 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com
 The Complete Guide to AWS Redshift – Cloud Data Warehousing at Scale
The Complete Guide to AWS Redshift – Cloud Data Warehousing at Scale
As the digital economy expands, the amount of data generated by businesses is growing exponentially. From customer transactions and website clicks to IoT streams and app analytics, organizations are dealing with petabytes of data that need to be organized, stored, and analyzed quickly. Traditional on-premise data warehouses often struggle to meet these demands. This is where AWS Redshift steps in — delivering a fast, scalable, and fully managed cloud data warehouse solution.
AWS Redshift empowers organizations to perform complex analytics on massive volumes of data using familiar SQL tools, all while maintaining high performance and minimizing cost. Whether you’re a startup analyzing customer trends or a Fortune 500 company running complex dashboards, Redshift offers the capabilities needed for modern analytics at scale.
 What is AWS Redshift?
What is AWS Redshift?
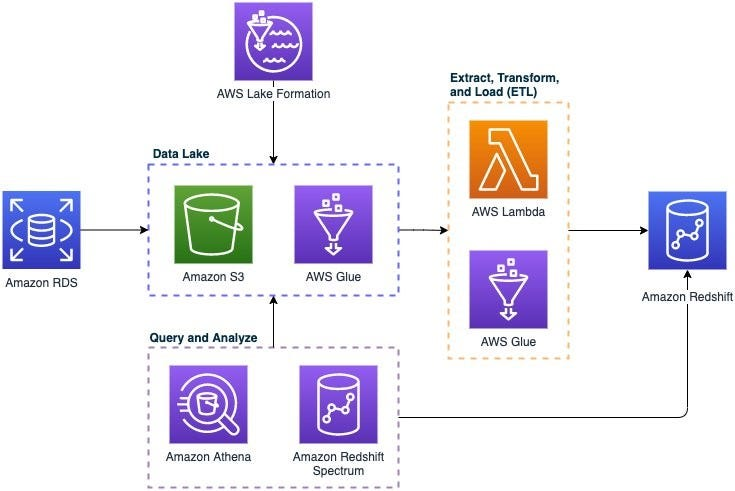
AWS Redshift is a fully managed, petabyte-scale cloud data warehouse service offered by Amazon Web Services. It is designed to analyze structured and semi-structured data using standard SQL and connect seamlessly to analytics and business intelligence tools.
Redshift enables organizations to run complex analytical queries on vast datasets in real-time, making it ideal for building reporting dashboards, predictive models, and decision-making systems. It uses massively parallel processing (MPP), columnar storage, and advanced compression techniques to deliver lightning-fast query performance.
It is one of the most widely adopted cloud data warehouses in the world due to its speed, scalability, and cost-efficiency.
 Why is AWS Redshift Used?
Why is AWS Redshift Used?
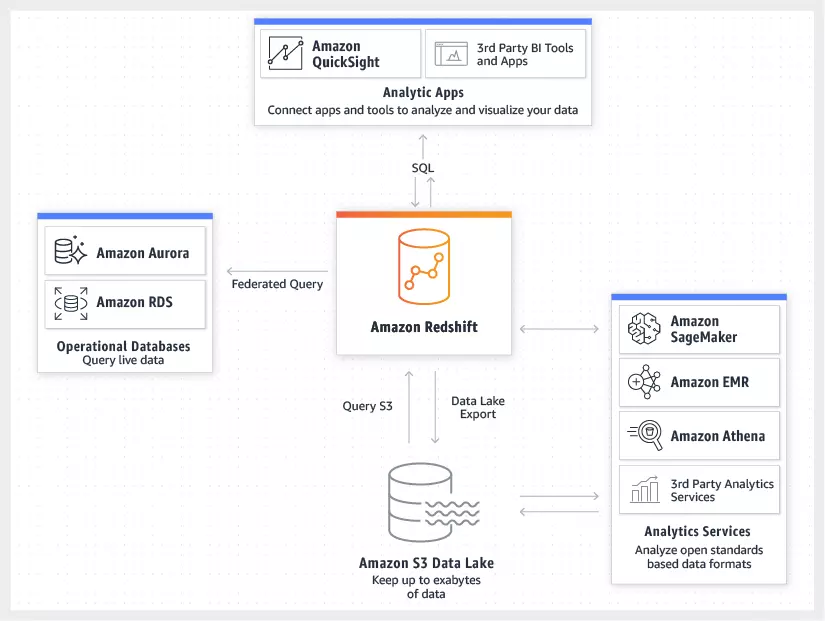
AWS Redshift is used to unlock insights from large volumes of data efficiently and cost-effectively. Organizations adopt Redshift for a variety of reasons:
- Data Consolidation: It allows teams to consolidate data from multiple sources such as databases, APIs, and flat files into a single data warehouse for unified analytics.
- Performance: Redshift is designed for speed. It can execute queries across billions of rows in seconds using distributed computing.
- Cost Optimization: Its pay-as-you-go pricing, combined with reserved instances and compression, allows organizations to manage costs effectively.
- Scalability: Redshift allows users to start small and scale up to petabytes as data grows.
- Ease of Use: Redshift supports standard SQL, making it easy for developers and analysts to use familiar tools without needing to learn new languages or frameworks.
- Business Intelligence (BI): It integrates seamlessly with BI tools such as Tableau, Power BI, Looker, and QuickSight.
In essence, Redshift is the go-to solution for companies that want to make data-driven decisions at scale.
 How Does AWS Redshift Work?
How Does AWS Redshift Work?
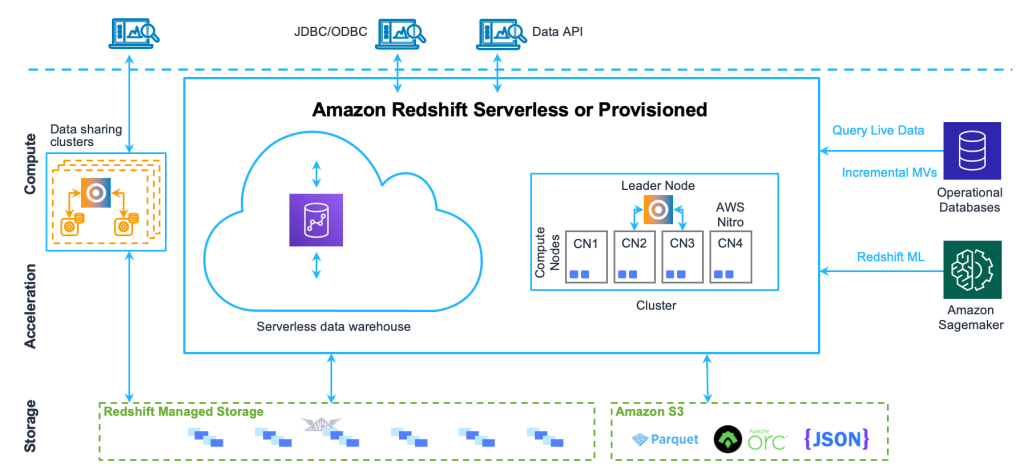
AWS Redshift operates on a cluster-based architecture. Each cluster consists of a leader node and one or more compute nodes.
Here’s how it works:
- Data Loading
- Data is ingested into Redshift using services like AWS Glue, Redshift Data API, COPY command (from S3, DynamoDB, etc.), or via third-party ETL tools.
- Redshift supports structured data (CSV, TSV, JSON) and semi-structured data (Parquet, ORC).
- Data Storage
- Data is stored in columnar format instead of row-based, which allows for better compression and faster analytics.
- Redshift compresses data intelligently and reduces I/O by reading only relevant columns for a query.
- Query Processing
- Queries are submitted to the leader node, which parses the query and generates execution plans.
- These plans are distributed to the compute nodes, which process the data in parallel.
- Results are aggregated and returned to the user.
- Massively Parallel Processing (MPP)
- Redshift splits data and workloads across multiple nodes to process operations simultaneously. This MPP approach ensures high performance even with large datasets.
- Result Delivery
- Query results are returned in seconds to the end-user or application, which can visualize or store the insights.
This architecture makes Redshift incredibly fast and efficient for heavy workloads and analytical processing.
 Key Features of AWS Redshift
Key Features of AWS Redshift
- Columnar Storage: Optimized for analytic workloads by storing data in columns rather than rows.
- Massively Parallel Processing (MPP): Speeds up query execution by distributing tasks across compute nodes.
- Redshift Spectrum: Run SQL queries on data directly stored in S3 without loading it into Redshift.
- Materialized Views: Improve performance by caching the results of complex queries.
- Concurrency Scaling: Automatically adds capacity during periods of high query load.
- Data Sharing: Share data securely and in real time across Redshift clusters and accounts.
- Federated Query: Query live data across multiple sources such as Aurora, RDS, and Redshift.
- Automatic Vacuuming and Compaction: Maintains data storage and query performance automatically.
- Machine Learning Integration: Train and use ML models directly inside Redshift using SQL functions.
- Encryption and Security: Supports KMS, IAM, VPC, SSL, and audit logging.
 Main Components of AWS Redshift
Main Components of AWS Redshift
Understanding the architecture and key components of Redshift is crucial for effective use:
1. Leader Node
Handles client connections and query planning. It does not store data but coordinates the processing across compute nodes.
2. Compute Nodes
These store the actual data and execute the SQL queries. Data is divided among them for parallel processing.
3. Node Slices
Each compute node is divided into slices. Each slice processes a portion of data independently.
4. Cluster
A Redshift cluster includes the leader and compute nodes. The size and number of nodes define the cluster capacity.
5. Redshift Spectrum
Allows querying of data in S3 using external tables, bridging data lakes and data warehouses.
6. Redshift Data API
Enables interaction with Redshift using API calls without requiring persistent connections or drivers.
7. Workload Management (WLM)
Lets users manage priorities and concurrency of queries for better performance tuning.
 When Should You Use AWS Redshift?
When Should You Use AWS Redshift?
Redshift is the best choice when:
- You need to perform complex SQL analytics on large datasets.
- Your data is coming from multiple sources (RDS, S3, third-party tools) and needs to be combined.
- You are building data-driven dashboards for internal teams or customers.
- You want to replace on-premise data warehouses and reduce hardware maintenance.
- Your use case requires scalability, security, and fast performance.
- You are implementing a data lake + data warehouse hybrid architecture.
- You are feeding machine learning pipelines with large-scale historical data.
 Benefits of Using AWS Redshift
Benefits of Using AWS Redshift
- High Performance: Sub-second queries on large datasets with MPP and columnar storage.
- Elastic Scalability: Easily add or remove nodes based on demand.
- Cost Optimization: Compression, pay-as-you-go, and Reserved Instances lower total costs.
- Secure by Design: VPC, KMS encryption, and IAM roles provide enterprise-grade security.
- Seamless Integration: Redshift integrates well with other AWS services like S3, Glue, Lambda, and QuickSight.
- Data Lake Interoperability: Use Redshift Spectrum to query data from S3 without moving it.
- User-Friendly: Standard SQL support allows any SQL-skilled team to start using Redshift without learning new tools.
- Automation: Maintenance tasks like backups, replication, and scaling are handled automatically.
 Limitations or Challenges of AWS Redshift
Limitations or Challenges of AWS Redshift
Despite its strengths, Redshift has some challenges:
- Cold Query Latency: The first query after a period of inactivity may take longer.
- Vacuum Management: Though partially automated, improper design may require manual optimization for performance.
- Storage Bound Issues: Compression helps, but storing massive volumes without optimization can slow performance.
- Concurrency Limits: During high loads, concurrency scaling must be enabled, or performance could degrade.
- Limited Support for Unstructured Data: Best suited for structured or semi-structured data.
- Vendor Lock-In: Deep integration with AWS can make multi-cloud deployments challenging.
Understanding these limitations helps in designing systems that balance performance, cost, and flexibility.
 How to Get Started with AWS Redshift
How to Get Started with AWS Redshift
Step 1: Set Up a Redshift Cluster
Use the AWS Management Console or CLI to launch a Redshift cluster. Choose the node type (RA3, DS2) and set the desired number of nodes.
Step 2: Load Data
- Use the COPY command to ingest data from S3, DynamoDB, or Amazon EMR.
- Alternatively, use AWS Glue or an ETL tool to move data from other sources.
Step 3: Define Schemas and Tables
Create schemas, tables, and views using standard SQL. Use distribution styles and sort keys for optimization.
Step 4: Run Queries
Connect using a SQL client or BI tool and begin analyzing your data.
Step 5: Monitor and Optimize
Use Redshift’s Query Performance Insights and CloudWatch metrics to monitor cluster health and query performance. Tune queries, update statistics, and maintain WLM queues.
Redshift allows you to go from data ingestion to analytics in a matter of minutes.
 Alternatives to AWS Redshift
Alternatives to AWS Redshift
Redshift is a leading cloud data warehouse, but there are several alternatives:
| Tool | Description |
|---|---|
| Google BigQuery | Fully serverless data warehouse from Google Cloud. Auto-scaling and pay-per-query pricing. |
| Snowflake | Independent cloud data platform with multi-cloud support, known for separation of storage and compute. |
| Azure Synapse Analytics | Microsoft’s analytics platform integrating SQL Data Warehouse with big data and ML. |
| Databricks SQL | Lakehouse platform offering high-speed analytics on data lakes. |
| Presto/Trino | Open-source distributed SQL query engines ideal for federated queries over large data lakes. |
Each platform has its strengths, and choosing the right one depends on data size, budget, ecosystem, and use case complexity.
 Real-World Use Cases and Success Stories
Real-World Use Cases and Success Stories
1. Online Travel Company
A global travel company uses Redshift to analyze search queries, bookings, and customer feedback. The system powers recommendation engines and personalized marketing.
2. Retail and E-Commerce
Redshift is used to consolidate order data, customer behavior, and inventory into a single platform that drives dynamic pricing, product recommendations, and logistics optimization.
3. Media and Streaming Services
Companies stream user activity logs into Redshift to understand content engagement, drive advertising analytics, and monitor application health.
4. Healthcare Analytics
Hospitals and health-tech companies use Redshift to analyze patient records, optimize operations, and support clinical decision-making.
5. Financial Services
Banks use Redshift to detect fraudulent transactions, analyze market trends, and deliver regulatory reports with strict compliance controls.
 Conclusion
Conclusion
AWS Redshift is more than just a data warehouse — it’s a modern, enterprise-grade analytics platform that supports the needs of organizations of all sizes. Its performance, flexibility, and integration capabilities make it a top choice for companies looking to harness the power of big data.
From managing petabyte-scale datasets to running ad hoc queries for real-time insights, Redshift provides the tools to drive faster decision-making, optimized operations, and competitive advantage. Whether you’re starting from scratch or migrating from legacy systems, Redshift is designed to grow with your data needs.
In a world where speed and insight define success, Redshift helps you stay ahead — securely, scalably, and intelligently.
rkbook!
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
