 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com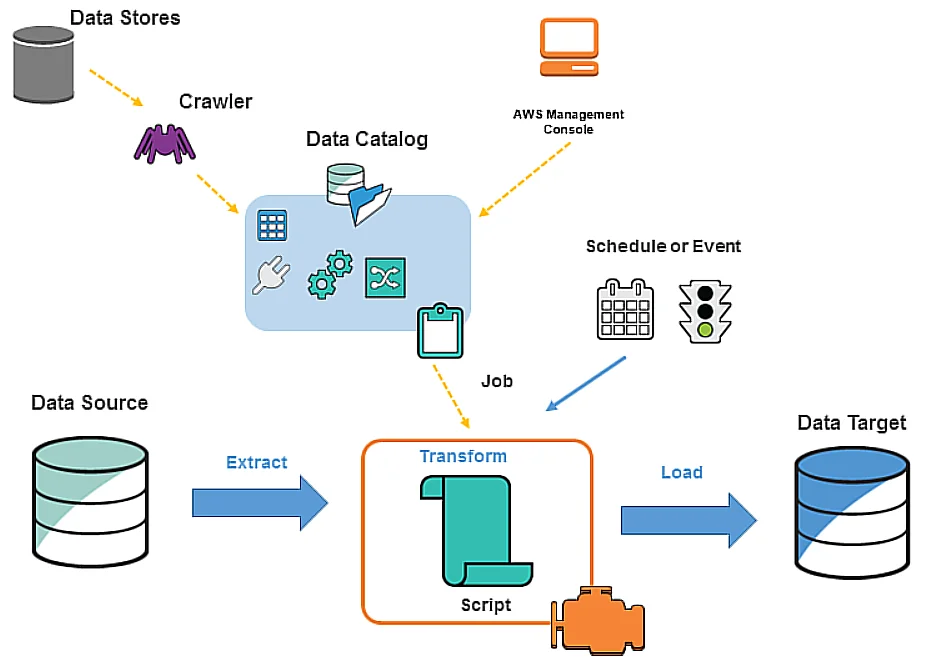
In today’s data-driven world, organizations are collecting data from a wide range of sources — websites, mobile apps, IoT devices, logs, third-party APIs, databases, and more. But collecting data is only part of the journey. The real value lies in integrating, transforming, and analyzing this data efficiently. AWS Glue is Amazon Web Services’ answer to the complex problem of data integration.
It is a fully managed, serverless ETL (Extract, Transform, Load) service that makes it easy to prepare and load data for analytics. Whether you’re building a data lake, a data warehouse, or real-time dashboards, Glue acts as a backbone for your data pipeline.
 What is AWS Glue?
What is AWS Glue?
AWS Glue is a serverless data integration service that helps you discover, prepare, clean, transform, and move data between data stores. It is designed to handle the entire ETL process in a simplified and scalable manner.
With AWS Glue, you don’t have to manage infrastructure, write complex scripts, or manually schedule jobs. It automates much of the heavy lifting, enabling developers and data engineers to focus on solving data problems rather than managing data movement.
AWS Glue supports structured, semi-structured, and unstructured data and integrates seamlessly with other AWS services like Amazon S3, Redshift, RDS, and Athena.
 Why is AWS Glue Used?
Why is AWS Glue Used?
Data in modern enterprises exists in diverse formats and disparate systems — from relational databases to cloud-based storage like S3, from CRM systems to IoT streams. Extracting and preparing this data for analytics used to be time-consuming and required heavy infrastructure.
AWS Glue simplifies and automates these processes. It is used for:
- Building Data Lakes: Ingest and catalog data stored across multiple sources into Amazon S3, making it queryable.
- Data Warehousing Pipelines: Clean and transform data before loading it into Amazon Redshift.
- Schema Discovery: Automatically infer and track data schema changes.
- Batch and Event-Driven ETL: Run ETL jobs on a schedule or based on events.
- Metadata Management: Maintain a unified Data Catalog accessible by AWS Athena, Redshift Spectrum, and EMR.
- Machine Learning Preparation: Preprocess datasets for training and inference.
It plays a critical role in data governance, data lineage, and centralized metadata management.
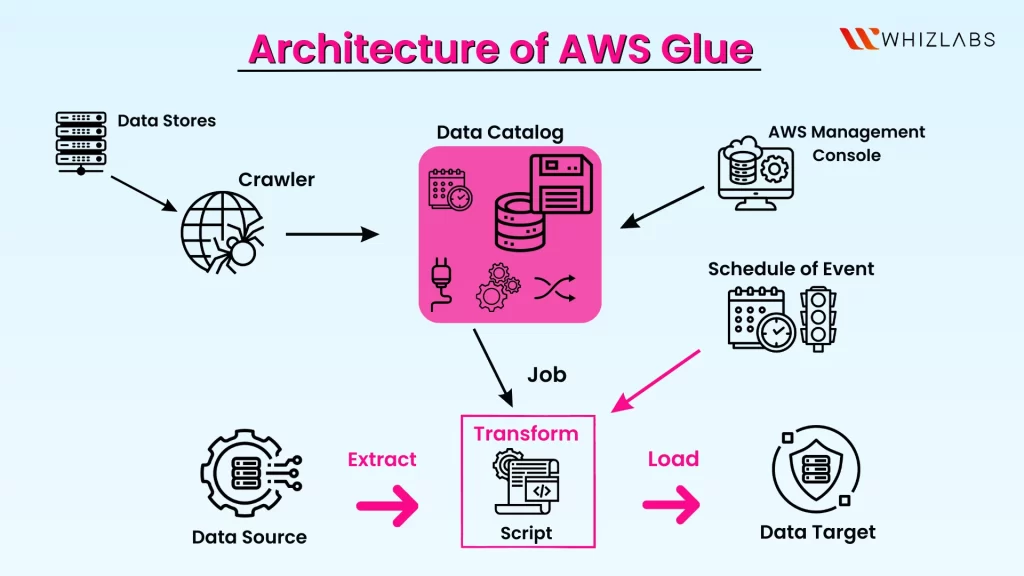
 How Does AWS Glue Work?
How Does AWS Glue Work?
At its core, AWS Glue follows a simple yet powerful flow:
- Data Discovery: Using Crawlers, Glue scans your data sources and infers the schema. It then populates the Glue Data Catalog, which is a central metadata repository.
- ETL Job Authoring:
- You can create ETL jobs using either the visual Studio (no-code/low-code interface) or write custom Python or Scala scripts using Glue’s Apache Spark engine.
- Glue generates code that extracts data from sources, applies transformations, and loads it into target systems.
- Job Execution:
- Glue runs your job on a serverless Spark cluster. No provisioning or cluster management is required.
- You can run jobs on demand, on a schedule, or triggered by events (e.g., file upload to S3).
- Monitoring and Logging:
- AWS Glue integrates with CloudWatch for logs and metrics.
- You can track job execution, errors, and performance in real time.
The combination of serverless computing, integrated metadata, and automation makes Glue one of the most efficient tools for modern data engineering.
 Key Features of AWS Glue
Key Features of AWS Glue
- Serverless: No infrastructure to manage — just focus on your ETL logic.
- Glue Data Catalog: A central metadata repository that’s compatible with Redshift, Athena, and EMR.
- Automated Schema Discovery: Crawlers detect schema and partitioning automatically.
- Visual ETL Builder: Drag-and-drop interface for building pipelines without coding.
- Job Bookmarking: Keeps track of previously processed data to avoid duplication.
- Job Triggering: Supports cron-based schedules, event-driven triggers, and workflows.
- Streaming ETL: Supports near real-time data processing using Spark Streaming.
- DataBrew: A visual, no-code data preparation tool within Glue for analysts and non-engineers.
- Glue Studio: A modern visual editor for advanced job authoring with data previews.
- Versioning and Rollback: Manage job versions, rollback to previous versions in case of failures.
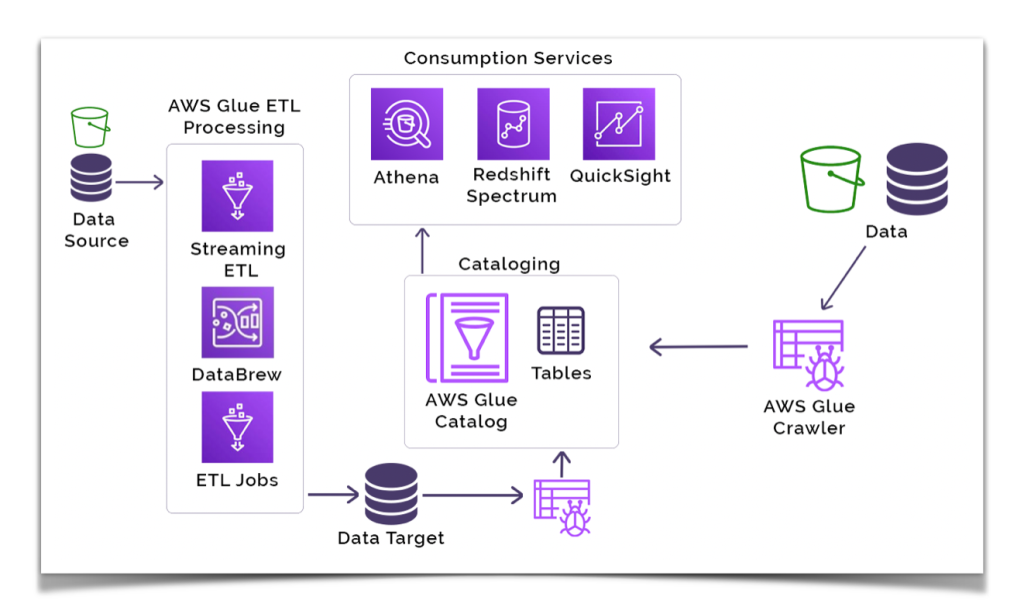
 Main Components of AWS Glue
Main Components of AWS Glue
AWS Glue is composed of several integrated components, each playing a specific role:
1. Glue Data Catalog
A metadata repository that stores table definitions, schemas, and partitions. It’s central to all operations and shared across services like Athena and Redshift.
2. Glue Crawlers
Automated jobs that scan your data sources, infer schema, and update the Glue Data Catalog.
3. Glue Jobs
The core ETL scripts that extract, transform, and load data. Jobs can be written in Python (PySpark) or Scala and run on Glue’s managed Spark engine.
4. Glue Studio
A visual interface for designing, running, and monitoring ETL jobs. It supports data preview, schema mapping, and complex transformations.
5. Glue Workflows
A way to orchestrate multiple jobs and crawlers into a dependency-based pipeline. Ideal for batch ETL and complex job chaining.
6. Glue Triggers
Defines when and how jobs should be triggered. Triggers can be time-based or event-driven.
7. Glue DataBrew
A visual data preparation tool that allows data analysts to clean and normalize data using a spreadsheet-like interface.
 When Should You Use AWS Glue?
When Should You Use AWS Glue?
Use AWS Glue if:
- You want to build a data lake on AWS and need schema discovery and ETL.
- Your data pipeline involves multiple formats (JSON, CSV, Parquet, ORC, etc.) across different storage systems.
- You need a serverless and auto-scalable data processing engine.
- You want to integrate metadata and governance into your ETL process.
- You need event-based or scheduled ETL pipelines.
- You’re preparing data for machine learning models.
- You want a cost-effective alternative to managing Spark/Hadoop clusters.
AWS Glue is ideal for enterprises looking to automate data engineering without investing heavily in infrastructure or managing complex tools.
 Benefits of Using AWS Glue
Benefits of Using AWS Glue
- Reduces Time to Value: Rapidly ingest, prepare, and deliver data.
- No Infrastructure Overhead: Everything runs in a serverless environment.
- Integration with AWS Ecosystem: Works seamlessly with Athena, S3, Redshift, and Lake Formation.
- Cost-Effective: Pay only for the compute resources used during job execution.
- Highly Scalable: Automatically scales to handle large volumes of data.
- Unified Metadata Management: Central catalog accessible across tools.
- Flexible Job Authoring: Use visual tools or script-based development as needed.
- Built-In Governance: Combined with AWS Lake Formation for access control and auditing.
 Limitations or Challenges of AWS Glue
Limitations or Challenges of AWS Glue
Despite its many advantages, AWS Glue comes with certain limitations:
- Cold Start Latency: Jobs may take a minute or two to start due to Spark initialization.
- Learning Curve: Spark concepts may be challenging for teams unfamiliar with distributed processing.
- Debugging Complexity: Debugging Spark jobs in a serverless environment can be more difficult than in local environments.
- Cost Predictability: While serverless, Glue can become expensive with complex, long-running jobs.
- Limited UI for Advanced Logic: Visual tools are great for beginners but may be limiting for complex ETL flows.
- Streaming ETL Latency: Not truly real-time; best suited for near real-time (few seconds delay).
Understanding these limitations helps teams plan and design better data pipelines.
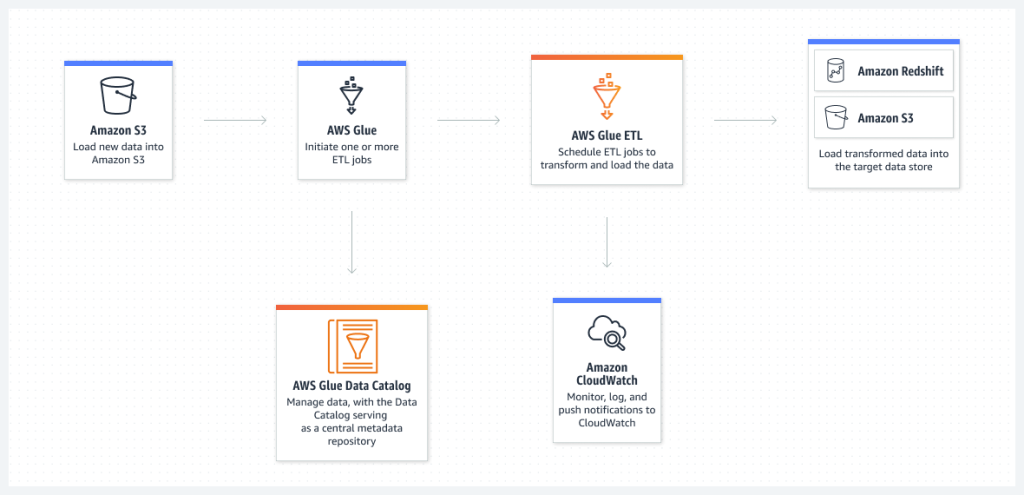
 How to Get Started with AWS Glue
How to Get Started with AWS Glue
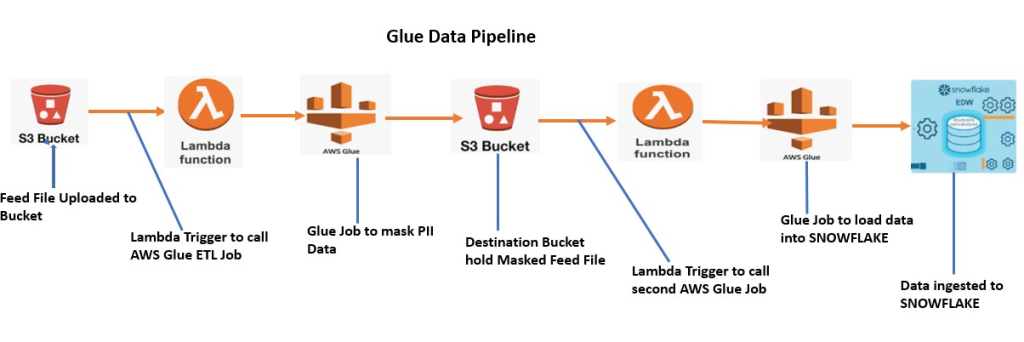
Step 1: Define Your Data Sources and Targets
Know where your data resides (e.g., S3, RDS) and where you want it delivered (e.g., Redshift, S3, or SQS).
Step 2: Create a Glue Crawler
Set up a crawler to scan your data and populate the Glue Data Catalog with metadata.
Step 3: Author a Glue Job
Use Glue Studio or script editor to create a job that reads from the catalog, transforms the data, and writes to the destination.
Step 4: Configure Triggers
Schedule the job or trigger it based on an event such as file upload or completion of another job.
Step 5: Monitor Jobs
Use AWS Glue Console and CloudWatch to monitor execution, debug errors, and tune performance.
This setup allows you to create powerful pipelines with minimal engineering effort.
 Alternatives to AWS Glue
Alternatives to AWS Glue
While AWS Glue is a versatile ETL tool, there are several alternatives depending on your specific needs:
| Tool | Description |
|---|---|
| Apache Airflow (Amazon MWAA) | For complex workflows and DAG-based orchestration. |
| Apache Spark on EMR | For high-performance, custom Spark jobs with full control. |
| AWS Data Pipeline | Legacy AWS service for batch workflows. |
| Talend | Enterprise-grade data integration platform with a graphical interface. |
| Fivetran / Stitch | SaaS tools for plug-and-play ETL from various SaaS data sources. |
| Databricks | Powerful for data science, ML, and collaborative analytics on top of Spark. |
Each has pros and cons, but Glue is a top choice for those deeply embedded in the AWS ecosystem.
 Real-World Use Cases and Success Stories
Real-World Use Cases and Success Stories
1. E-commerce Company
A large retailer uses Glue to extract product and customer data from different systems, standardize it, and load it into Redshift for sales analytics and inventory forecasting.
2. Healthcare Provider
A healthcare organization integrates patient data from EMRs, insurance platforms, and IoT devices into a unified data lake for population health analytics.
3. Media Streaming Platform
Processes user activity logs from streaming apps, transforms them using Glue, and powers recommendation systems using the cleaned data.
4. Banking and Finance
Processes financial transaction logs, applies fraud detection rules in ETL jobs, and loads the results into dashboards for real-time fraud alerts.
5. Education and EdTech
Cleans and aggregates student interaction data across LMS platforms to personalize learning paths and monitor student engagement.
 Conclusion
Conclusion
AWS Glue is a foundational service in building modern, serverless data platforms. With its ability to automate ETL, integrate metadata, and scale on-demand, it helps organizations convert raw data into actionable insights with minimal engineering effort.
From startups looking for rapid ETL solutions to large enterprises needing unified data governance, Glue is versatile, reliable, and future-ready. As data continues to grow in volume and complexity, AWS Glue offers a way to simplify and accelerate your data transformation journey.
Whether you are building data lakes, preparing datasets for machine learning, or powering BI dashboards, AWS Glue provides the tools you need — all within a secure, scalable, and serverless environment.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
