
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com
Short description about FluentD
Fluentd is an open-source data collector, which lets you unify the data collection and consumption for better use and understanding of data.
Moving to the questions and answers
1. What is Fluentd?
Answer: Fluentd is an open-source data collector, which lets you unify the data collection and consumption for better use and understanding of data.
2. Why do we need Fluentd?
Answer: Fluentd decouples data sources from backend systems by providing a unified logging layer in between. This layer allows developers and data analysts to utilize many types of logs as they are generated. Just as importantly, it mitigates the risk of “bad data” slowing down and misinforming your organization.
3. What is a Fluentd log?
Answer: Fluentd is an open-source data collector for a unified logging layer. Fluentd allows you to unify data collection and consumption for better use and understanding of data.
4. What is Fluentd and how does it work?
Answer: Fluentd scraps logs from a given set of sources, processes them (converting into a structured data format), and then forwards them to other services like Elasticsearch, object storage etc. Fluentd is especially flexible when it comes to integrations – it works with 300+ log storage and analytic services.
5. What is a Fluentd TD agent?
Answer: Treasure Agent (td-agent) is a stable distribution package of Fluentd, which is maintained by Treasure Data and the Cloud Native Computing Foundation. Before Installation. Install or Upgrade td-agent.
6. What is Fluentd in Kubernetes?
Answer: Fluentd is a popular open-source data collector that we’ll set up on our Kubernetes nodes to tail container log files, filter and transform the log data, and deliver it to the Elasticsearch cluster, where it will be indexed and stored.
7. What is Fluentd open source?
Answer: Fluentd is an open-source data collector that unifies data collection and consumption for better use and understanding. … With 650+ plugins connecting it to many data sources and data outputs, it is no wonder Fluentd was the 2016 Bossie Awards winner for the best open source datacenter and cloud software.
8. Where are Fluentd logs stored?
Answer:
/var/log/
Look at Logs
For td-agent (rpm/deb), the logs are located at /var/log/td-agent/td-agent. log .
9. How do I set up Fluentd Kubernetes?
Answer:
Step 1: Grant Permissions to Fluentd. Fluentd will be collecting logs both from user applications and cluster components such as Kube-apiserver and kube-scheduler , so we need to grant it some permissions.
Step 2: Deploy a DaemonSet.
10. Who owns Fluentd?
Answer:
Treasure Data
It is written primarily in the Ruby programming language.
…
Fluentd.
Developer(s) Treasure Data
Stable release 1.12.1 / February 18, 2021
Repository github.com/fluent/fluentd
Written in C, Ruby
11. How do I connect to Elasticsearch fluent?
Answer: Setup: Fluentd Aggregator (runs on the same machine as the Elasticsearch) To set up Fluentd (on Ubuntu Precise), run the following command. Since secure-forward uses port 24284 (tcp and udp) by default, make sure the aggregator server has port 24284 accessible by node servers.
12. How can I upgrade my fluency?
Answer: Upgrade steps
- Review what plugins are installed together with td-agent v3. …
- Stop td-agent v3 daemon. …
- Run installation script of td-agent v4. …
- Confirm if td-agent v4 is properly installed. …
- Reload td-agent daemon. …
- Check installed plugins. …
- Install plugins added on my own. …
- Start td-agent v4 daemon
13. What is Fluentd in OpenShift?
Answer: OpenShift Container Platform uses Fluentd to collect operations and application logs from your cluster and enriches the data with Kubernetes pod and project metadata. You can configure the CPU and memory limits for the log collector and move the log collector pods to specific nodes. … log.
14. Is lightweight fluent?
Answer: Lightweight. It has been designed as a lightweight solution with high performance in mind. From a design perspective, it’s fully asynchronous (event-driven) and takes the most of the operating systems API for performance and reliability.
15. What is the latest version of Fluentd?
Answer: Fluentd v1. 14.2 has been released
- 2021-10-29.
- ClearCode, Inc.
16. What does TD-agent do?
Answer: The event collector daemon, for Treasure Data. This daemon collects various types of logs/events in various way, and transfer them to the cloud. For more about Treasure Data, see the homepage, and the documentation. td-agent is open-sourced as fluentd project.
17. How do I get rid of TD-agent?
Answer: Uninstall td-agent from RedHat/CentOS
- uninstall td-agent package. sudo yum remove td-agent.
- remove treasure data rpm-imported gpg key. sudo rpm -e –allmatches gpg-pubkey-ab97acbe-586223cc.
- delete Treasure Data yum repo. sudo rm /etc/yum.repos.d/td.repo.
18. How do you troubleshoot fluently?
Answer: Troubleshooting Fluentd
- Check Fluentd pod status (statefulset) …
- ConfigCheck. …
- Check Fluentd configuration. …
- Set Fluentd log Level. …
- Get Fluentd logs. …
- Set stdout as an output. …
- Check the buffer path in the fluentd container. …
- Getting Support.
19. How do you say fluent?
Answer: It is pronounced as fluent-dee. Like “fluent” with a “d” tacked onto it. Fluentd is called Fluentd because it wasn’t called Fluentd on day one.
20. What is fluent Bit?
Answer: Fluent Bit is a lightweight log processor and forwarder that allows you to collect data and logs from different sources, unify them, and send them to multiple destinations.
21. What is TD agent Bit?
Answer: Fluent Bit/td-agent-bit is an open-source and multi-platform Log Processor and Forwarder which allows you to collect data/logs from different sources, unify and send them to multiple destinations.
22. How do I reset my TD agent?
Answer: By using sudo systemctl restart td-agent will restart the file at the default location. If started by td-agent -c configuration. conf only way to restart is first press ctrl+c to stop and then again restart using the same command.
23. What is the difference between Logstash and Filebeat?
Answer: The important difference between Logstash and Filebeat is their functionalities, and Filebeat consumes fewer resources. But in general, Logstash consumes a variety of inputs, and the specialized beats do the work of gathering the data with minimum RAM and CPU.
24. What is a Fluentd sidecar?
Answer: Use of a Fluentd sidecar to forward logs on stdout
The solution to collect the application logs, stored in a file, is to use a sidecar. It reads the logs file and streams its contents on its own stdout. … The sidecar in the solution is a Fluentd container that is deployed inside the same pod as the application.
25. What is Fluentd DaemonSet?
Answer: Fluentd DaemonSet
For Kubernetes, a DaemonSet ensures that all (or some) nodes run a copy of a pod. In order to solve log collection, we are going to implement a Fluentd DaemonSet.
26. What is the difference between Logstash and Fluentd?
Answer: Both log collectors support routing, but their approaches are different. Logstash routes all data into a single stream and then uses algorithmic if-then statements to send them to the correct destination. Fluentd uses tags to route events. Each Fluentd event has a tag that tells Fluentd where it needs to be routed.
27. What is Pos_file in Fluentd?
Answer: Fluentd will record the position it last read from this file: 1. pos_file /var/log/td-agent/tmp/access.log.pos. Copied! pos_file handles multiple positions in one file so no need to have multiple pos_file parameters per source .
28. What is Calyptia Fluentd?
Answer: Fluentd is an extremely popular open-source project that is a graduated project part of the cloud-native computing foundation (CNCF). Calyptra Fluentd is a new distribution of Fluentd that includes more metric-focused features, along with packages optimized for performance and integration with more services.
29. How do you check log fluent?
Answer: Fluentd marks its own logs with the fluent tag. You can process Fluentd logs by using (Of course, ** captures other logs) in. If you define in your configuration, then Fluentd will send its own logs to this label.
30. How do I send Docker logs fluent?
Answer:
Using the Docker logging mechanism with Fluentd is a straightforward step, to get started make sure you have the following prerequisites: A basic understanding of Fluentd.
Step 1: Create the Fluentd configuration file.
Step 2: Start Fluentd.
Step 3: Start Docker container with Fluentd driver.
Step 4: Confirm.
31. How does Prometheus work in Kubernetes?
Answer: Monitoring Kubernetes Cluster with Prometheus. Prometheus is a pull-based system. It sends an HTTP request, a so-called scrape, based on the configuration defined in the deployment file. The response to this scrape request is stored and parsed in storage along with the metrics for the scrape itself.
32. Who uses Fluentd?
Answer: 166 companies reportedly use Fluentd in their tech stacks, including Alibaba Travels, deleokorea, and ViaVarejo.
33. why Fluentd
Answer: Fluentd decouples data sources from backend systems by providing a unified logging layer in between. This layer allows developers and data analysts to utilize many types of logs as they are generated. Just as importantly, it mitigates the risk of “bad data” slowing down and misinforming your organization.
34. I wrote a new plugin. How to add this plugin to plugin page?
Answer: Our script updates a plugin page periodically and this script collects the information of fluent-plugin-xxx gems. If you want to add your gem on plugin page, release it as fluent-plugin-xxx, not fluentd-plugin-xxx, fluent-xxx-plugin and etc.
35. Does Fluentd run on Windows?
Answer: Yes, fluentd supports Windows since v0.14. Check download page.
36. What are the differences between Fluentd and Fluent Bit?
Answer:

37. Is Fluentd better than Logstash?
Answer: FluentD and Logstash are both open-source data collectors used for Kubernetes logging. Logstash is centralized while FluentD is decentralized. FluentD offers better performance than Logstash.
38. What is Fluentbit used for?
Answer: Fluent Bit is a fast and lightweight log processor, stream processor, and forwarder for Linux, OSX, Windows, and BSD family operating systems. Its focus on performance allows the collection of events from different sources and the shipping to multiple destinations without complexity.
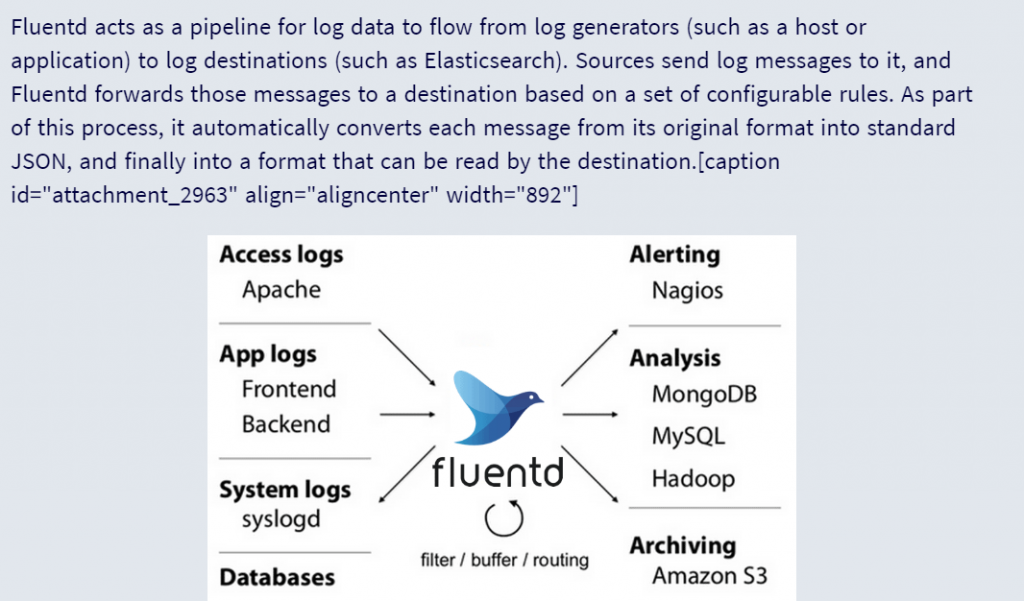
39. How Fluentd Works
Answer:
40. The Advantages of Fluentd
Answer: The main strength of Fluentd is that it’s both source and destination agnostic. As long as your service has a relevant Fluentd plugin (of which there are hundreds), you can immediately begin transferring logs to or from it. Since it converts all incoming logs into standard JSON, it can connect any supported log source to any supported log destination. Fluentd also supports some stream manipulation capabilities including log parsing, conversion, and data processing. You can define custom log formats, apply custom labels to individual messages for advanced filtering, and inject or remove fields. While it doesn’t support complex processing, you can integrate it with stream processing software such as Norikra and Amazon Kinesis. It is also lightweight, requiring only 40MB of RAM. There is an even lighter version called Fluent Bit that removes much of its functionality, but only requires around 450KB of RAM. Fluent Bit only has around 30 plugins compared to Fluentd’s 600+, but it supports many common log types and destinations including Elasticsearch, Splunk, InfluxDB, HTTP, and local files.
41. what are the Disadvantages of Fluentd
Answer: One of its main challenges is performance. While much of Fluentd is written in C, its plugin framework is written in Ruby. This adds flexibility, but at the cost of speed; on standard hardware, each Fluentd instance can only process around 18,000 events per second. You could enable multi-process workers to increase throughput, but this may cause problems with plugins that don’t support this feature. As an open-source product, it requires installation and setup before it can be used. There are community-created Deployments for quickly deploying a generic Fluentd instance to Docker or Kubernetes, but these must be configured, tested, and maintained for your specific requirements and infrastructure. Enterprise support is only available for customers of Treasure Data, the maintainers of Fluentd. All other support options must go through public channels. Lastly, it adds an intermediate layer between your log sources and log destinations. This can slow down your logging pipeline, causing backups if your sources generate events faster than Fluentd can parse, process, and forward them. While it provides some additional buffering, it will drop new events once the buffer is full.
42. How Fluentd Compares to LogDNA
Answer: Fluentd and LogDNA both handle log ingestion, aggregation, and routing between services. However, LogDNA provides a number of benefits.
43. Is Fluentd better than Logstash?
Answer: FluentD and Logstash are both open-source data collectors used for Kubernetes logging. Logstash is centralized while FluentD is decentralized. FluentD offers better performance than Logstash.
44. Can Fluentd send logs to Logstash?
Answer: Ship Fluentd events
Fluentd is an open-source data collector which can be used to collect event logs from multiple sources. It filters, buffers, and transforms the data before forwarding to one or more destinations, including Logstash.
45. How does Fluentd works in Kubernetes?
Answer: Fluentd as Kubernetes Log Aggregator
To collect logs from a K8s cluster, fluentd is deployed as a privileged daemonset. That way, it can read logs from a location on the Kubernetes node. Kubernetes ensures that exactly one fluentd container is always running on each node in the cluster.
46. How can I start fluent?
Answer:
Step1: Installing Fluentd
Install Fluentd by RPM package (Redhat Linux)
Install Fluentd by Deb package (Ubuntu/Debian Linux)
Install Fluentd by DMG package (Mac OS X)
Install Fluentd by Ruby Gem
Install Fluentd by Chef
Install Fluentd from source
47. Resilience and Reliability of FluentD
Answer: In Kubernetes, using the default docker json-file log driver already provides a measure of on-disk buffering for ephemeral containers. When Fluent-bit is tailing those files, the recommended option is to use an SQLite database file can be used so the plugin can have a history of tracked files and a state of offsets. This is very useful to resume the state if the service is restarted. You may specify a retry limit for shipping logs to different outputs (including False which will retry forever).
In order to avoid backpressure, Fluent Bit implements a mechanism in the engine that restricts the amount of data that an input plugin can ingest, this is done through the configuration parameter Mem_Buf_Limit.
48. Why We Chose Fluentd Over Fluent Bit
Answer:

49. What is the difference between Logstash and Fluentd?
Answer: Both log collectors support routing, but their approaches are different. Logstash routes all data into a single stream and then uses algorithmic if-then statements to send them to the correct destination. Fluentd uses tags to route events. Each Fluentd event has a tag that tells Fluentd where it needs to be routed.
50. Does Fluentd use Logstash?
Answer: Both Fluentd and Logstash use the Prometheus exporter to collect container metrics. or this. Logstash, as part of the ELK stack, also uses MetricBeat.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
