
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comSRE Concepts
- Remove Silos and help increase sharing and collaboration between the Development and Operations team
- Accidents are Normal. It is more profitable to focus on speeding recovery than preventing accidents.
- Focus on small and gradual changes. This strategy, coupled with automatic testing of smaller changes and reliable rollback of bad changes, leads to approaches to change management like CI/CD.
- Measurement is Crucial.
SRE Foundations
- SLIs, SLOs, and SLAs
- Monitoring
- Alerting
- Toil reduction
- Simplicity
SLI, SLO, and SLAs
- SRE does not attempt to give everything 100% availability
- SLIs – Service Level Indicators
- “A carefully defined quantitative measure of some aspect of the level of service that is provided”
- SLIs define what to measure
- SLIs are metrics over time – specific to a user journey such as request/response, data processing – which shows how well the service is performing.
- SLIs is the ratio between two numbers: the good and the total:
- Success Rate = No. of successful HTTP request / total HTTP requests
- Throughput Rate = No. of consumed jobs in a queue / total number of jobs in a queue
- SLI is divided into specification and implementation. for e.g.
- Specification: ration of requests loaded in < 100 ms
- Implementation is a way to measure for e.g. based on: a) server logs b) client code instrumentation
- SLI ranges from 0% to 100%, where 0% means nothing works, and 100% means nothing is broken
- Types of SLIs
- Availability – The proportion of requests which result in a successful state
- Latency – The proportion of requests below some time threshold
- Freshness – The proportion of data transferred to some time threshold. Replication or Data pipeline
- Correctness – The proportion of input that produces correct output
- Durability – The proportion of records written that can be successfully read
- SLO – Service Level Objective
- “SLOs specify a target level for the reliability of your service.”
- SLO is a goal that the service provider wants to reach.
- SLOs are tools to help determine what engineering work to prioritize.
- SLO is a target percentage based on SLIs and can be a single target value or range of values for e.g. SLI <= SLO or (lower bound <= SLI <= upper bound) = SLO
- SLOs also define the concept of error budget.
- The Product and SRE team should select an appropriate availability target for the service and its user base, and the service is managed to that SLO.
- Error Budget
- Error budgets are a tool for balancing reliability with other engineering work, and a great way to decide which projects will have the most impact.
- An Error budget is 100% minus the SLO
- If an Error budget is exhausted, a team can declare an emergency with high-level approval to deprioritize all external demands until the service meets SLOs and exit criteria.
- SLOs & Error budget approach
- SLOs are agreed and approved by all stakeholders
- It is possible to meet SLOs needs under normal conditions
- The organization is committed to using the error budget for decision making and prioritizing
- Error budget policy should cover the policy if the error budget is exhausted.
- SLO and SLI in practice
- The strategy to implement SLO, SLI in the company is to start small.
- Consider the following aspects when working on the first SLO.
- Choose one application for which you want to define SLOs
- Decide on a few key SLIs specs that matter to your service and users
- Consider common ways and tasks through which your users interact with service
- Draw a high-level architecture diagram of your system
- Show key components. The requests flow. The data flow
- The result is a narrow and focused proof of concept that would help to make the benefits of SLO, SLI concise and clear.
Monitoring
- Monitoring allows you to gain visibility into a system, which is a core requirement for judging service health and diagnosing your service when things go wrong
- from an SRE perspective,
- Alert on conditions that requires attention
- Investigate and diagnose issues
- Display information about the system visually
- Gain insight into system health and resource usage for long-term planning
- Compare the behavior of the system before and after a change, or between two control groups
- Monitoring features that might be relevant
- Speed of data retrieval and freshness of data.
- Data retention and calculations
- Interfaces: graphs, tables, charts. High level or low level.
- Alerts: multiple categories, notifications flow, suppress functionality.
- Monitoring sources
- Metrics are numerical measurements representing attributes and events, typically harvested via many data points at regular time intervals.
- Logs are an append-only record of events.
Alerting
- Alerting helps ensure alerts are triggered for a significant event, an event that consumes a large fraction of the error budget.
- Alerting should be configured to notify an on-caller only when there are actionable, specific threats to the error budget.
- Alerting considerations
- Precision – The proportion of events detected that were significant.
- Recall – The proportion of significant events detected.
- Detection time – How long it takes to send notification in various conditions. Long detection time negatively impacts the error budget.
- Reset time – How long alerts fire after an issue is resolved
- Ways to alerts
- The recommendation is to combine several strategies to enhance your alert quality from different directions.
- Target error rate ≥ SLO threshold.
- Choose a small time window (for example, 10 minutes) and alert if the error rate over that window exceeds the SLO.
- Upsides: Short detection time, Fast recall time
- Downsides: Precision is low
- Increased Alert Windows.
- By increasing the window size, you spend a higher budget amount before triggering an alert. for e.g. if an event consumes 5% of the 30-day error budget – a 36-hour window.
- Upsides: good detection time, better precision
- Downside: poor reset time
- Increment Alert Duration.
- For how long alert should be triggered to be significant.
- Upsides: Higher precision.
- Downside: poor recall and poor detection time
- Alert on Burn Rate.
- How fast, relative to SLO, the service consumes an error budget.
- Example: 5% error budget over 1 hour period.
- Upside: Good precision, short time window, good detection time.
- Downside: low recall, long reset time
- Multiple Burn Rate Alerts.
- Burn rate is how fast, relative to the SLO, the service consumes the error budget
- Depend on burn rate determine the severity of alert which lead to page notification or a ticket
- Upsides: good recall, good precision
- Downsides: More parameters to manage, long reset time
- Multi-window, multi burn alerts.
- Upsides: Flexible alert framework, good precision, good recall
- Downside: even harder to manage, lots of parameters to specify
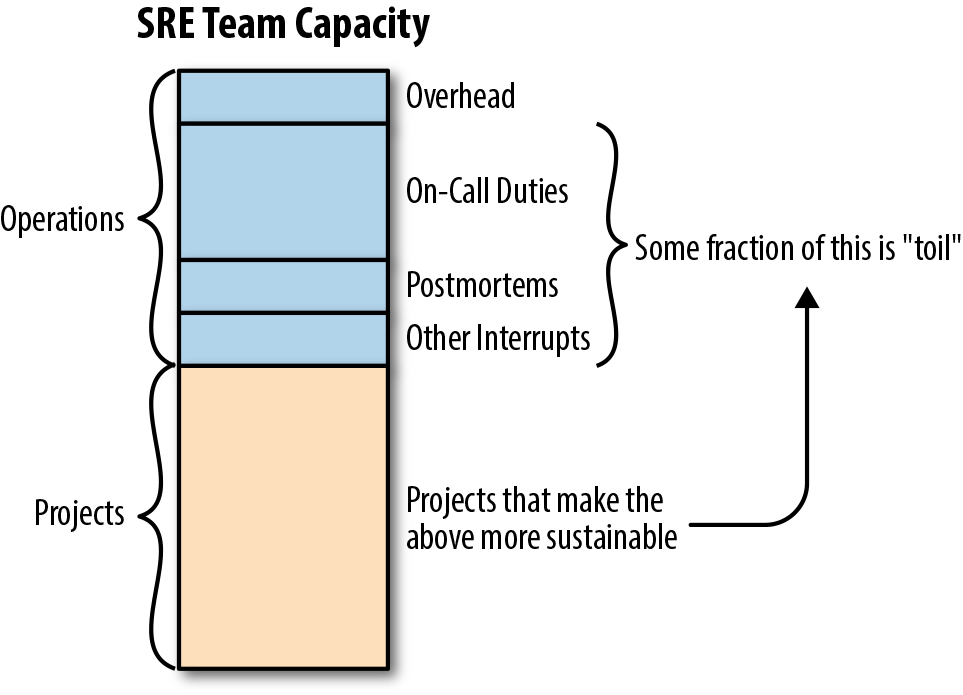
Toil Reduction
It’s better to fix root causes when possible. If I fixed the symptom, there would be no incentive to fix the root cause.
- Toils is a repetitive, predictable, constant stream of tasks related to maintaining a service.
- Any time spent on operational tasks means time not spent on project work and project work is how we make our services more reliable and scalable.
- Toil can be defined using following characteristics
- Manual. When the
tmpdirectory on a web server reaches 95% utilization, you need to login and find a space to clean up - Repetitive. A full
tmpdirectory is unlikely to be a one-time event - Automatable. If the instructions are well defined then it’s better to automate the problem detection and remediation
- Reactive. When you receive too many alerts of “disks full”, they distract more than help. So, potentially high-severity alerts could be missed
- Lacks enduring value. The satisfaction of completed tasks is short term because it is to prevent the issue in the future
- Grow at least as fast as its source. The growing popularity of the service will require more infrastructure and more toil work
- Manual. When the
- Potential benefits of toil automation
- Engineering work might reduce toil in the future
- Increased team morale and reduced burnout
- Less context switching for interrupts, which raises team productivity
- Increased process clarity and standardization
- Enhanced technical skills and career growth for team members
- Reduced training time
- Fewer outages attributable to human errors
- Improved security
- Shorter response times for user requests
- Toil Measurement
- Identify it.
- Measure the amount of human effort applied to this toil
- Track these measurements before, during, and after toil reduction efforts
- Toil categorization
- Business processes. A most common source of toil.
- Production interrupts. The key tasks to keep the system running.
- Product releases. Depending on the tooling and release size they could generate toil (release requests, rollbacks, hotfixes, and repetitive manual configuration changes)
- Migrations. Large-scale migration or even small database structure change is likely done manually as a one-time effort. Such thinking is a mistake because this work is repetitive.
- Cost engineering and capacity planning. Ensure a cost-effective baseline. Prepare for critical high traffic events.
- Troubleshooting
- Toil management strategies in practices
- Identify and measure
- Engineer toil out of the system
- Reject the toil
- Use SLO to reduce toil
- Organizational:
- Start with human-backed interfaces. For complex businesses, problems start with a partially automated approach.
- Get support from management and colleagues. Toil reduction is a worthwhile goal.
- Promote toil reduction as a feature. Create strong business case for toil reduction.
- Start small and then improve
- Standardization and automation:
- Increase uniformity. Lean-to standard tools, equipment and processes.
- Access risk within automation. Automation with admin-level privileges should have safety mechanism which checks automation actions against the system. It will prevent outages caused by bugs in automation tools.
- Automate toil response. Think how to approach toil automation. It shouldn’t eliminate human understanding of what’s going on.
- Use open-source and third-party tools.
- Use feedback to improve. Seek for feedback from users who interact with your tools, workflows and automation.
Simplicity
- Simple software breaks less often and is easier and faster to fix when it does break.
- Simple systems are easier to understand, easier to maintain, and easier to test
- Measure complexity
- Training time. How long does it take for a newcomer engineer to get on full speed.
- Explanation time. The time it takes to provide a view on system internals.
- Administrative diversity. How many ways are there to configure similar settings
- Diversity of deployed configuration
- Age. How old is the system
- SRE work on simplicity
- SRE understand the system’s as a whole to prevent and fix the source of complexity
- SRE should be involved in the design, system architecture, configuration, deployment processes, or elsewhere.
- SRE leadership empowers SRE teams to push for simplicity and to explicitly reward these efforts.
SRE Practices
SRE practices apply software engineering solutions to operational problems
- SRE teams are responsible for the day-to-day functioning of the systems we support, our engineering work often focuses
Incident Management & Response
- Incident Management involves coordinating the efforts of responding teams in an efficient manner and ensuring that communication flows both between the responders and those interested in the incident’s progress.
- Incident management is to respond to an incident in a structured way.
- Incident Response involves mitigating the impact and/or restoring the service to its previous condition.
- Basic principles of incident response include the following:
- Maintain a clear line of command.
- Designate clearly defined roles.
- Keep a working record of debugging and mitigation as you go.
- Declare incidents early and often.
- Key roles in an Incident Response
- Incident Commander (IC)
- the person who declares the incident typically steps into the IC role and directs the high-level state of the incident
- Commands and coordinates the incident response, delegating roles as needed.
- By default, the IC assumes all roles that have not been delegated yet.
- Communicates effectively.
- Stays in control of the incident response.
- Works with other responders to resolve the incident.
- Remove roadblocks that prevent Ops from working most effectively.
- Communications Lead (CL)
- CL is the public face of the incident response team.
- The CL’s main duties include providing periodic updates to the incident response team and stakeholders and managing inquiries about the incident.
- Operations or Ops Lead (OL)
- OL works to respond to the incident by applying operational tools to mitigate or resolve the incident.
- The operations team should be the only group modifying the system during an incident.
- Incident Commander (IC)
- Live Incident State Document
- Live Incident State Document can live in a wiki, but should ideally be editable by several people concurrently.
- This living doc can be messy, but must be functional and not usually shared with shareholders.
- Live Incident State Document is Incident commander’s most important responsibility.
- Using a template makes generating this documentation easier, and keeping the most important information at the top makes it more usable.
- Retain this documentation for postmortem analysis and, if necessary, meta analysis.
- Incident Management Best Practices
- Prioritize – Stop the bleeding, restore service, and preserve the evidence for root-causing.
- Prepare – Develop and document your incident management procedures in advance, in consultation with incident participants.
- Trust – Give full autonomy within the assigned role to all incident participants.
- Introspect – Pay attention to your emotional state while responding to an incident. If you start to feel panicky or overwhelmed, solicit more support.
- Consider alternatives – Periodically consider your options and re-evaluate whether it still makes sense to continue what you’re doing or whether you should be taking another tack in incident response.
Practice.Use the process routinely so it becomes second nature. - Change it around – Were you incident commander last time? Take on a different role this time. Encourage every team member to acquire familiarity with each role.
Postmortem
- A postmortem is a written record of an incident, its impact, the actions taken to mitigate or resolve it, the root cause(s), and the follow-up actions to prevent the incident from recurring.
- Postmortems are expected after any significant undesirable event.
- The primary goals of writing a postmortem are to ensure that the incident is documented, that all contributing root cause(s) are well understood, and, especially, that effective preventive actions are put in place to reduce the likelihood and/or impact of recurrence.
- Writing a postmortem is not punishment – it is a learning opportunity for the entire company.
- Postmortem Best PracticesBlamelessPostmortems should be Blameless.
- It must focus on identifying the contributing causes of the incident without indicting any individual or team for bad or inappropriate behavior.
- Collaborate and Share KnowledgePostmortems should be used to collaborate and share knowledge. It should e shared broadly, typically with the larger engineering team or on an internal mailing list.
- The goal should be to share postmortems to the widest possible audience that would benefit from the knowledge or lessons imparted.
- No Portmortem Left UnreviewedAn unreviewed postmortem might as well never have existed.
- OwnershipDeclaring official ownership results in accountability, which leads to action.
- It’s better to have a single owner and multiple collaborators.
Conclusions
- SRE practices require a significant amount of time and skilled SRE people to implement right
- A lot of tools are involved in day to day SRE work
- SRE processes are one of a key to the success of a tech company
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
