
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.com
Couchbase Server, originally known as Membase, is an open-source, distributed (shared-nothing architecture) multi-model NoSQL document-oriented database software package optimized for interactive applications. These applications may serve many concurrent users by creating, storing, and retrieving, aggregating, manipulating and presenting data. In support of these kinds of application needs, Couchbase Server is designed to provide easy-to-scale key-value or JSON document access with low latency and high sustained throughput. It is designed to be clustered from a single machine to very large-scale deployments spanning many machines.
Couchbase Server provided client protocol compatibility with memcached, but added disk persistence, data replication, live cluster reconfiguration, rebalancing and multitenancy with data partitioning.
History
Membase was developed by several leaders of the memcached project. The original membase source code was contributed by NorthScale, and project co-sponsors Zynga and Naver Corporation (then known as NHN) to a new project on membase.org in June 2010.
On February 8, 2011, the Membase project founders and Membase, Inc. announced a merger with CouchOne (a company with many of the principal players behind CouchDB) with an associated project merger. The merged company was called Couchbase, Inc. In January 2012, Couchbase released Couchbase Server 1.8. In September, 2012, Orbitz said it had changed some of its systems to use Couchbase. In December 2012, Couchbase Server 2.0 (announced in July 2011) was released and included a new JSON document store, indexing and querying, incremental MapReduce and replication across data centers.
What are the Main Features of Couchbase?
Flexible data model
With Couchbase Server, JSON documents are used to represent application objects and the relationships between objects. This document model is flexible enough so that you can change application objects without having to migrate the database schema, or plan for significant application downtime. The other advantage of the flexible, document-based data model is that it is well suited to representing real-world items.
JSON documents support nested structures, as well as fields representing relationships between items which enable you to realistically represent objects in your application.
Easy scalability
It is easy to scale with Couchbase Server, both within a cluster of servers and between clusters at different data centers. You can add additional instances of Couchbase Server to address additional users and growth in application data without any interruptions or changes in application code. With one click of a button, you can rapidly grow your cluster of Couchbase Servers to handle additional workload and keep data evenly distributed. Couchbase Server provides automatic sharding of data and rebalancing at run time; this lets you resize your server cluster on demand.
Easy developer integration
Couchbase provides client libraries for different programming languages such as Java / .NET / PHP / Ruby / C / Python / Node.js For read, Couchbase provides a key-based lookup mechanism where the client is expected to provide the key, and only the server hosting the data (with that key) will be contacted. It also provides a query mechanism to retrieve data where the client provides a query (for example, a range based on some secondary key) as well as the view (basically the index).
The query will be broadcast to all servers in the cluster and the result will be merged and sent back to the client. For write, Couchbase provides a key-based update mechanism where the client sends an updated document with the key (as doc id).
When handling write request, the server will respond to client’s write request as soon as the data is stored in RAM on the active server, which offers the lowest latency for write requests.
Consistent high performance
Couchbase Server is designed for massively concurrent data use and consistently high throughput. It provides consistent sub-millisecond response times which help ensure an enjoyable experience for application users. By providing consistent, high data throughput, Couchbase Server enables you to support more users with fewer servers. Couchbase also automatically spreads the workload across all servers to maintain consistent performance and reduce bottlenecks at any given server in a cluster.
Reliable and secure
Couchbase support access control using username and passwords. The credentials are transmitted securely over the network. The sensitive data can be protected while it is transmitted to/from the client application.
There is no single point of failure, since the data can be replicated across multiple nodes. Features such as cross-data center replication, failover, and backup and restore help ensure availability of data during server or datacenter failure.
About Couchbase Architecture
Couchbase is the merge of two popular NOSQL technologies:
- Membase, which provides persistence, replication, sharding to the high performance memcached technology
- CouchDB, which pioneers the document oriented model based on JSON
Like other NOSQL technologies, both Membase and CouchDB are built from the ground up on a highly distributed architecture, with data shard across machines in a cluster. Built around the Memcached protocol, Membase provides an easy migration to existing Memcached users who want to add persistence, sharding and fault resilience on their familiar Memcached model.
On the other hand, CouchDB provides first class support for storing JSON documents as well as a simple RESTful API to access them. Underneath, CouchDB also has a highly tuned storage engine that is optimized for both update transaction as well as query processing. Taking the best of both technologies, Membase is well-positioned in the NOSQL marketplace.
Transaction Model
Similar too many NOSQL databases, Couchbase’s transaction model is primitive as compared to RDBMS. Atomicity is guaranteed at a single document and transactions that span update of multiple documents are unsupported. To provide necessary isolation for concurrent access, Couchbase provides a CAS (compare and swap) mechanism which works as follows:
- When the client retrieves a document, a CAS ID (equivalent to a revision number) is attached to it.
- While the client is manipulating the retrieved document locally, another client may modify this document. When this happens, the CAS ID of the document at the server will be incremented.
- Now, when the original client submits its modification to the server, it can attach the original CAS ID in its request. The server will verify this ID with the actual ID in the server. If they differ, the document has been updated in between and the server will not apply the update.
- The original client will re-read the document (which now has a newer ID) and re-submit its modification.
- Couchbase also provides a locking mechanism for clients to coordinate their access to documents. Clients can request a LOCK on the document it intends to modify, update the documents and then releases the LOCK. To prevent a deadlock situation, each LOCK grant has a timeout so it will automatically be released after a period of time.
Deployment Architecture
In a typical setting, a Couchbase DB resides in a server clusters involving multiple machines. Client library will connect to the appropriate servers to access the data. Each machine contains a number of daemon processes which provides data access as well as management functions.
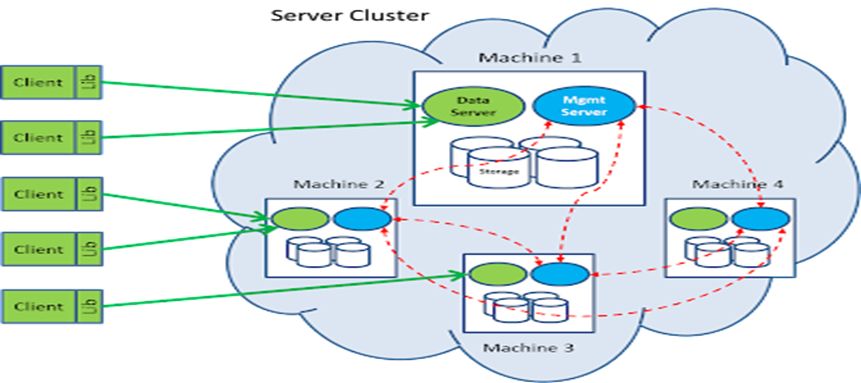
The data server, written in C/C++, is responsible to handle get/set/delete request from client. The Management server, written in Erlang, is responsible to handle the query traffic from client, as well as manage the configuration and communicate with other member nodes in the cluster.
Virtual Buckets
The basic unit of data storage in Couchbase DB is a JSON document (or primitive data type such as int and byte array) which is associated with a key. The overall key space is partitioned into 1024 logical storage unit called “virtual buckets” (or vBucket). vBucket are distributed across machines within the cluster via a map that is shared among servers in the cluster as well as the client library.
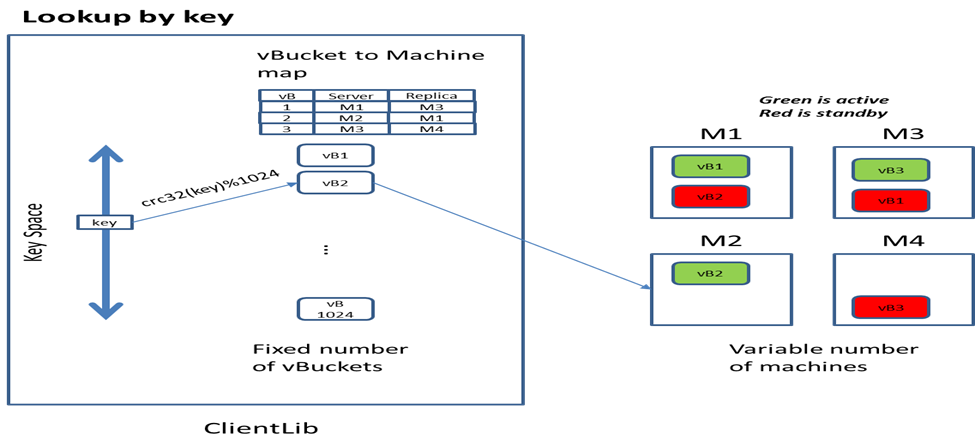
High availability is achieved through data replication at the vBucket level. Currently Couchbase supports one active vBucket zero or more standby replicas hosted in other machines. Currently the standby server are idle and not serving any client request. In future version of Couchbase, the standby replica will be able to serve read request.
Load balancing in Couchbase is achieved as follows:
- Keys are uniformly distributed based on the hash function
- When machines are added and removed in the cluster. The administrator can request a redistribution of vBucket so that data are evenly spread across physical machines.
Data Server
Data server implements the memcached APIs such as get, set, delete, append, prepend, etc. It contains the following key data structure:
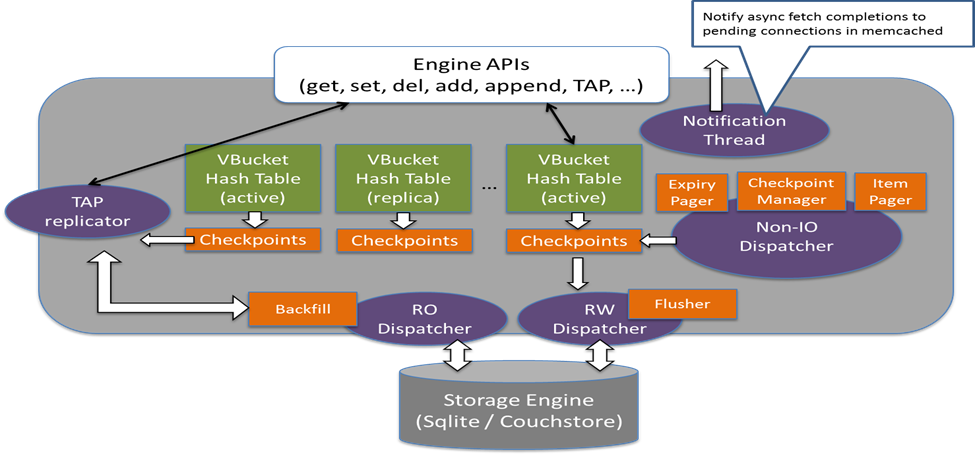
- One in-memory hashtable (key by doc id) for the corresponding vBucket hosted. The hashtable acts as both a metadata for all documents as well as a cache for the document content. Maintain the entry gives a quick way to detect whether the document exists on disk.
- To support async write, there is a checkpoint linkedlist per vBucket holding the doc id of modified documents that hasn’t been flushed to disk or replicated to the replica.
To handle a “GET” request
- Data server routes the request to the corresponding ep-engine responsible for the vBucket.
- The ep-engine will lookup the document id from the in-memory hastable. If the document content is found in cache (stored in the value of the hashtable), it will be returned. Otherwise, a background disk fetch task will be created and queued into the RO dispatcher queue.
- The RO dispatcher then reads the value from the underlying storage engine and populates the corresponding entry in the vbucket hash table.
- Finally, the notification thread notifies the disk fetch completion to the memcached pending connection, so that the memcached worker thread can revisit the engine to process a get request.
To handle a “SET” request, a success response will be returned to the calling client once the updated document has been put into the in-memory hashtable with a write request put into the checkpoint buffer. Later on the Flusher thread will pick up the outstanding write request from each checkpoint buffer, lookup the corresponding document content from the hashtable and write it out to the storage engine.
I hope you like this particular blog about Couchbase. Keep learning and keep exploring because there is lot more to know.
Thank you !!
