
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com
ArangoDB is an open-source multi-model NoSQL database with a flexible data model for documents and graphs. It is designed as a “general purpose database,” offering all the features typically needed for modern web apps. It supports graph, document, and key-value data models allowing users to freely combine all data models in a single query. As applications become increasingly complex, you often need more than one NoSQL database. Using a multi-model database can simplify your architecture by combining several NoSQL types in a single infrastructure.
Moreover, different models can be combined in a single query. And, owing to its multi-model style, one can make lean applications, which will be scalable horizontally with any or all of the three data models.
History
ArangoDB has been referred to as a universal database but its creators refer to it as a “native multi-model database“, actually it is.
ArangoDB first release in year 2011 as AvocadoDB and then renamed to ArangoDB in 2012, developed by ArangoDB GmbH. It came up with the test stable version ArangoDB 3. It used by Docker, DC/OS, Liaison.
ArangoDB supports three data models:
- Document database
- Key-Value database
- Graph database
The multi-model paradigm allows users to combine each data model advantage within one context. For example, it allows creating nested documents within a graph database or benefiting from the key-value pairs’ high performance in a graph-connected environment.
Why we need for Multimodal Database?
Interpreting the [Fowler’s] basic idea leads us to realize the benefits of using a variety of appropriate data models for different parts of the persistence layer, the layer being part of the larger software architecture. According to this, one might, for example, use a relational database to persist structured, tabular data; a document store for unstructured, object-like data; a key/value store for a hash table; and a graph database for highly linked referential data.
However, traditional implementation of this approach will lead one to use multiple databases in the same project. It can lead to some operational friction (more complicated deployment, more frequent upgrades) as well as data consistency and duplication issues.
The next challenge after unifying the data for the three data models, is to devise and implement a common query language that can allow data administrators to express a variety of queries, such as document queries, key/value lookups, graph queries, and arbitrary combinations of these. Graphs are a perfect fit as data model for relations. In many real-world cases such as social network, recommender system, etc., a very natural data model is a graph.
It captures relations and can hold label information with each edge and with each vertex. Further, JSON documents are a natural fit to store this type of vertex and edge data.
What are the main features that define ArangoDB?
ArangoDB allows you to access any data (regardless of its model) using a single declarative query language. It is quite similar to a standard query SQL language with some minor differences.
- Easy performance scaling
The database allows you to quickly adapt to increasing requirements for performance and storage with both vertical and horizontal scaling. It also supports the independent scaling of different data models and allows you to quickly scale down your application to save on hardware and operational expenses.
- Decreased operational complexity
Multi-model databases allow you to use different storage technologies that better fit the way your data is used by different components within your application.
- Consolidation
ArangoDB drastically reduces the number of components to be maintained making your tech stack much less complex.
- VelocyPack (VPack)
ArangoDB uses binary JSON to store data. It is lean, self-contained, doesn’t allocate too much memory, and covers all of JSON plus dates, binary data, integers, as well as arbitrary precision numbers.
- Powerful fault tolerance system enabled by default.
- ArangoDB Query Language (AQL).
As a NoSQL database, ArangoDB features high performance in data storage and retrieval.
Why choose ArangoDB?
By choosing ArangoDB, we could use a single database for all features: chats, relationships, document sharing, and various types of entities (companies, persons, universities, employees, venture funds, etc.). It can store all connections between nodes and construct graphs that will be constantly updated when you add a new connection.
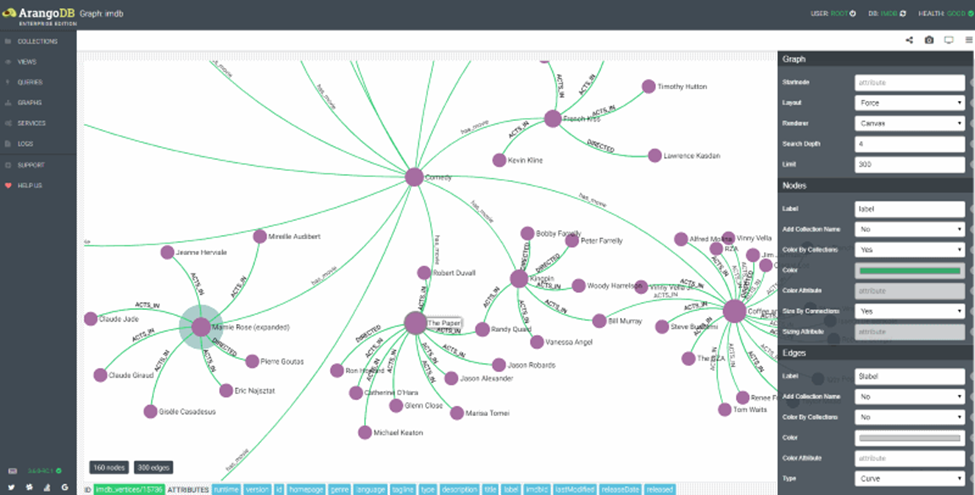
With ArangoDB, we could easily architect dynamic field attributes. The database allows implementing relations in two ways: by making links to primary keys or via connections and graphs. As we discovered, it’s better to use connections when you have dynamic attributes. And primary keys are better suited for situations when you have a clear understanding of relations between different entities. ArangoDB has an excellent web-interface that allows writing queries and instant viewing of the resulting graphs.
ArangoDB supports all the modern deployment options such as Kubernetes, Docker, and clusters for high-load and also supports ACID transactions and has excellent performance.
The average search query takes around 0.1 seconds. Even the most complex queries that affect hundreds of social networks take less than half a second. Joining so much data in a relational database would’ve required denormalization or using Elasticsearch with a flat connecting structure to help with the visualization. But with ArangoDB all the same done without any additional effort.
ArangoDB is one of the most elegant query languages and best too of my list.
Conclusions
It was a great pleasure working with ArangoDB, there were some difficulties like integrating the database with a framework but, overall, the experiment was a great success and the project was finished on time.
Now, when you choose a database for your project, it’s always worth considering ArangoDB.
I hope you like this particular blog. Thank You!!
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
