
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com
What is Apache Hadoop?
Apache Hadoop is an open-source software framework for distributed storage and processing of big data sets across clusters of computers. It was created by Doug Cutting and Mike Cafarella in 2006 and is now maintained by the Apache Software Foundation. Hadoop allows for the processing of large datasets in parallel by breaking them down into smaller pieces and distributing them across a cluster of computers.
Top 10 use cases of Apache Hadoop
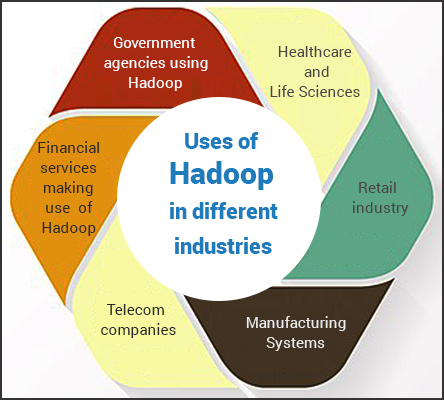
- Data Warehousing: Hadoop can be used to store and process large amounts of structured and unstructured data in a cost-effective manner.
- Log Processing: Companies can use Hadoop to process and analyze log data from various sources, such as web servers, applications, and systems.
- Fraud Detection: Hadoop can be used to analyze large datasets to detect fraudulent activity in real-time.
- Recommendation Engines: Hadoop can be used to build recommendation engines that provide personalized recommendations to users based on their past behavior.
- Social Media Analysis: Hadoop can be used to analyze social media data to gain insights into customer behavior and preferences.
- Genomics: Hadoop can be used to store and process large amounts of genomic data for research and medical purposes.
- Image and Video Analysis: Hadoop can be used to analyze and process large amounts of image and video data, such as facial recognition and object detection.
- Predictive Analytics: Hadoop can be used to build predictive models that help businesses make data-driven decisions.
- Machine Learning: Hadoop can be used to train and deploy machine learning models on large datasets.
- Internet of Things (IoT): Hadoop can be used to store and process data from IoT devices to gain insights and improve decision-making.
What are the features of Apache Hadoop?
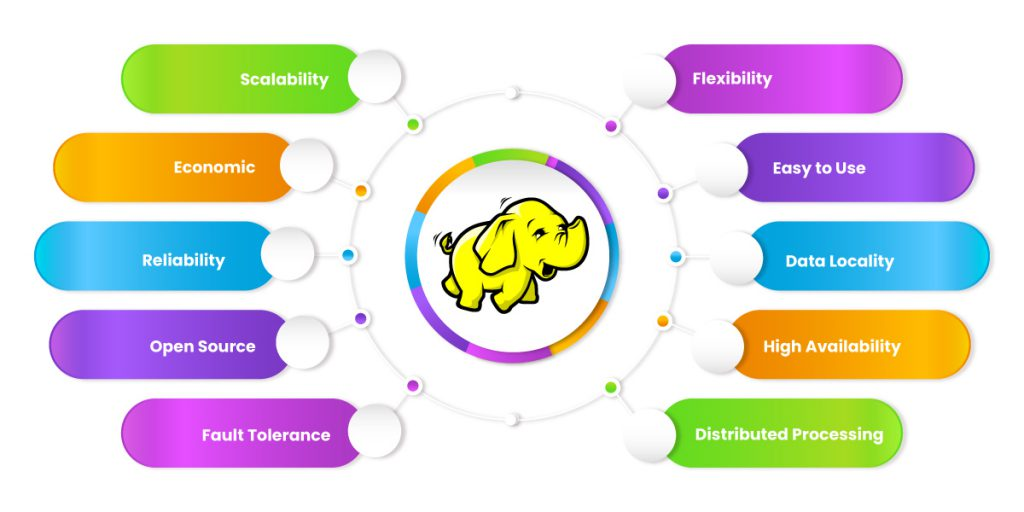
- Distributed Computing: Hadoop allows for the distribution of data and processing across multiple machines in a cluster.
- Scalability: Hadoop can handle large datasets, making it ideal for big data applications.
- Fault-tolerance: Hadoop is designed to handle hardware failures and can recover from them automatically.
- Cost-effective: Hadoop is open-source software, making it a cost-effective solution for big data processing.
- Flexible: Hadoop supports a wide range of data types, including structured, unstructured, and semi-structured data.
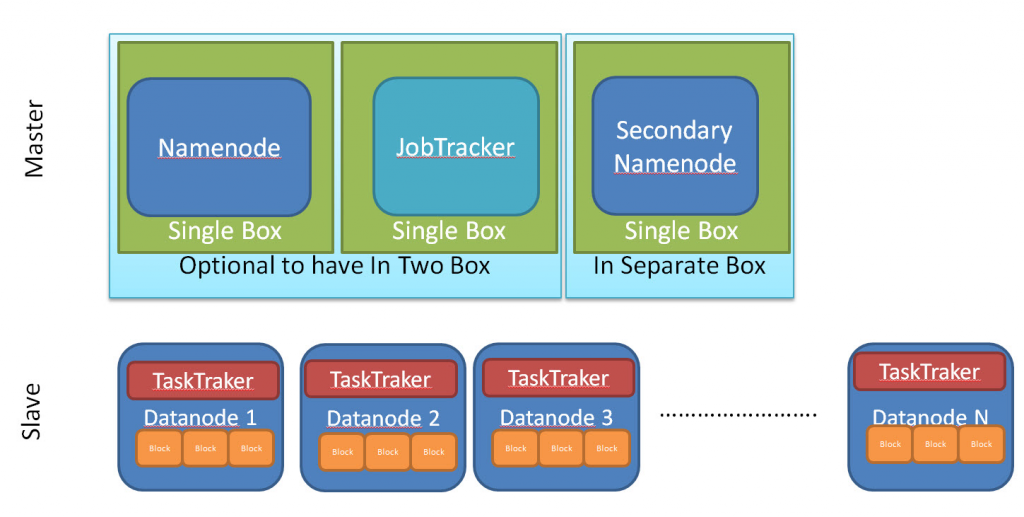
How Apache Hadoop works and Architecture?
Apache Hadoop works by dividing large datasets into smaller chunks and distributing them across a cluster of nodes. Each node in the cluster stores a portion of the data and processes it in parallel with other nodes. The nodes communicate with each other to coordinate the processing of the data.
The architecture of Apache Hadoop consists of several components:
Hadoop Distributed File System (HDFS): HDFS is the primary storage system used by Apache Hadoop. It is designed to store and manage large amounts of data across multiple machines.
NameNode: NameNode is the central node that manages the metadata of files stored in HDFS.
DataNode: DataNode is the node that stores the data in HDFS.
MapReduce: MapReduce is the programming model used by Apache Hadoop for processing large datasets in parallel.
YARN: YARN (Yet Another Resource Negotiator) is the resource manager used by Apache Hadoop. It manages the resources in a cluster and schedules tasks for processing.
How to Install Apache Hadoop?
Installing Apache Hadoop can be a complex process, but there are many resources available to help guide you through the process. The first step is to download the Hadoop distribution from the Apache website. Once downloaded, you will need to configure the Hadoop environment and set up the necessary directories. You will also need to configure the Hadoop cluster and set up any necessary security measures.
Basic Tutorials of Apache Hadoop: Getting Started

Installation
Before we can start using Hadoop, we need to install it. Here are the steps:
Step 1: Download Hadoop
Go to the official Apache Hadoop website and download the latest stable release of Hadoop.
Step 2: Install Java
Hadoop requires Java to run, so you’ll need to install it if you don’t already have it. You can download the latest version of Java from the Oracle website.
Step 3: Set Up Environment Variables
You’ll need to set up some environment variables to tell Hadoop where to find Java and where to store its files. Here’s how to do it:
Windows:
Open the System Properties dialog box and click on the Advanced tab. Click on the Environment Variables button and add a new system variable called “JAVA_HOME” with the path to your Java installation. Then add another system variable called “HADOOP_HOME” with the path to your Hadoop installation.
Linux/Mac:
First Open the .bashrc file and add the following lines:
export JAVA_HOME=/path/to/java
export HADOOP_HOME=/path/to/hadoopStep 4: Test Installation
Once you’ve installed Hadoop and set up your environment variables, you can test your installation by running the following command:
hadoop versionUsing Hadoop
Now that we’ve installed Hadoop, let’s learn how to use it.
Step 1: Create a Hadoop Cluster
To create a Hadoop cluster, we need to start the Hadoop daemons. Here’s how to do it:
Windows:
Open a command prompt and navigate to the bin directory of your Hadoop installation. Run the following command:
start-all.cmdLinux/Mac:
Open a terminal and navigate to the sbin directory of your Hadoop installation. Run the following command:
./start-all.shStep 2: Upload Data to Hadoop
To upload data to Hadoop, we can use the Hadoop Distributed File System (HDFS). Here’s how to upload a file:
Windows:
Open a command prompt and navigate to the bin directory of your Hadoop installation. Run the following command:
hadoop fs -put /path/to/local/file /path/to/hdfs/directoryLinux/Mac:
Again, Open the terminal and run the below command:
hadoop fs -put /path/to/local/file /path/to/hdfs/directoryStep 3: Run a MapReduce Job
MapReduce is a programming model that enables the processing of large datasets in a parallel and distributed manner. Here’s how to run a MapReduce job:
Windows:
Open a command prompt and navigate to the bin directory of your Hadoop installation. Run the following command:
hadoop jar /path/to/hadoop/mapreduce/job.jar /path/to/input /path/to/outputLinux/Mac:
Open the terminal and run the below command:
hadoop jar /path/to/hadoop/mapreduce/job.jar /path/to/input /path/to/outputConclusion
Congratulations! You now have a basic understanding of Apache Hadoop and how to use it. With this knowledge, you can start exploring the world of big data and all the amazing things you can do with it. Happy Hadooping!
Email- contact@devopsschool.com
