
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comWhat is Apache Zeppelin?

Apache Zeppelin is an open-source web-based notebook for data analysis, data visualization, and collaborative data science. It provides an interactive environment where users can write and execute code in multiple programming languages, visualize data, and share insights. Zeppelin supports various programming languages and data processing frameworks, making it a versatile tool for exploring and analyzing data.
Top 10 use cases of Apache Zeppelin:
Here are the top 10 use cases of Apache Zeppelin:
- Data Exploration and Analysis: Zeppelin notebooks allow data scientists and analysts to interactively explore datasets, run queries, and perform analysis using languages like Python, R, SQL, and more.
- Data Visualization: Zeppelin provides built-in visualization capabilities, enabling users to create interactive charts, graphs, and visual representations of their data.
- Machine Learning Prototyping: Data scientists can use Zeppelin to prototype and experiment with machine learning models, from data preprocessing to model training and evaluation.
- Collaborative Work: Zeppelin notebooks can be shared with team members, enabling collaborative data analysis and report generation within a shared environment.
- Data Reporting and Presentation: Users can create data-rich reports and presentations by combining code, visualizations, and explanatory text in a single notebook.
- Real-time Data Analysis: Zeppelin can connect to various data sources, including streaming data, enabling real-time data analysis and visualization.
- Big Data Analytics: Zeppelin supports integration with big data frameworks like Apache Spark, allowing users to analyze and visualize large datasets efficiently.
- Data Transformation: Users can perform data transformations and manipulations using scripting languages and libraries available in Zeppelin notebooks.
- Automated ETL (Extract, Transform, Load): Zeppelin can be used to automate ETL processes by combining scripting and data processing capabilities.
- Educational and Tutorial Use: Zeppelin notebooks are great for teaching and learning data science concepts, as they provide an interactive environment for demonstrations and tutorials.
- IoT Data Analysis: Zeppelin can be used to analyze data from Internet of Things (IoT) devices, helping users gain insights from sensor data and other IoT sources.
- Data Pipelines: Zeppelin can be used to create, visualize, and manage data pipelines, combining data extraction, transformation, and loading tasks.
Apache Zeppelin’s flexibility, support for multiple languages, and integration with various data processing frameworks make it a valuable tool for data scientists, analysts, and developers working on data-driven projects. It allows for seamless interaction with data, code, and visualizations, fostering efficient analysis and collaboration.
What are the feature of Apache Zeppelin?
- Interactive Notebooks: Zeppelin provides interactive notebooks where you can write and execute code snippets in various programming languages, including but not limited to Scala, Python, R, SQL, and more.
- Data Visualization: You can create a wide range of visualizations, including charts, graphs, and interactive dashboards, directly within your notebook to enhance data exploration.
- Multi-language Support: Zeppelin supports multiple programming languages, allowing you to mix different languages within the same notebook for different tasks.
- Collaboration: Zeppelin notebooks can be shared with team members or collaborators, enabling collaborative data analysis, debugging, and report generation.
- Rich Text and Documentation: You can add rich text, images, and explanatory notes alongside your code and visualizations, making it easier to document and communicate your findings.
- Dynamic Forms: Zeppelin supports interactive form elements that allow users to input parameters and dynamically adjust code execution and visualization outputs.
- Integration with Data Sources: Zeppelin can connect to various data sources, databases, and data processing frameworks such as Apache Spark, Hadoop, and more.
- Built-in Spark Integration: Zeppelin provides seamless integration with Apache Spark, enabling distributed data processing and analysis on large datasets.
- Data Ingestion: You can load and transform data from various file formats and data sources using Zeppelin’s data ingestion capabilities.
- Interpreter Plugins: Zeppelin supports interpreter plugins for different programming languages and frameworks, allowing you to extend its functionality to match your needs.
- Notebook Scheduling: You can schedule the execution of notebooks at specific intervals, making Zeppelin suitable for automating data processing tasks.
How Apache Zeppelin Works and Architecture?
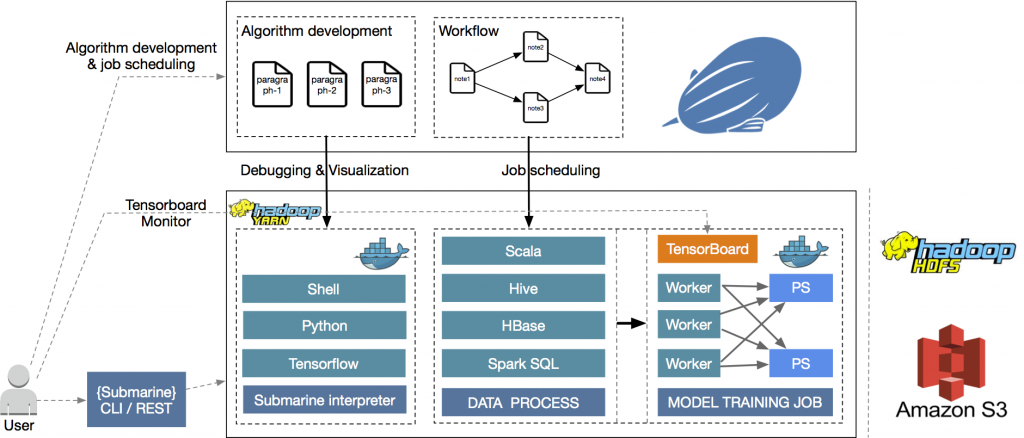
1. Notebook Interface:
Apache Zeppelin provides a web-based notebook interface where you create, edit, and execute notebooks. Notebooks are organized into paragraphs, which can contain code, documentation, and visualizations.
2. Paragraph Execution:
Each paragraph in a notebook can be associated with a specific interpreter, such as Scala, Python, SQL, etc. When you execute a paragraph, the associated interpreter processes the code and generates output.
3. Interpreter:
Interpreters are responsible for executing code snippets written in different languages. Zeppelin supports various interpreters and allows you to specify which interpreter to use for each paragraph.
4. Data Integration:
Zeppelin can integrate with different data sources, including databases, distributed data processing frameworks like Apache Spark, and more. This allows you to analyze and visualize data from various sources directly within your notebook.
5. Data Visualization:
Zeppelin provides built-in support for data visualization libraries, allowing you to create charts, graphs, and dashboards to represent your data visually.
6. Output Display:
The output of code execution, including text output, visualizations, and error messages, is displayed directly within the notebook, making it easy to understand and interpret the results.
7. Collaboration and Sharing:
You can share your notebooks with collaborators, enabling real-time collaboration and the sharing of insights and findings.
8. Distributed Execution:
For tasks involving distributed data processing frameworks like Apache Spark, Zeppelin can distribute code execution across a cluster of machines.
9. Server-Client Architecture:
Zeppelin follows a client-server architecture. The Zeppelin server manages notebook creation, execution, and communication with interpreters. Users interact with the server through a web-based interface.
10. Extensibility:
Zeppelin’s architecture is designed to support various interpreter plugins, allowing you to extend its capabilities by adding new interpreters for specific languages or frameworks.
Overall, Apache Zeppelin’s architecture enables interactive data analysis, integration with various data sources, and the creation of interactive and visually-rich notebooks for data exploration and reporting.
How to Install Apache Zeppelin?
There are two ways to install Apache Zeppelin:
- Using the binary distribution
- Download the binary distribution from the Apache Zeppelin website: https://zeppelin.apache.org/download.html.
- Unzip the distribution.
- Start Zeppelin by running the following command:
bin/zeppelin-daemon.sh start
- Using Docker
- Install Docker: https://docs.docker.com/get-started/.
- Run the following command to create a Docker image for Zeppelin:
docker build -t zeppelin . - Run the following command to start Zeppelin:
docker run -it -p 8080:8080 zeppelin
Once Zeppelin is installed, you can access it by opening a web browser and navigating to the following URL: http://localhost:8080.
Here are some additional things to keep in mind when installing Apache Zeppelin:
- Zeppelin requires Java 8 or higher.
- Zeppelin also requires some additional libraries, such as Scala and Spark. These libraries are included in the binary distribution or the Docker image.
- Zeppelin can be installed on a variety of platforms, including Linux, macOS, and Windows.
Basic Tutorials of Apache Zeppelin: Getting Started

The following are the basic steps of Apache Zeppelin:
- Create a new notebook
- Click on the “Create” button in the top left corner of the Zeppelin UI.
- Select the “New Notebook” option.
- Give the notebook a name and select the language you want to use.
- Write a simple Zeppelin paragraph
- In the notebook, type the below code:
println("Hello, world!") - Hit on the “Run” button to perform the code.
- In the notebook, type the below code:
- Use Zeppelin to interact with a data source
- Zeppelin can be used to interact with a variety of data sources, such as Spark, Hive, and MySQL.
- To connect to a data source, you need to create a connection configuration.
- For example, to connect to a Spark cluster, you would create a connection configuration with the following properties:
- Name: The name of the connection.
- Type: The type of the connection. In this case, the type is “Spark”.
- URL: The URL must be of the Spark cluster.
- Credentials: The credentials for the Spark cluster.
- Use Zeppelin to perform data analysis
- Once you have connected to a data source, you can use Zeppelin to perform data analysis.
- For example, you can use Zeppelin to query a database, create visualizations, and build machine learning models.
Email- contact@devopsschool.com
