
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com
The PyTorch is a library for Python programs that eases building deep learning projects. We like Python because is easy to read and understand. The PyTorch highlights flexibility and allows deep learning models to be expressed in idiomatic Python.

In simple words, think about Numpy, but with strong GPU acceleration. Well yet, the PyTorch supports dynamic computation graphs that allow you to change how the network behaves on the fly, unlike static graphs that are used in frameworks such as Tensorflow.

Interview Questions and Answers for Pytorch:-
1) What is PyTorch?
The PyTorch is a part of computer software based on torch library, which is an open-source Machine learning library for Python. It is a deep learning framework which was developed by the Facebook artificial intelligence research group. It is used for the application such as Natural Language Processing and Computer Vision.
2) What are the essential elements of PyTorch?
There are the following elements which are essential in PyTorch:
- PyTorch tensors
- PyTorch NumPy
- Mathematical operations
- Autograd Module
- Optim Module
- nn Module
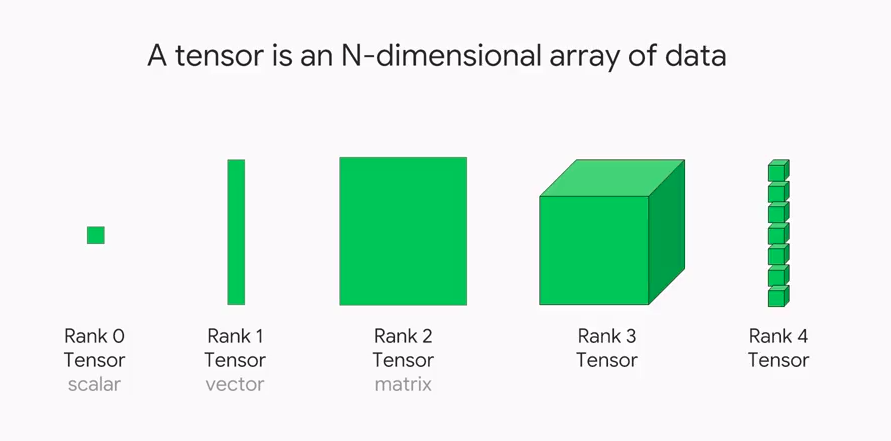
3) What is Tensors?
Tensors play an important role in deep learning with PyTorch. In simple words, we can say, this framework is completely based on tensors. A tensor is treated as a generalized matrix. It could be a 1D tensor (vector), 2D tensor (matrix), 3D tensor (cube) or 4D tensor (cube vector).
4) What is the levels of abstraction?
There are three levels of abstraction, which are as follows:
- Tensor: Tensor is an imperative n-dimensional array which runs on GPU.
- Variable: It is a node in the computational graph. This stores data and gradient.
- Module: Neural network layer will store state the otherwise learnable weight.
5) Are tensor and matrix the same?
We can’t say that tensor and matrix are the same. Tensor has some properties through which we can say both have some similarities such as we can perform all the mathematical operation of the matrix in tensor.
A tensor is a mathematical entity which lives in a structure and interacts with other mathematical entity. If we transform the other entities in the structure in a regular way, then the tensor will obey a related transformation rule. This dynamical property of tensor makes it different from the matrix.
6) What is the use of torch.from_numpy()?
The torch.from_numpy() is one of the important property of torch which places an important role in tensor programming. It is used to create a tensor from numpy.ndarray. The ndarray and return tensor share the same memory. If we do any changes in the returned tensor, then it will reflect the ndaaray also.
7) What is variable and autograd.variable?
Variable is a package which is used to wrap a tensor. The autograd.variable is the central class for the package. The torch.autograd provides classes and functions for implementing automatic differentiation of arbitrary scalar-valued functions. It needs minimal changes to the existing code. We only need to declare tensor for which gradients should be computed with the requires_grad=True keyword.
8) How do we find the derivatives of the function in PyTorch?
The derivatives of the function are calculated with the help of the Gradient. There are four simple steps through which we can calculate derivative easily.
These steps are as follows:
- Initialization of the function for which we will calculate the derivatives.
- Set the value of the variable which is used in the function.
- Compute the derivative of the function by using the backward () method.
- Print the value of the derivative using grad.
9) What do you mean by Linear Regression?
Linear Regression is a technique or way to find the linear relation between the dependent variable and the independent variable by minimizing the distance. It is a supervised machine learning approach which is used for classification of order discrete category.
10) What is Loss Function?
The loss function is bread and butter for machine learning. It is quite simple to understand and used to evaluate how well our algorithm models our dataset. If our prediction is completely off, then the function will output a higher number else it will output a lower number.
11) What is the use of MSELoss, CTCLoss, and BCELoss function?
MSE stands for Mean Squared Error, which is used to create a criterion the measures the mean squared error between each element in an input x and target y. The CTCLoss stands for Connectionist Temporal Classification Loss, which is used to calculate the loss between continuous time series and target sequence. The BCELoss(Binary Cross Entropy) is used to create a criterion to measures the Binary Cross Entropy between the target and the output.
12) Give any one difference between torch.nn and torch.nn.functional?
The torch.nn provide us many more classes and modules to implement and train the neural network. The torch.nn.functional contains some useful function like activation function and convolution operation, which we can use. However, these are not full layers, so if we want to define a layer of any kind, we have to use torch.nn.
13) What do you mean by Mean Squared Error?
The mean squared error tells us about how close a regression line to a set of points. Mean squared error done this by taking the distance from the points to the regression line and squaring them. Squaring is required to remove any negative signs.
14) What is perceptron?
Perceptron is a single layer neural network, or we can say a neural network is a multi-layer perceptron. Perceptron is a binary classifier, and it is used in supervised learning. A simple model of a biological neuron in an artificial neural network is known as Perceptron.
15) What is Activation function?
A neuron should be activated or not, is determined by an activation function. The Activation function calculates a weighted sum and further adding bias with it to give the result. The Neural Network is based on the Perceptron, so if we want to know the working of the neural network, then we have to learn how perceptron work.
16) How Neural Network differs from Deep Neural Network?
Neural Network and Deep Neural Network both are similar and do the same thing. The difference between NN and DNN is that there can be only one hidden layer in the neural network, but in a deep neural network, there is more than one hidden layer. Hidden layers play an important role to make an accurate prediction.
17) Why it is difficult for the network is showing the problem?
Ann works with numerical information, and the problems are translated into numeric values before being introduced to ANN. This is the reason by which it is difficult to show the problem to the network.
18) Why we used activation function in Neural Network
To determine the output of the neural network, we use the Activation Function. Its main task is to do mapping of resulting values in between 0 to 1 or -1 to 1 etc. The activation functions are basically divided into two types:
- Linear Activation Function
- Non-linear Activation Function
19) Why we prefer the sigmoid activation function rather than other function?
The Sigmoid Function curve looks like S-shape and the reason why we prefer sigmoid rather than other is the sigmoid function exists between 0[Ma1] to 1. This is especially used for the models where we have to predict the probability as an output.
20) What do you mean by Feed-Forward?
“Feed-Forward” is a process through which we receive an input to produce some kind of output to make some kind of prediction. It is the core of many other important neural networks such as convolution neural network and deep neural network. /p>
In the feed-forward neural network, there are no feedback loops or connections in the network. Here is simply an input layer, a hidden layer, and an output layer.
21) What is the difference between Conv1d, Conv2d, and Conv3d?
There is no big difference between the three of them. The Conv1d and Conv2D is used to apply 1D and 2D convolution. The Conv3D is used to apply 3D convolution over an input signal composed of several input planes.
22) What do you understand from the word Backpropagation?
“Backpropagation” is a set of algorithm which is used to calculate the gradient of the error function. This algorithm can be written as a function of the neural network. These algorithms are a set of methods which are used to efficiently train artificial neural networks following a gradient descent approach which exploits the chain rule.
23) What is Convolutional Neural Network?
Convolutional Neural Network is the category to do image classification and image recognition in neural networks. Face recognition, scene labeling, objects detections, etc., are the areas where convolutional neural networks are widely used. The CNN takes an image as input, which is classified and process under a certain category such as dog, cat, lion, tiger, etc.
24) What is the difference between DNN and CNN?
The deep neural network is a kind of neural network with many layers. “Deep” means that the neural network has a lot of layers which looks deep stuck of layers in the network. The convolutional neural network is another kind of deep neural network. The Convolutional Neural Network has a convolution layer, which is used filters to convolve an area in input data to a smaller area, detecting important or specific part within the area. The convolution can be used on the image as well as text.
25) What are the advantages of PyTorch?
There are the following advantages of Pytorch:
- PyTorch is very easy to debug.
- It is a dynamic approach for graph computation.
- It is very fast deep learning training than TensorFlow.
- It increased developer productivity.
- It is very easy to learn and simpler to code.
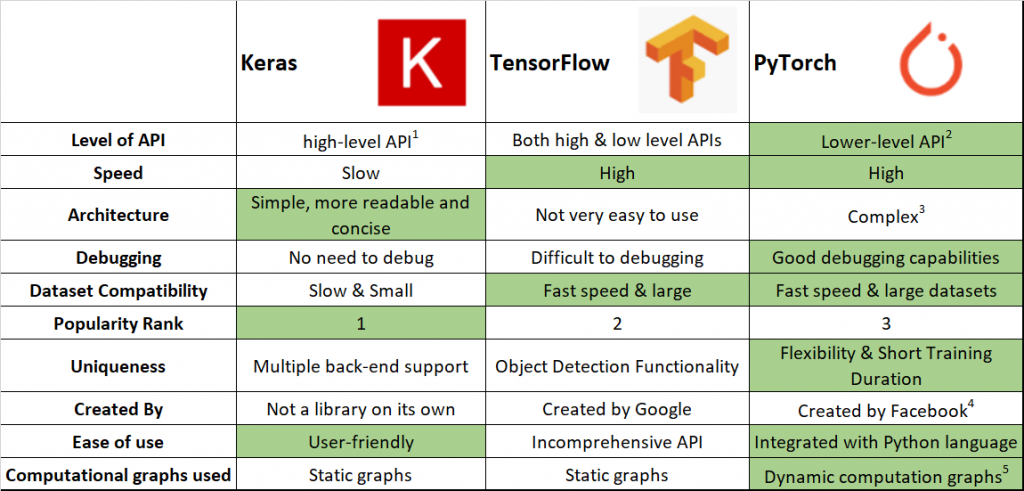
26) What is the difference between PyTorch and TensorFlow?
27) Give any one difference between batch, stochastic, and mini-batch gradient descent?
- Stochastic Gradient Descent: In SGD, we use only a single training example for calculation of gradient and parameters.
- Batch Gradient Descent: In BGD, we calculate the gradient for the whole dataset and perform the updating at each iteration.
- Mini-batch Gradient Descent: Mini-batch Gradient Descent is a variant of Stochastic Gradient Descent. In this gradient descent, we used mini-batch of samples instead of a single training example.
28) What is auto-encoder?
It is a self-government machine learning algorithm which uses the backpropagation principle, where the target values are equal to the inputs provided. Internally, it has a hidden layer which manages a code used to represent the input.
29) What is Autograd module in PyTorch?
The Autograd module is an automatic differentiation technique which is used in PyTorch. It is more powerful when we are building a neural network. There is a recorder which records each operation which we have performed, and then it replays it backs to compute our gradient.
30) What is the optim module in PyTorch?
Torch.optim is a module which implements various optimization algorithm which is used for building neural networks. Below is the code of Adam optimizer
Optimizer = torch.optim.Adam(mode1, parameters( ), lr=learning rate
31) What is nn module in PyTorch?
PyTorch provides the torch.nn module to help us in creating and training of the neural network. We will first train the basic neural network on the MNIST dataset without using any features from these models. The torch.nn provide us many more classes and modules to implement and train the neural network.
32) What is the command to install PyTorch in windows using Conda and pip?
Using Conda: conda install pytorch cudatoolkit=10.0 -c pytorch-nightly
Using pip: pip install torch -f https://download.pytorch.org/whl/nightly/cpu/torch.html
33) What is torch.cuda?
The torch.cuda is a package which adds support for CUDA tensor type. CUDA tensor type implements the same function as CPU tensor but utilizes the GPU for computation.
34) What is the difference between Type1 and Type2 error?
Type 1 error is the false positive value, and the Type 2 error is a false negative value. Type I error represent when something is happening. Type II errors are describing that there nothing is wrong where something is not right.
35) Why use PyTorch for Deep learning?
In Deep learning tools, PyTorch plays an important role, and it is a subset of machine learning, and its algorithm works on the human brain. There are the following reason for which we prefer PyTorch:
- PyTorch allows us to define our graph dynamically.
- PyTorch is great for deep earning research and provides maximum flexibility and speed.
36) What is the attributes of Tensor?
Each torch.Tensor has a torch.device, torch.layout, and torch.dtype. The torch.dtype defines the data type, torch.device represents the device on which a torch.Tensor is allocated, and torch.layout represents the memory layout of a torch.Tensor.
37) What is the difference between Anaconda and Miniconda?
Anaconda is a set of hundreds of packages including conda, numpy, scipy, ipython notebook, and so on. Miniconda is a smaller alternative to anaconda.
38) How do we check GPU usage?
There are the following steps to check GPU usage:
- Use the window key + R to open the run command.
- Type the dxdiag.exe command and press enter to open DirectXDiagnostic Tool.
- Click on the Display tab.
- Under the drivers, on the right side, check the Driver model information.
39) What is the MNIST dataset?
The MNIST dataset is used in Image Recognition. It is a database of various handwritten digits. The MNIST dataset has a large amount of data which is commonly used to demonstrate the true power of deep neural networks.
40) What is the CIFAR-10 dataset?
It is a collection of the color image which is commonly used to train machine learning and computer vision algorithms. The CIFAR 10 dataset contains 50000 training images and 10000 validation images such that the images can be classified between 10 different classes.
41) What is the difference between CIFAR-10 and CIFAR-100 dataset?
The CIFAR 10 dataset contains 50000 training images and 10000 validation images such that the images can be classified between 10 different classes. On the other hand, CIFAR-100 has 100 classes, which contain 600 images per class. There are 100 testing images and 500 training images per class.
42) What do you mean by convolution layer?
Convolution layer is the first layer in Convolutional Neural Network. It is the layer to extract the features from an input image. It is a mathematical operation which takes two inputs such as image matrix and a kernel or filter.
43) What do you mean by Stride?
Stride is the number of pixels which are shift over the input matrix. We move the filters to 1 pixel at a time when the stride is equaled to 1.
44) What do you mean by Padding?
“Padding is an additional layer which can add to the border of an image.” It is used to overcome the
Shrinking outputs
Losing information on the corner of the image.
45) What is pooling layer.
Pooling layer plays a crucial role in pre-processing of an image. Pooling layer reduces the number of parameters when the images are too large. Pooling is “downscaling” of the image which is obtained from the previous layers.
46) What is Max Pooling?
Max pooling is a sample-based discrete process whose main objective is to reduce its dimensionality, downscale an input representation. And allow for the assumption to be made about features contained in the sub-region binned.
47) What is Average Pooling?
Down-scaling will perform through average pooling by dividing the input into rectangular pooling regions and will compute the average values of each region.
48) What is Sum Pooling?
The sub-region for sum pooling or mean pooling will set the same as for max-pooling but instead of using the max function we use sum or mean.
49) What do you mean by fully connected layer?
The fully connected layer is a layer in which the input from the other layers will be flattened into a vector and sent. It will transform the output into the desired number of classes by the network.
50) What is the Softmax activation function?
The Softmax function is a wonderful activation function which turns numbers aka logits into probabilities which sum to one. Softmax function outputs a vector which represents the probability distributions of a list of potential outcomes.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
