
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comWhat is DataOps?
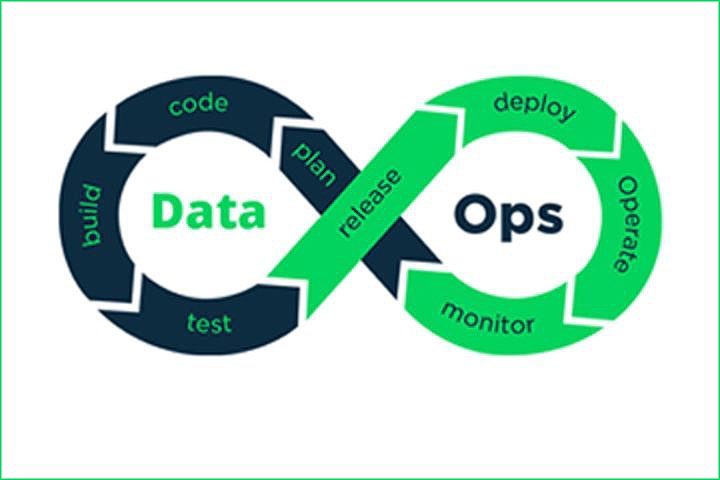
According to Gartner,”DataOps is a collaborative data management practice, really focused on improving communication, integration, and automation of data flow between managers and consumers of data within an organization.”
How to implement DataOps?
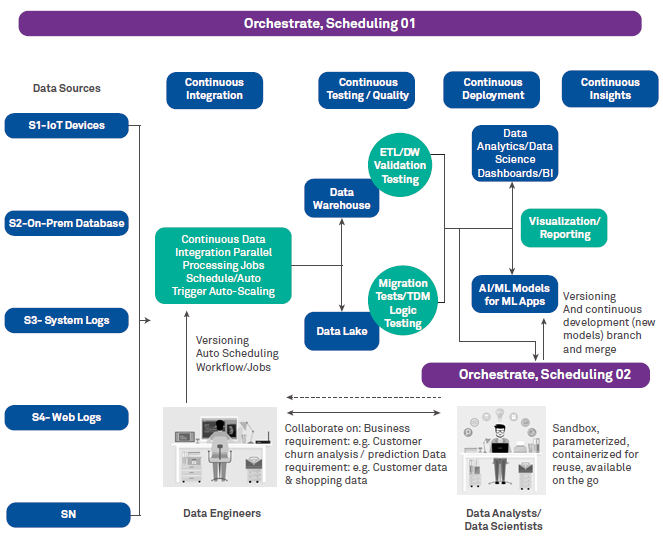
- Data orchestration – The aim of automated data orchestration is to take off the toil of data engineering and support teams and automate it with tools. As an example of an open source data orchestration tool is Apache Airflow, which has a number of benefits like :
- Capability to orchestrate difficult interdependent data pipelines.
- Scalability to manage hundreds of flows.
- Robust security and controlled access with LDAP/AD integration, Kerberos authentication support, role-based access, and multi-tenancy.
- Support for a variety of pipeline triggers comprise time-based scheduling, data dependencies sensors such as creation or update of files on the file system, changes in database tables, and inter-pipeline dependencies including completion or failure of upstream jobs.
- Flexible retry policies with configurable recovery options and SLA enforcement.
- Suitable graphical interface for visualization of data pipeline dependency graphs.
- Extensible Python-based DSL as a primary configuration language.
- Rich reusable components library.
- Embedded secrets management subsystem.
- Storing orchestration and job configuration as code in source code version systems.
- Support for local testing of pipelines on developers’ workstations
- Flexible configuration of jobs for high availability and disaster recovery.
- Cloud-friendly with support to provision task executors on-demand using Kubernetes.
- Data monitoring– Few DataOps articles refer to statistical process controls, which we call data monitoring. Data monitoring is the initial step and forerunner to data quality. The main idea behind data monitoring is observing data profiles over time and catching potential anomalies.
In simple way, it can be implemented by collecting various metrics of the datasets and individual data column, such as:
- Number of processed records over time.
- Ranges of values for numeric or date columns.
- Size of data in text or binary data columns.
- Number of null or empty values.
Then for each metric, the system would calculate a number of usual statistics, such as:
- Mean value.
- Median value.
- Percentiles.
- Standard deviation.
This information is helpful to observe whether the new data item or dataset is really different from what the system has observed in the past. The data analytics and data science teams can also use collected data profiles to learn more about data to quickly accredit some hypotheses.
The simple methods of data monitoring can be enlarged by AI-driven anomaly detection. Modern anomaly detection algorithms can learn periodic data patterns, use correlations between various metrics, and reduce the number of false positive alerts. To learn more about this technique, read our recent article on various approaches to real-time anomaly detection.
- Data quality – While data monitoring helps data engineers, analysts, and scientists learn additional details about data and get alerted in case of anomalies, data quality capabilities take the idea of improvise data trustworthiness, or veracity, to another level. The first goal of data quality is to automatically detect data corruption in the pipeline and prevent it from spreading.
Data quality uses three main techniques to accomplish that goal:
- Business rules – Business rules can be thought of as tests that continuously run in the production data pipeline to check if data complies with pre-defined requirements. It is a fully supervised way to ensure data integrity and quality. It requires the most effort but is also the most precise.
- Anomaly detection – The anomaly detection implemented for data monitoring can be reused for data quality enforcement and requires setting certain thresholds to balance between precision and recall.
- Comparison with data sources – Comparison of data in the lake with data sources typically works for ingested data and is best used for occasional validation of data freshness for streaming ingress in the data lake. This method has the most overhead in production and requires either direct access to systems-of-record databases or APIs.
If a team already uses automated data orchestration tools that support configuration-as-code such as Apache Airflow, data quality jobs can be automatically embedded in the required steps between, or in parallel to, data processing jobs. This further saves time and effort to keep the data pipeline monitored. To learn more about data quality, please refer to our recent article. To speed up implementation of data quality in the existing analytical data platforms, we have implemented an accelerator based on the open source technology stack. The accelerator is built with cloud-native architecture and works with most types of data sources.
- Data governance – Data governance is a universal term that also encompasses people and process techniques however, we will focus on the technology and tooling aspects of it. The two aspects of data governance tooling that have become absolute must-haves for any modern analytical data platform are the data catalog and data lineage.
Data catalog and lineage enable data scientists, analysts, and engineers to quickly find required datasets and learn how they were created. Tools like Apache Atlas, Collibra, Alation, Amazon Glue Catalog, or Data Catalogs from Google Cloud and Azure can be good starting points in implementing this capability.
Adding data catalog, data glossary, and data lineage capabilities increases productivity of the analytics team and improves speed to insights.
- Continuous delivery – The concept of DevOps is one of the cornerstones and inspirations behind the DataOps methodology. While DevOps relies on culture, skills, and collaboration, modern tooling and a lightweight but secure continuous integration and continuous delivery process helps with reducing time-to-market when implementing new data pipelines or data analytics use cases.
As is the case with regular application development, the continuous delivery process for data needs to follow microservices best practices. Such best practices allow the organization to scale, decrease time to implement and deploy new data or ML pipelines, and improve overall quality and stability of the system.
While having many similarities with application development, continuous delivery processes for data have their own specifics:
- Due to large volumes of data, attention should be placed on unit testing and functional testing with generated data.
- Due to the large scale of the production environment, it is often impractical to create on-demand environments for every execution of the CI/CD pipeline.
- Data orchestration tooling needs to be used for safe releases and A/B testing in production.
- A larger focus needs to be placed on data quality and monitoring in production and testing for data outputs.
Traditional tooling such as GitHub or other Git-based version control systems, unit testing and static code validation tools, Jenkins for CI/CD, and Harness.io for continuous deployment, find their principal use in the data engineering world. Using data pipeline orchestration tools, which allow configuration-as-code such as Apache Airflow, streamline the continuous delivery process even further.
Best Institute to learn DataOps
DevOpsSchool is the best institute to learn DataOps. It provides live and online classes that is the need in this pendamic to save ourselves. This institute has best IT trainers who are well trained and experienced to provide the training. A experience always share a valuable knowledge that helps in career road path. Pdf’s, slides videos so many things are there that is given by this institute. This institute is linked with so many IT companies. There are so many IT companies that is client of this institute that has got trained their employees from DevOpsSchool.
Reference
- What is DevOps?
- DataOps Certifications
- DataOps Consultants
- DataOps Consulting Company
- Best DataOps Courses
- Best DataOps Tools
- Best DataOps Trainer
- Best DataOps Training
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
