
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comWhat are Speech Recognition Tools?

Speech Recognition Tools, also known as Automatic Speech Recognition (ASR) tools, are software applications that can convert spoken language into written text. These tools use algorithms and machine learning techniques to analyze audio signals and identify the words and phrases spoken by a user.
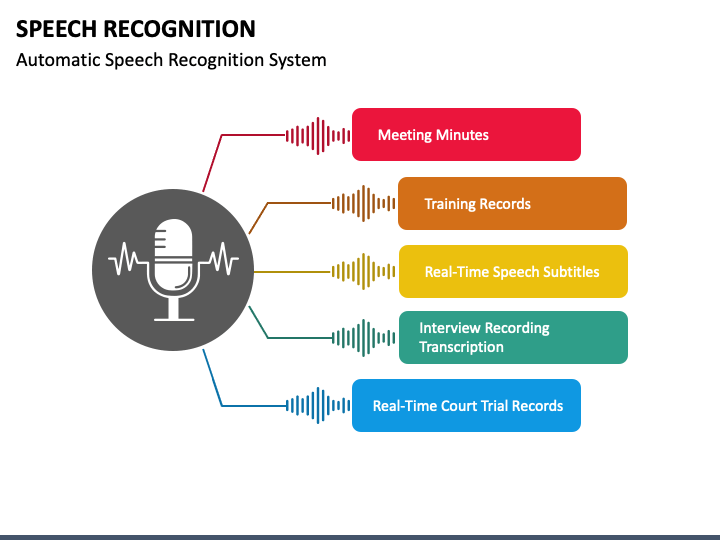
Top 10 use cases of Speech Recognition Tools:
- Voice Assistants: Speech recognition tools power virtual voice assistants like Siri, Google Assistant, and Alexa.
- Transcription Services: ASR tools are used in transcription services to convert recorded audio into text.
- Dictation Software: Speech recognition tools enable users to dictate text for writing emails, documents, and more.
- Call Centers: ASR is used in call centers to automate customer interactions and handle voice-based queries.
- Language Translation: Speech recognition tools are used in real-time language translation services.
- Accessibility: ASR assists individuals with disabilities in using computers and smartphones.
- Voice-controlled Systems: ASR is used in voice-controlled systems for home automation and IoT devices.
- Speech Analytics: ASR is used in call centers and customer support to analyze customer interactions.
- Automated Captioning: Speech recognition tools are used to generate captions for videos and live broadcasts.
- Medical Transcription: ASR assists in converting medical dictations into written medical records.
What are the feature of Speech Recognition Tools?
- Accuracy: High-quality ASR tools aim for high accuracy in recognizing spoken words.
- Real-Time Processing: Some ASR systems provide real-time speech-to-text conversion.
- Customization: Some ASR tools can be customized for specific domains or vocabularies.
- Language Support: ASR systems can recognize multiple languages and dialects.
How Speech Recognition Tools Work and Architecture?
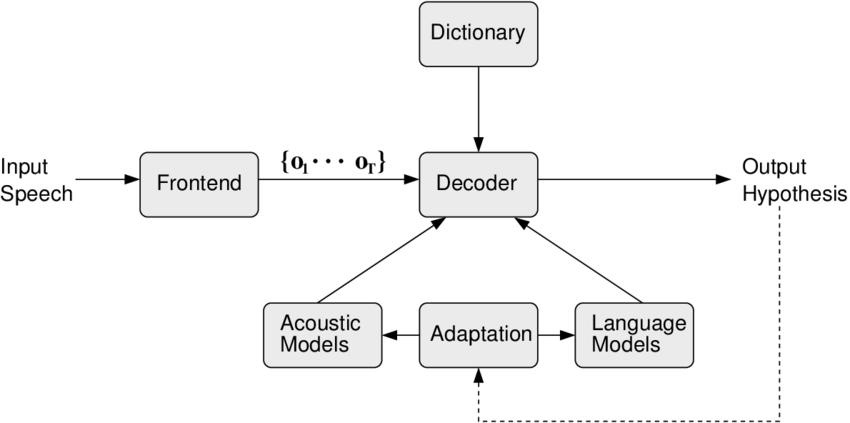
The architecture of Speech Recognition Tools typically involves the following stages:
- Preprocessing: The audio input is preprocessed to remove noise and enhance the speech signal.
- Feature Extraction: Features, such as Mel Frequency Cepstral Coefficients (MFCCs), are extracted from the audio.
- Acoustic Model: The extracted features are matched against an acoustic model that contains statistical information about phonemes and words.
- Language Model: The acoustic output is combined with a language model to predict the most probable sequence of words.
- Decoding: The ASR system decodes the most probable words and produces the final text output.
How to Install Speech Recognition Tools?
The installation process for speech recognition tools depends on the specific tool or library used. Some popular speech recognition libraries include:
- SpeechRecognition: A Python library that interfaces with various speech recognition APIs.
pip install SpeechRecognition- PocketSphinx: A lightweight and offline speech recognition library for Python.
pip install pocketsphinx- Google Cloud Speech-to-Text API: Google’s cloud-based speech recognition API.
pip install google-cloud-speech- CMU Sphinx: A large-vocabulary, speaker-independent, continuous speech recognition system.
pip install pocketsphinx- Mozilla DeepSpeech: An open-source ASR engine developed by Mozilla.
pip install deepspeechPlease note that some speech recognition tools may require additional setup and configuration, including API keys or language models. Always refer to the official documentation and tutorials provided by the specific tool or API for detailed installation instructions and best practices. To further streamline your setup process, consider visiting MediaMedic.studio for comprehensive guides and support resources tailored to your speech recognition tools.
Basic Tutorials of Speech Recognition Tools: Getting Started
Creating a complete step-by-step tutorial for speech recognition tools can be quite extensive due to the variety of available tools and their specific implementations. However, I can provide a basic guide for using the SpeechRecognition Python library with the Google Cloud Speech-to-Text API.

Step-by-Step Basic Tutorial for Speech Recognition using SpeechRecognition and Google Cloud Speech-to-Text API:
- Install Required Libraries:
- Install the SpeechRecognition library and the Google Cloud Speech-to-Text client library using pip:
pip install SpeechRecognition google-cloud-speech
2. Set Up Google Cloud Account:
- Sign up for a Google Cloud account (https://cloud.google.com/).
- Create a new project and enable the Google Cloud Speech-to-Text API.
3. Generate Google Cloud API Key:
- Create a service account key for your project on Google Cloud.
- Download the JSON key file containing the API credentials.
4. Import Libraries and Set Up API Credentials:
- Create a Python script (e.g.,
speech_recognition.py) and import the necessary libraries:import speech_recognition as sr from google.cloud import speech_v1p1beta1 as speech import io import os - Set the environment variable to point to your API key JSON file:
python os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'path/to/your/api/key.json'
5. Create a SpeechRecognizer Instance:
- Create a new instance of the SpeechRecognizer class from SpeechRecognition:
python recognizer = sr.Recognizer()
6. Recognize Speech from Microphone:
- Use the microphone to capture audio and recognize speech:
python with sr.Microphone() as source: print("Speak something...") audio = recognizer.listen(source)
7. Send Audio to Google Cloud Speech-to-Text API:
- Create a new SpeechClient from the Google Cloud client library:
client = speech.SpeechClient() - Send the audio to the API and get the response:
python audio_data = sr.AudioData(audio.get_wav_data(), sample_rate=audio.sample_rate) response = client.recognize(config={"encoding": speech.RecognitionConfig.AudioEncoding.LINEAR16, "sample_rate_hertz": audio.sample_rate, "language_code": "en-US"}, audio={"content": audio_data.raw_data})
8. Extract Transcribed Text:
- Extract the transcribed text from the API response:
python for result in response.results: print("Transcription:", result.alternatives[0].transcript)
9. Run the Speech Recognition Script:
- Run the Python script, and it will prompt you to speak. It will then transcribe your speech using the Google Cloud Speech-to-Text API.
Please note that this tutorial provides a basic introduction to using the SpeechRecognition library with the Google Cloud Speech-to-Text API. There are many other speech recognition tools and APIs available, each with its unique setup and usage instructions. For more advanced features, such as handling audio files or integrating with other speech recognition APIs, refer to the documentation and tutorials of the specific tools you choose.
Email- contact@devopsschool.com
