
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comWhat Is Data Science?
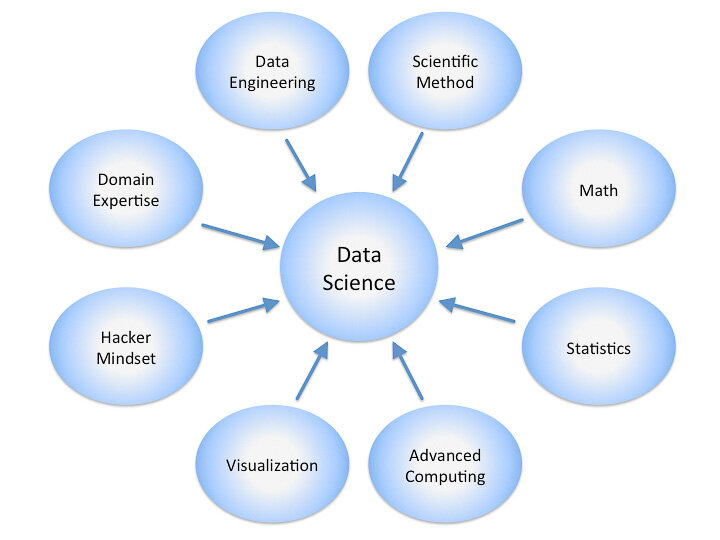
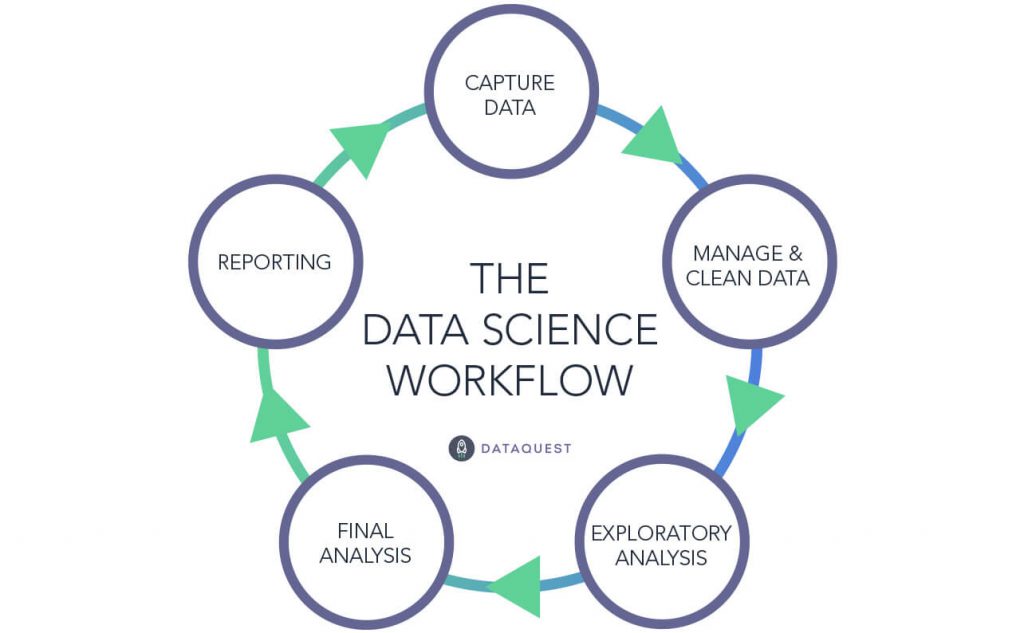
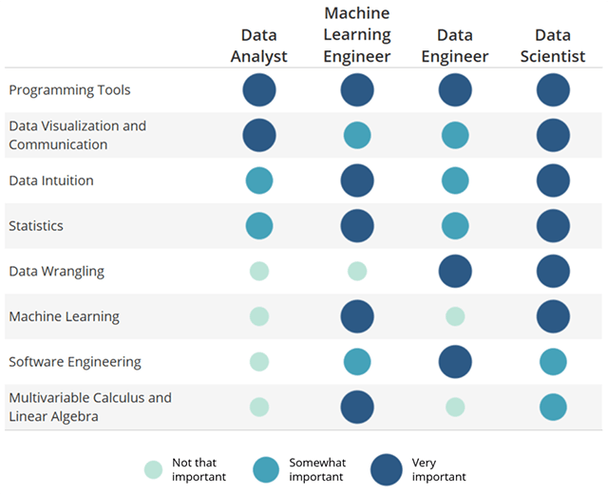
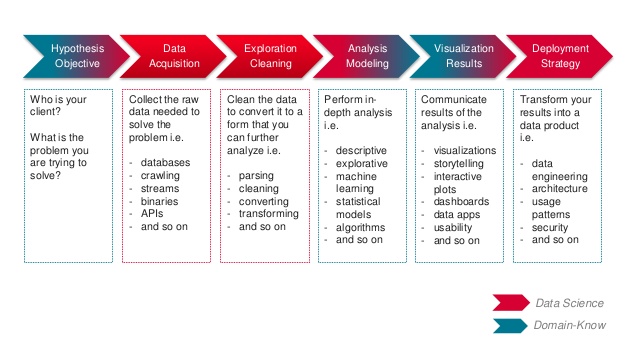
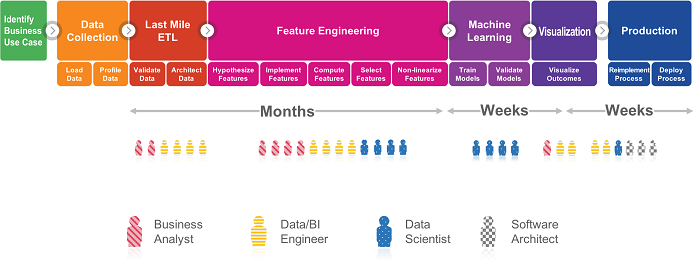
Data science is an inter-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data. Data science is related to data mining, machine learning and big data.
1 

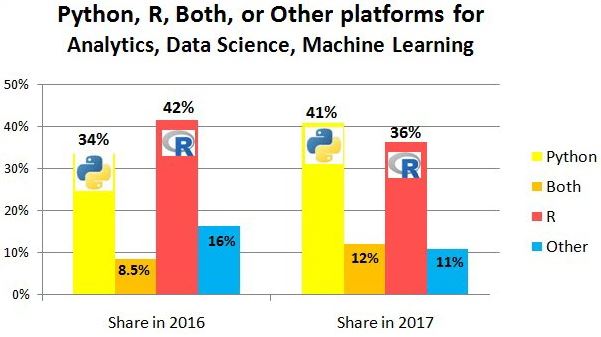
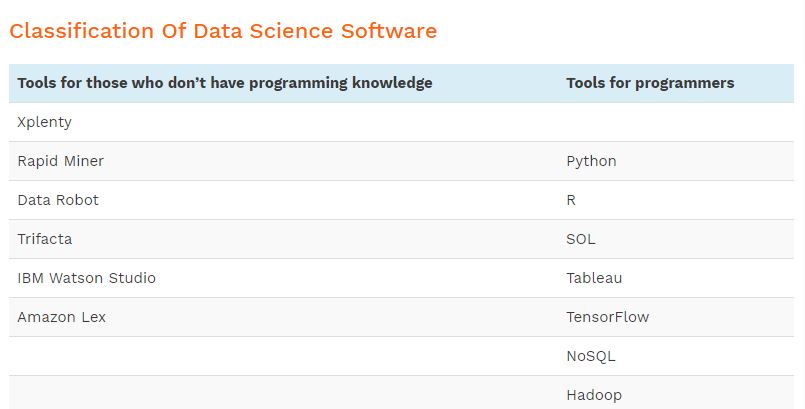

Top Languages for Data Science
- R
- Python
- SQL
R Packages
- Tidyverse
- ggplot2
- R Markdown
- Shiny
- mlr
Python Libraries
- pandas
- NumPy
- Matplotlib
- Scikit-Learn
- Tensorflow
Top Software for Data Science
- Google Sheets
- RStudio Desktop
- Jupyter Notebook
- Anaconda
Top Software for Data Science
- Google Sheets
- RStudio Desktop
- Jupyter Notebook
- Anaconda
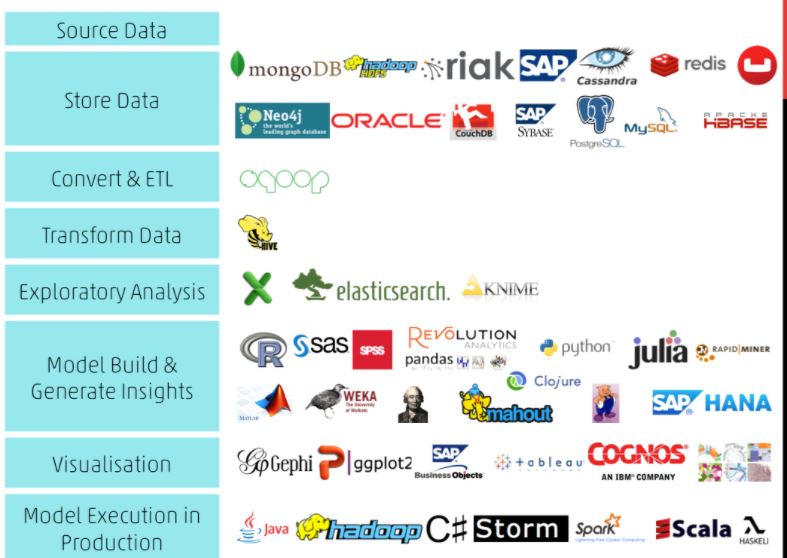
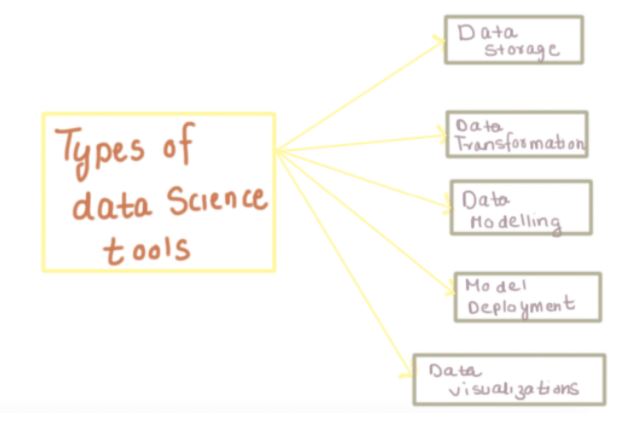
Data Storage for Data Science
Apache Hadoop
Apache Hadoop is a java based free software framework that can effectively store a large amount of data in a cluster. This framework runs in parallel on a cluster. Hence, it has the ability to allow us to process data across all nodes. Also, Hadoop Distributed File System (HDFS) is the storage system of Hadoop which splits big data and distribute across many nodes in a cluster. This also replicates data in a cluster thus providing high availability.
Microsoft HDInsight
It is a Big Data solution from Microsoft powered by Apache Hadoop which is available as a service in the cloud. HDInsight uses Windows Azure Blob storage as the default file system. Also, this also provides high availability with low cost.
NoSQL
While the traditional SQL can be effectively used to handle a large amount of structured data, we need NoSQL (Not Only SQL) to handle unstructured data. Also, NoSQL databases store unstructured data with no particular schema. Furthermore, each row can have its own set of column values. Hence, NoSQL gives better performance in storing a massive amount of data. There are many open-source NoSQL DBs available to analyze Big Data.
Hive
This is a distributed data management for Hadoop. Also, this supports SQL-like query option HiveSQL (HSQL) to access big data. This can be primarily used for Data mining purpose. Furthermore, this runs on top of Hadoop.
Sqoop
This is a tool that connects Hadoop with various relational databases to transfer data. This can be effectively used to transfer structured data to Hadoop or Hive.
PolyBase
This works on top of SQL Server 2012 Parallel Data Warehouse (PDW) and is used to access data stored in PDW. Furthermore, PDW is a data warehousing appliance built for processing any volume of relational data and provides integration with Hadoop allowing us to access non-relational data as well.
Data transformation for Data Science
Apache Hadoop
Apache Hadoop is a java based free software framework that can effectively store a large amount of data in a cluster. This framework runs in parallel on a cluster. Hence, it has the ability to allow us to process data across all nodes. Also, Hadoop Distributed File System (HDFS) is the storage system of Hadoop which splits big data and distribute across many nodes in a cluster. This also replicates data in a cluster thus providing high availability.
Microsoft HDInsight
It is a Big Data solution from Microsoft powered by Apache Hadoop which is available as a service in the cloud. HDInsight uses Windows Azure Blob storage as the default file system. Also, this also provides high availability with low cost.
NoSQL
While the traditional SQL can be effectively used to handle a large amount of structured data, we need NoSQL (Not Only SQL) to handle unstructured data. Also, NoSQL databases store unstructured data with no particular schema. Furthermore, each row can have its own set of column values. Hence, NoSQL gives better performance in storing a massive amount of data. There are many open-source NoSQL DBs available to analyze Big Data.
Hive
This is a distributed data management for Hadoop. Also, this supports SQL-like query option HiveSQL (HSQL) to access big data. This can be primarily used for Data mining purpose. Furthermore, this runs on top of Hadoop.
Sqoop
This is a tool that connects Hadoop with various relational databases to transfer data. This can be effectively used to transfer structured data to Hadoop or Hive.
PolyBase
This works on top of SQL Server 2012 Parallel Data Warehouse (PDW) and is used to access data stored in PDW. Furthermore, PDW is a data warehousing appliance built for processing any volume of relational data and provides integration with Hadoop allowing us to access non-relational data as well.
Data transformation for Data Science
Informatica — PowerCenter
Informatica is a leader in Enterprise Cloud Data Management with more than 500 global partners and more than 1 trillion transactions per month. It is a software Development Company that was found in 1993 with its headquarters in California, United States. In addition, It has a revenue of $1.05 billion and a total employee headcount of around 4,000.
IBM — Infosphere Information Server
IBM is a multinational Software Company found in 1911 with its headquarters in New York, U.S. and it has offices across more than 170 countries. It has a revenue of $79.91 billion as of 2016 and total employees currently working are 380,000.
Oracle Data Integrator
Oracle is an American multinational company with its headquarters in California and was found in 1977. It has a revenue of $37.72 billion as of 2017 and a total employee headcount of 138,000.
AB Initio
Ab Initio is an American private enterprise Software Company in Massachusetts, USA. It has offices worldwide in the UK, Japan, France, Poland, Germany, Singapore and Australia. Ab Initio specialises in application integration and high volume data processing.
Clover ETL
CloverETL, by a company named Javlin, with offices across the globe like USA, Germany, and the UK provides services like data processing and data integration.
Modelling Tools for Data Science
Infosys Nia
Infosys Nia is a knowledge-based AI platform, built by Infosys in 2017 to collect and aggregate organisational data from people, processes and legacy systems into a self-learning knowledge base.
H20 Driverless
H2O is an open source software tool, consisting of a machine learning platform for businesses and developers. H2O.ai is in the Java, Python and R programming languages. The platform is built with the languages with which developers are familiar with in order to make it easy for them to apply machine learning and predictive analytics.
Eclipse Deep learning 4j
Eclipse Deeplearning4j is an open-source deep-learning library for the Java Virtual Machine. It can serve as a DIY tool for Java, Scala and Clojure programmers working on Hadoop and other file systems. It also allows developers to configure deep neural networks and is suitable for use in business environments on distributed GPUs and CPUs.
Torch
Torch is a scientific computing framework, an open source machine learning library and a scripting language over the Lua programming language. It also provides an array of algorithms for deep machine learning. Furthermore, the torch is used by the Facebook AI Research Group and was previously used by DeepMind before it was acquired by Google and moved to TensorFlow.
IBM Watson
IBM is a big player in the field of AI, with its Watson platform housing an array of tools designed for both developers and business users.
Model Deployment for Data Science
ML Flow
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It tackles three primary functions:
Kubeflow
The Kubeflow project is for making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. The goal is not to recreate other services, but also to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures.
H20 AI
H2O is a fully open source, distributed in-memory machine learning platform with linear scalability. H2O’s supports the most widely used statistical & machine learning algorithms including gradient boosted machines, generalized linear models, deep learning and more. Also, H2O has an industry leading AutoML functionality that automatically runs through all the algorithms and their hyperparameters to produce a leaderboard of the best models. Furthermore, the H2O platform is used by over 14,000 organizations globally and is extremely popular in both the R & Python communities.
Domino Data Lab
Domino provides an open, unified data science platform to build, validate, deliver, and monitor models at scale. This accelerates research, sparks collaboration, increases iteration speed, and removes deployment friction to deliver impactful models.
Dataiku
Dataiku DSS is the collaborative data science software platform for teams of data scientists, data analysts, and engineers to explore, prototype, build and deliver their own data products more efficiently. Dataiku’s single, collaborative platform powers both self-service analytics and also the operationalization of machine learning models in production. Hence, in simple words, Data Science Studio (DSS) is a software platform that aggregates all the steps and big data tools necessary to get from raw data to production-ready applications. Furthermore, it shortens the load-prepare-test-deploy cycles required to create data-driven applications. Also, thanks to its visual and interactive workspace, it is accessible to both Data Scientists and Business Analysts
Data Visualisation for Data Science
Tableau
One of the major tool in this category. Tableau is famous for his drag and drops features in User Interface. In addition, this data visualization tool is free for some basic versions. Also, it supports multi-format data like xls,csv, XML , database connections etc . Furthermore, for more information on Tableau, You can reach out at Tableau official website.
Qlik View
The Qlik view is again a powerful BI tool for decision making. In addition, It is easily configurable and Deployable. Also, it is scalable with few constraints of RAM. The most loving features of Qlik view is visual drill down. In case you want to read more about Qlik View, You can reach out Qlik View official website. Here you can find all installation guide with other details.
Qlik Sense
Another powerful tool from Qlik family. Its popularity is because of its user-friendly features like drag and drop. Also, it is designed in such a manner that even a business user can use it. Furthermore, its cloud-based infrastructure makes it strong among other data visualizations tool. You can download the free desktop version of Qlik Sense and use it.
SAS Visual Analytics
SAS VA is not only a data visualization tool but also it is capable of predictive modeling and forecasting. It is easy to operate with drag and drop features. Also, there is awesome community support for SAS Visual Analytics. In addition, you can directly reach SAS Visual Analytics from here.
D3.js
D3 is a javascript library. Furthermore, It is an open source library. You can use to bind arbitrary data with the Document Object Model. As it is an open source library so you can find a rich tutorial on D3.js. Also, here is the link for the home page of D3.js.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
