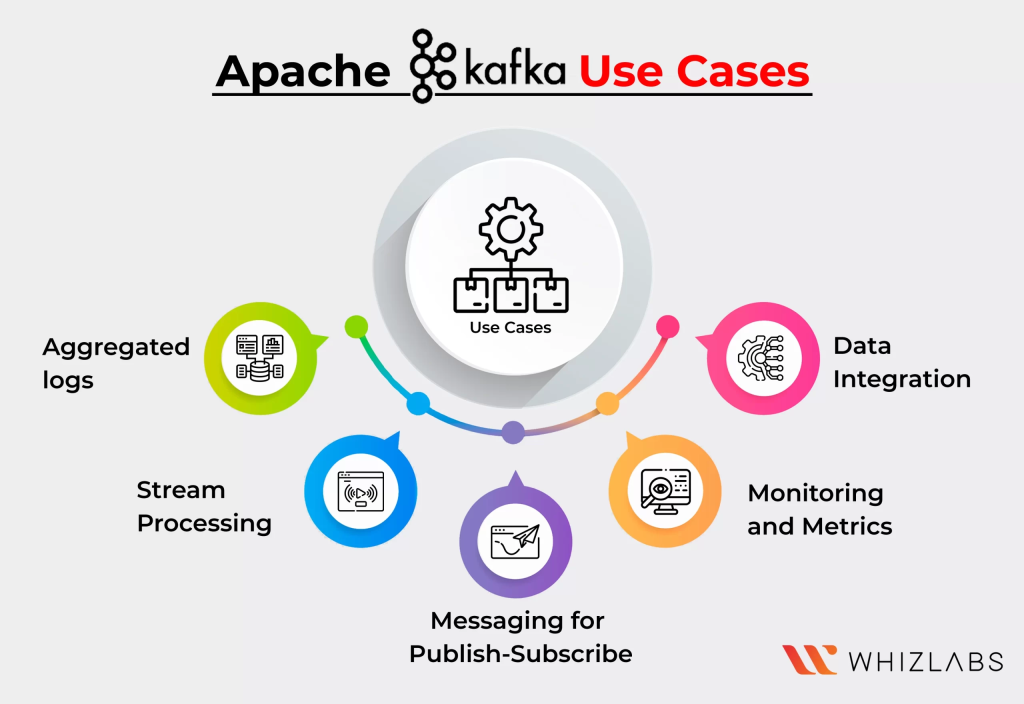
Apache Kafka is versatile and is used in many industries. Here are some of its top use cases:
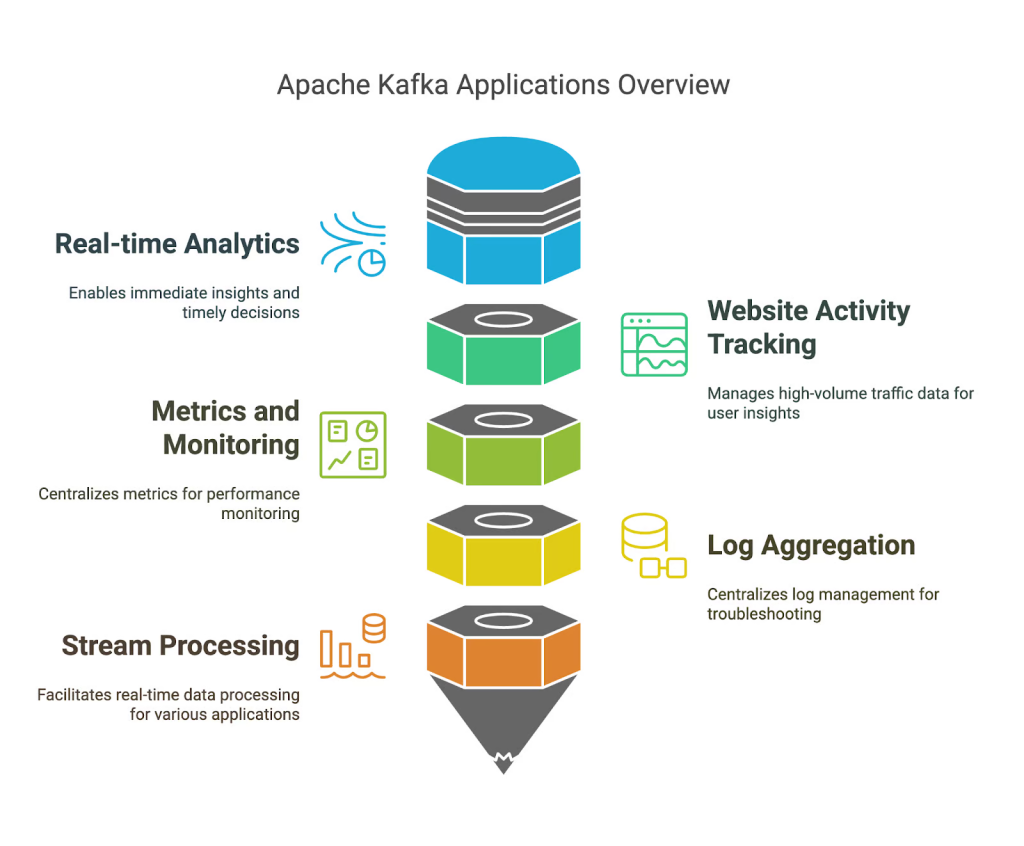
3.1 Real-Time Data Streaming and Analytics
- Streaming Analytics:
Kafka acts as the backbone for real-time analytics pipelines, where data from sensors, applications, or web logs is processed on the fly. - Monitoring and Metrics:
It is used to collect and analyze system logs, performance metrics, and user activity in real time, enabling prompt responses to anomalies.
3.2 Log Aggregation
- Centralized Logging:
Organizations use Kafka to aggregate logs from different services and systems. This centralized approach simplifies troubleshooting and monitoring. - Event Sourcing:
Kafka’s append-only log mechanism makes it an excellent choice for event sourcing architectures, where every state-changing event is captured and stored.
3.3 Messaging and Communication Backbone
- Decoupled Communication:
Kafka provides a robust messaging system for microservices, allowing them to communicate asynchronously. This decoupling enhances scalability and fault tolerance. - Notification Systems:
Many applications use Kafka to send notifications, alerts, or updates in real time.
3.4 Data Integration and ETL Pipelines
- Data Ingestion:
Kafka is often used as an intermediary in data ingestion pipelines, feeding data into data lakes, warehouses, or other storage systems. - Change Data Capture (CDC):
It enables tracking of changes in databases (CDC) and propagating those changes to downstream systems.
3.5 Internet of Things (IoT)
- Sensor Data Collection:
In IoT scenarios, Kafka can ingest and process data streams from thousands of devices, making it an ideal platform for building real-time IoT applications.
3.6 Machine Learning and AI Pipelines
- Data Streaming for ML Models:
Kafka streams can provide continuous data feeds to machine learning models for real-time predictions and model retraining. - Feature Store Updates:
It facilitates real-time updates to feature stores used by machine learning pipelines.
Each of these use cases leverages Kafka’s strengths—scalability, fault tolerance, and high throughput—to solve complex real-time data challenges.
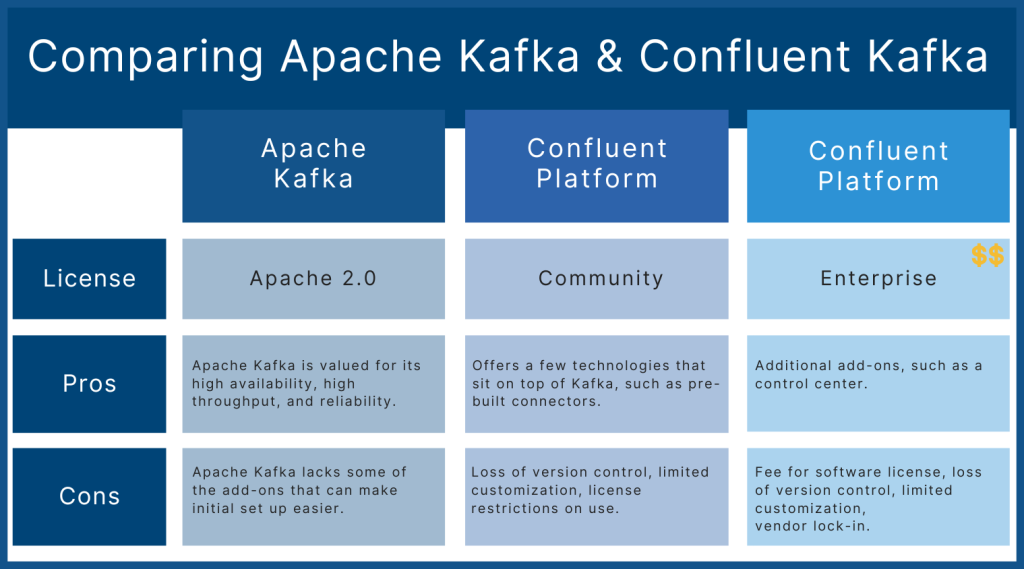
4. Best Alternatives to Kafka
While Apache Kafka is a dominant player in the streaming space, there are several alternatives that you might consider based on your specific requirements. Here are some of the leading alternatives along with their pros and cons.
4.1 Apache Pulsar
Overview:
Apache Pulsar is a distributed pub-sub messaging system that supports both streaming and queuing use cases.
Pros:
- Multi-Tenancy:
Built-in support for multi-tenancy, which can simplify complex deployments. - Geo-Replication:
Native support for geo-replication across data centers. - Flexible Messaging Models:
Offers both queue-based and pub-sub messaging.
Cons:
- Maturity:
While rapidly evolving, it might not have the same level of community support as Kafka. - Complexity:
Its architecture is more complex due to the separation of serving and storage layers.
4.2 RabbitMQ
Overview:
RabbitMQ is a widely used message broker that implements the Advanced Message Queuing Protocol (AMQP).
Pros:
- Ease of Use:
Simple to set up and deploy. - Flexible Routing:
Supports complex routing scenarios with its exchange types. - Mature Ecosystem:
Has a long history and robust community support.
Cons:
- Throughput Limitations:
Not as well-suited for very high-throughput scenarios compared to Kafka. - Scalability:
Scaling RabbitMQ for high-volume streams can be more challenging.
4.3 Amazon Kinesis
Overview:
Amazon Kinesis is a fully managed streaming data service provided by AWS.
Pros:
- Managed Service:
No need to manage infrastructure, with seamless integration into the AWS ecosystem. - Real-Time Analytics:
Provides built-in analytics capabilities. - Scalability:
Can handle high throughput with minimal configuration.
Cons:
- Cost:
Can become expensive at scale. - Vendor Lock-In:
Tightly coupled with AWS services, making multi-cloud strategies more challenging.
4.4 Google Cloud Pub/Sub
Overview:
Google Cloud Pub/Sub is a messaging service for exchanging event data among applications and services on Google Cloud.
Pros:
- Fully Managed:
Eliminates the operational overhead of running your own infrastructure. - Global Scalability:
Designed to scale globally with low latency. - Integration:
Seamless integration with other Google Cloud services.
Cons:
- Cost:
Pricing can be a concern for high-volume data streams. - Limited Customization:
Fewer customization options compared to self-managed solutions like Kafka.
4.5 ActiveMQ
Overview:
Apache ActiveMQ is another mature, open-source message broker that supports multiple protocols.
Pros:
- Protocol Support:
Supports a wide range of messaging protocols. - Ease of Integration:
Works well with legacy systems. - Maturity:
Has been around for many years with a stable community.
Cons:
- Performance:
May not handle high-throughput streaming scenarios as efficiently as Kafka. - Scalability:
Scaling ActiveMQ can be more challenging in distributed environments.
Each of these alternatives has its strengths and may be a better fit for specific use cases or environments. The best alternative depends on your performance, scalability, operational, and cost requirements.
5. Key Terminologies in Kafka
To effectively work with Kafka, it’s important to understand its core terminologies. Here’s a glossary of the essential terms:
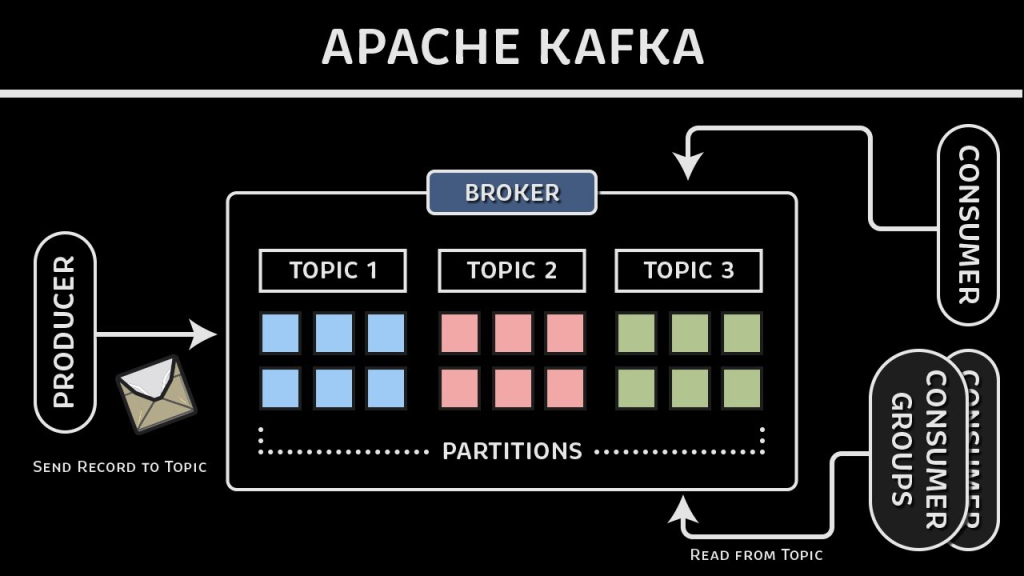
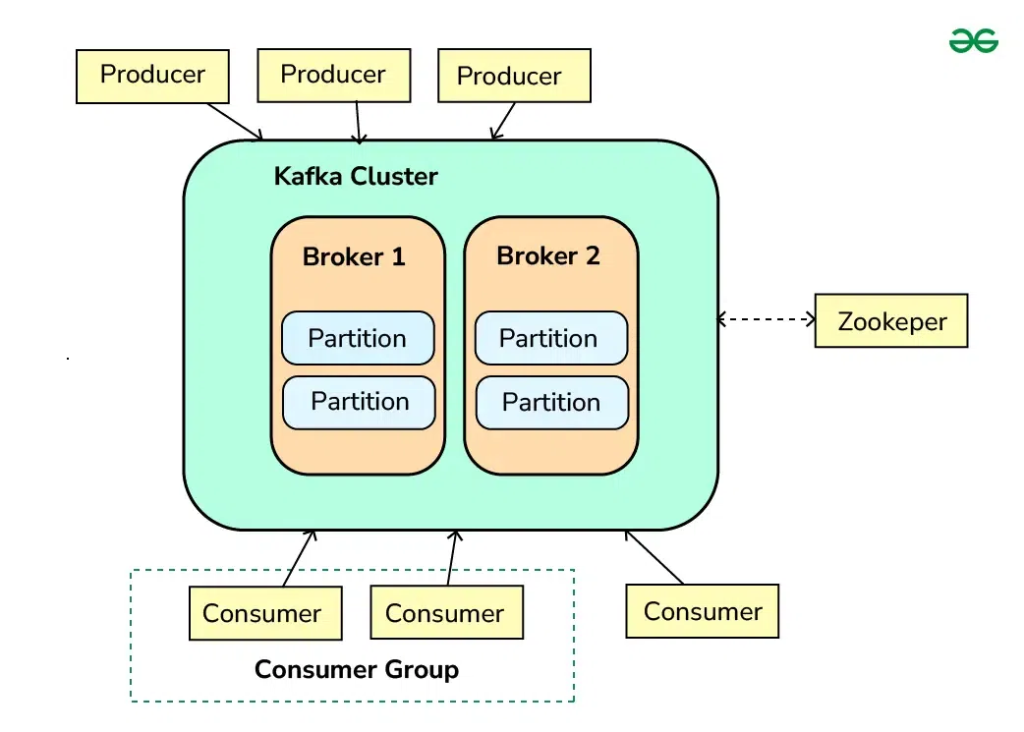
5.1 Broker
- Definition:
A Kafka broker is a server that stores data and serves client requests. A Kafka cluster is composed of multiple brokers for redundancy and scalability.
5.2 Topic
- Definition:
A topic is a category or feed name to which records are published. Producers write data to topics, and consumers subscribe to them. - Note:
Topics can be partitioned to allow parallel processing.
5.3 Partition
- Definition:
A partition is a subset of a topic’s data. Each partition is an ordered, immutable sequence of records. - Purpose:
Partitions enable Kafka to scale horizontally by distributing data across multiple brokers.
5.4 Offset
- Definition:
An offset is a unique identifier for each record within a partition. It indicates the position of a record in that partition. - Usage:
Consumers track offsets to know which records have been processed.
5.5 Producer
- Definition:
A producer is an application that publishes (writes) messages to Kafka topics.
5.6 Consumer
- Definition:
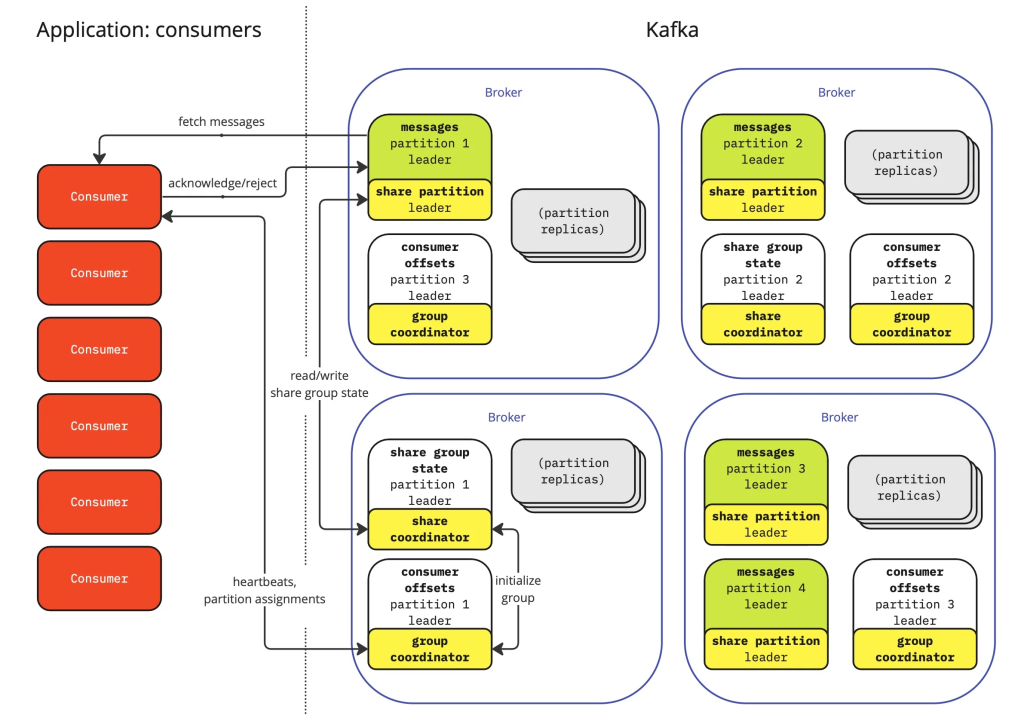
A consumer is an application that subscribes to topics and processes the published messages. - Consumer Group:
A group of consumers that share the load of reading from a topic. Each partition’s messages are read by only one consumer in a group.
5.7 Replication
- Definition:
Replication is the process of copying data across multiple brokers to ensure fault tolerance. - Replication Factor:
The number of copies of each partition that are maintained in the cluster.
5.8 Leader and Follower
- Leader:
The broker that handles all read and write requests for a partition. - Follower:
Brokers that replicate the leader’s data and can take over if the leader fails.
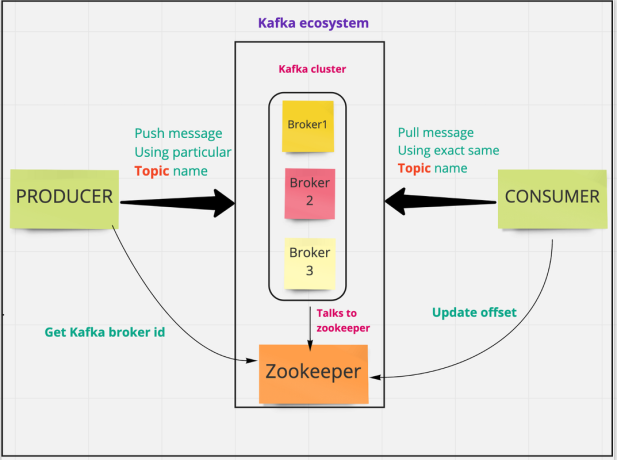
5.9 Zookeeper (Legacy)
- Definition:
Apache ZooKeeper was used in earlier versions of Kafka for cluster coordination. - Note:
Newer Kafka versions are moving away from ZooKeeper by incorporating KRaft (Kafka Raft) for metadata management.
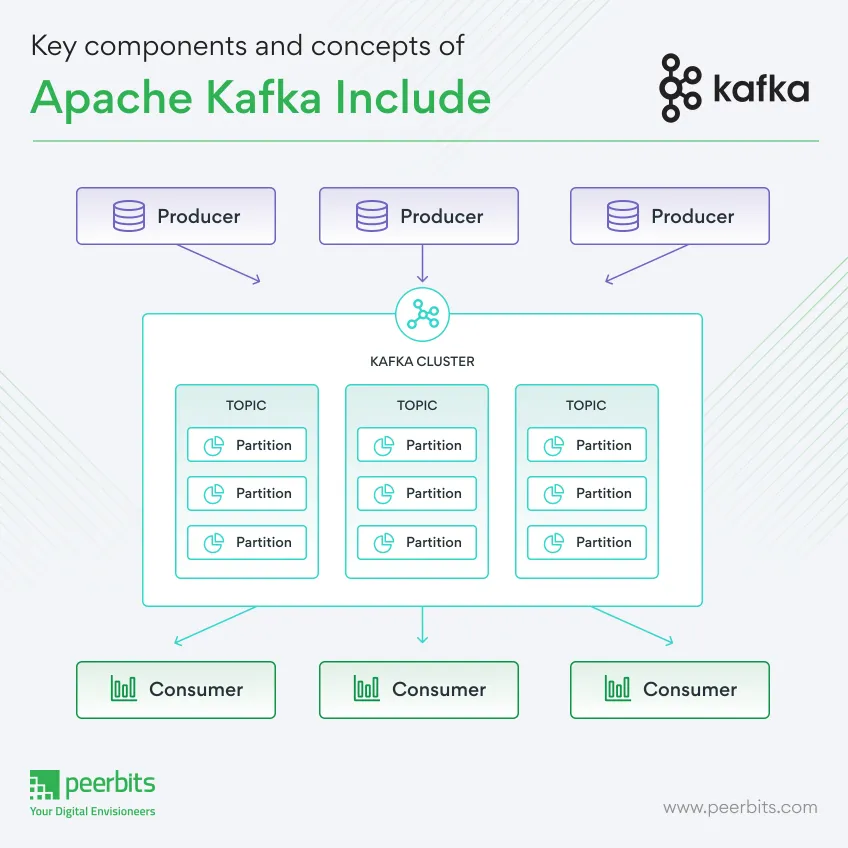
6. How Kafka Works
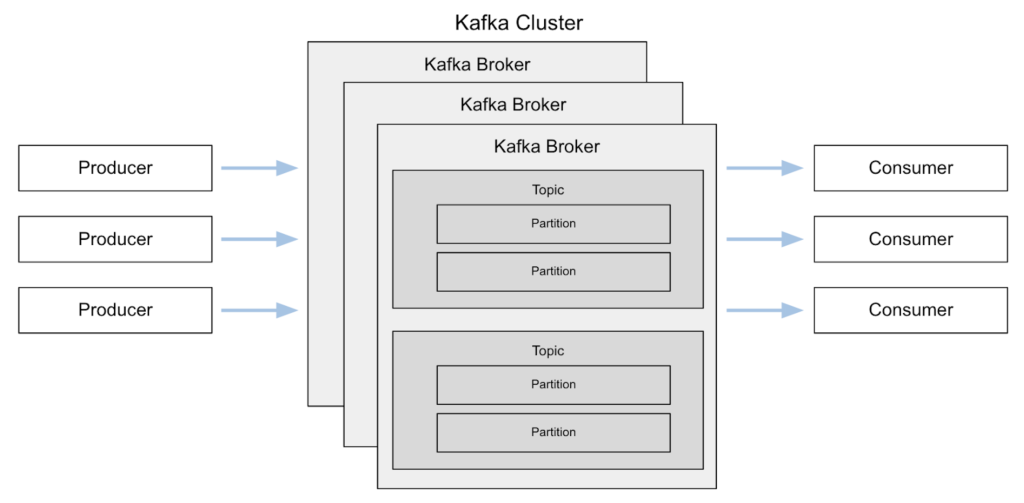
Kafka’s architecture is designed for scalability, fault tolerance, and high throughput. Here’s an overview of how it works:
6.1 Distributed Cluster Architecture
- Cluster Formation:
A Kafka cluster consists of multiple brokers. Data is distributed among these brokers using topics and partitions. - Replication and Fault Tolerance:
Each partition has one leader and multiple followers. The leader handles all client interactions, while followers replicate the leader’s data. In case of a broker failure, one of the followers becomes the new leader.
6.2 Producers and Consumers
- Producers:
Producers send data to topics. They can choose to send messages to a specific partition or let Kafka determine the partition based on a key or a round-robin algorithm. - Consumers:
Consumers subscribe to topics and process messages. When part of a consumer group, each message is processed by only one consumer in that group.
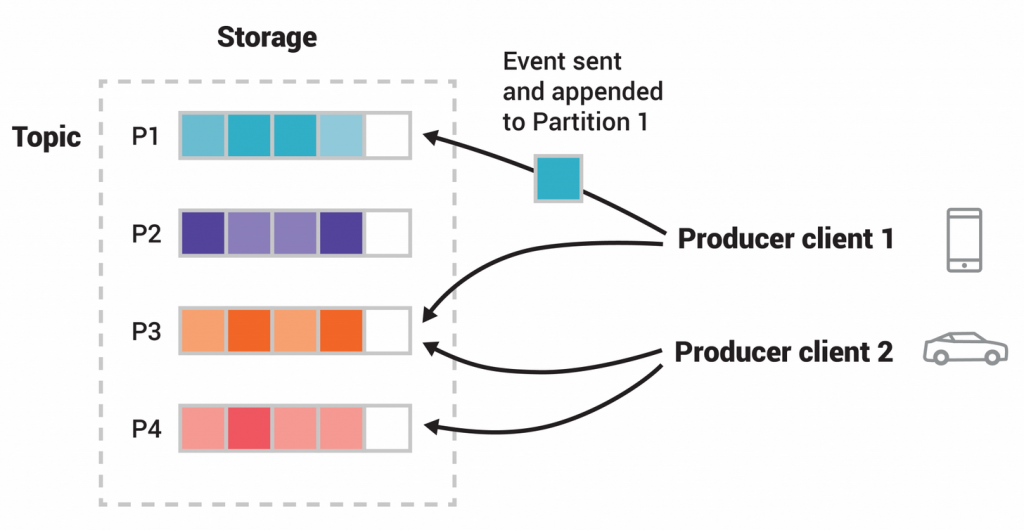
6.3 Data Flow
- Message Production:
- A producer sends a record (message) to a Kafka topic.
- The record is appended to a partition log, and the offset is assigned.
- Replication:
- The leader broker for that partition replicates the record to its follower brokers.
- Message Consumption:
- Consumers pull data from the brokers at their own pace.
- They maintain their offset pointers to track which messages have been processed.
6.4 Durability and Retention
- Durability:
Kafka persists messages to disk and replicates them, ensuring durability. - Retention Policies:
Topics can be configured with retention policies (time-based or size-based), after which old records are deleted.
7. Kafka Workflow: From Producer to Consumer
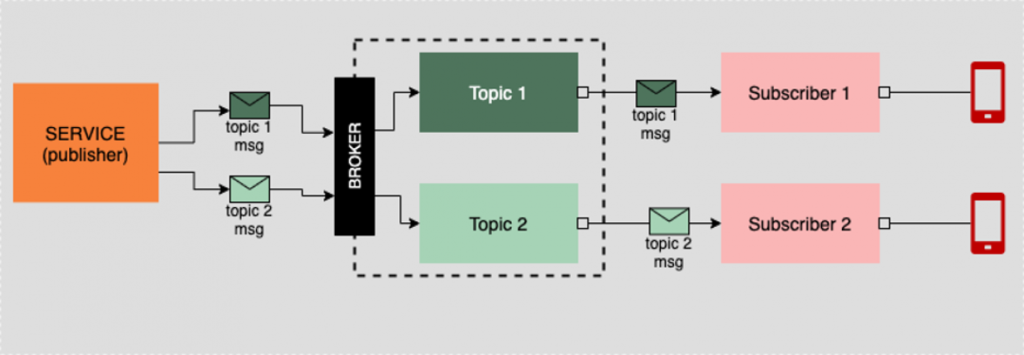
Understanding the Kafka workflow helps illustrate how messages traverse the system. Here’s a step-by-step overview:
7.1 Step-by-Step Workflow
- Producer Initialization:
- A producer application connects to one or more Kafka brokers.
- It prepares messages with an optional key (which can determine partition assignment).
- Message Production:
- The producer sends a message to a specific topic.
- Kafka assigns the message an offset within the partition.
- Data Replication:
- The broker designated as the partition leader writes the message to its log.
- The leader propagates the message to follower brokers.
- Message Acknowledgement:
- Once the message is replicated (depending on the acknowledgment configuration), the producer receives an acknowledgment.
- This ensures that the message is safely stored.
- Consumer Subscription:
- Consumer applications subscribe to one or more topics.
- When part of a consumer group, Kafka assigns partitions to different consumers.
- Message Consumption:
- Consumers poll for new messages from their assigned partitions.
- After processing, consumers commit their offsets to track progress.
- Offset Management:
- Offsets can be committed automatically or manually.
- In case of failure, consumers resume from the last committed offset.
7.2 Visual Diagram (Conceptual)
+------------+ +------------+ +------------+
| Producer | ---> | Broker | ---> | Follower |
| (App) | | (Leader) | | Brokers |
+------------+ +------------+ +------------+
| | ^ ^ |
| | | | |
v v | v v
+---------------------------------------------------------------+
| Kafka Topic |
| Partition 1: [msg1, msg2, msg3, ...] |
+---------------------------------------------------------------+
| |
v v
+------------+ +------------+
| Consumer A | | Consumer B | <-- Part of Consumer Group
+------------+ +------------+
This diagram illustrates how a producer writes messages to a topic, how replication works, and how consumers in a consumer group process messages in parallel.
8. Design Considerations and Best Practices
When designing systems with Kafka, consider the following best practices:
8.1 Topic and Partition Design
- Partitioning:
Choose the number of partitions wisely to balance load and achieve parallelism. More partitions can improve throughput but may also increase overhead. - Keying Strategy:
Use message keys effectively to ensure that related messages land in the same partition.
8.2 Fault Tolerance and Replication
- Replication Factor:
Set an appropriate replication factor for topics to ensure durability in the face of broker failures. - Monitoring:
Continuously monitor broker health, consumer lag, and message throughput.
8.3 Consumer Group Management
- Load Balancing:
Use consumer groups to distribute the processing load. Ensure that the number of consumers does not exceed the number of partitions. - Offset Management:
Decide on manual versus automatic offset commits based on processing guarantees.
8.4 Data Retention and Cleanup
- Retention Policies:
Configure retention policies that align with business requirements (e.g., keeping data for 7 days). - Log Compaction:
Use log compaction for topics that require the latest value per key, which is useful for changelog streams.
8.5 Security
- Encryption:
Secure data in transit with SSL/TLS. - Access Control:
Implement ACLs (Access Control Lists) to restrict which producers/consumers can access specific topics. - Authentication:
Use SASL or other mechanisms to authenticate clients.
9. Challenges and Future Directions
While Kafka is powerful, several challenges and evolving trends impact its adoption:
9.1 Operational Complexity
- Scaling:
Managing large Kafka clusters requires robust monitoring and operational expertise. - Upgrades:
Upgrading Kafka clusters in production can be challenging due to stateful data and broker dependencies.
9.2 Ecosystem Integration
- Tooling:
Integrating Kafka with existing data systems (e.g., data warehouses, analytics engines) often requires additional connectors and middleware. - Stream Processing:
The evolution of stream processing frameworks (like Kafka Streams and ksqlDB) is opening new opportunities and challenges.
9.3 Future Directions
- Kafka Raft Metadata Mode (KRaft):
Kafka is evolving to remove the dependency on ZooKeeper with KRaft, which simplifies deployment and management. - Enhanced Security and Governance:
Ongoing improvements in security, data governance, and compliance will further solidify Kafka’s role in enterprise environments. - Cloud-Native Deployments:
As more organizations move to the cloud, managed Kafka services (such as Confluent Cloud, AWS MSK, and others) are becoming more prevalent.
Kafka Integration
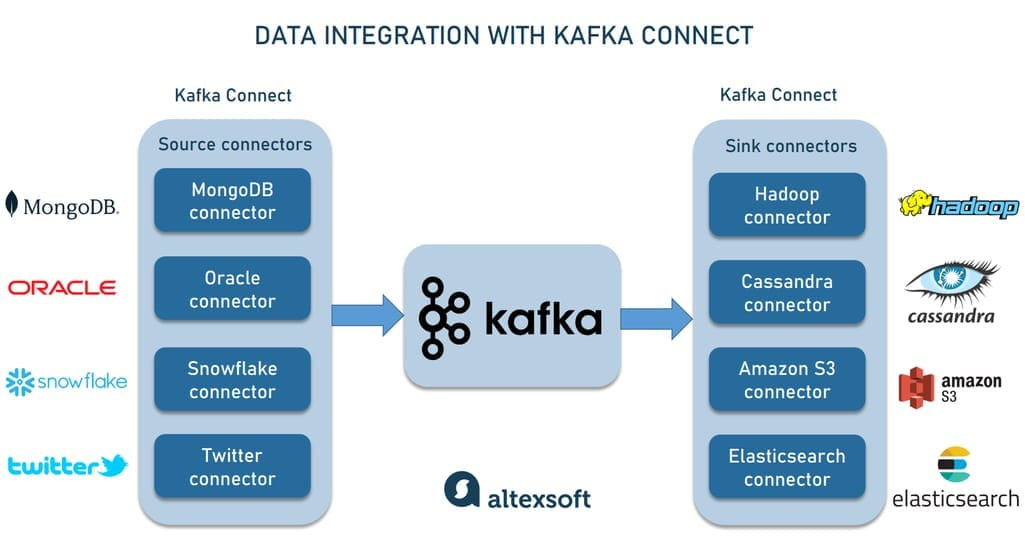
10. Conclusion
Apache Kafka has become synonymous with real-time data streaming and event-driven architectures. This comprehensive guide has covered:
- What Kafka is and why it’s a critical component in modern data architectures.
- Top use cases from real-time analytics to log aggregation and IoT data ingestion.
- Alternatives to Kafka like Apache Pulsar, RabbitMQ, Amazon Kinesis, Google Cloud Pub/Sub, and ActiveMQ, with their strengths and trade-offs.
- Key terminology—including brokers, topics, partitions, offsets, and consumer groups—that is essential for navigating Kafka’s ecosystem.
- How Kafka works internally, from data production and replication to consumption and offset management.
- The Kafka workflow, detailing the end-to-end journey of a message.
- Best practices, design considerations, and emerging challenges that you need to be aware of when implementing Kafka-based solutions.
By understanding the fundamentals, the workflow, and the design considerations, you can better leverage Kafka to build robust, scalable, and fault-tolerant data streaming applications.
This guide provides a deep dive into Apache Kafka and should serve as a resource for both newcomers and experienced professionals looking to implement or optimize Kafka-based systems. Whether you are designing a new real-time processing pipeline or enhancing an existing data architecture, Kafka’s robust ecosystem and scalability make it an ideal choice for modern, data-driven applications.
Feel free to explore further resources and documentation to expand your knowledge and stay updated with the latest Kafka developments!
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
