What is IBM InfoSphere Information Analyzer?
IBM InfoSphere Information Analyzer is a data quality and data profiling tool provided by IBM as part of the InfoSphere Information Server suite. It can be used to identify data quality issues, such as missing values, duplicate records, and incorrect data types. IIA can also be used to analyze the structure of your data, such as the data types, the relationships between the data, and the data lineage.
Top 10 use cases of IBM InfoSphere Information Analyzer:
- Data profiling: IIA can be used to profile data to identify quality issues, such as missing values, duplicate records, and incorrect data types.
- Data cleansing: IIA can be used to cleanse data by correcting errors, removing duplicates, and standardizing data formats.
- Data matching: IIA can be used to match data from different sources to identify and resolve duplicate records.
- Data enrichment: IIA can be used to enrich data by adding additional information, such as geolocation data or demographic information.
- Data governance: IIA can be used to implement data governance policies and procedures to ensure the quality of data.
- Data lineage: IIA can be used to track the lineage of data to understand where it came from and how it was used.
- Data quality dashboards: IIA can be used to create data quality dashboards to monitor the quality of data over time.
- Data quality automation: IIA can be used to automate data quality tasks, such as profiling, cleansing, and matching.
- Data quality reporting: IIA can be used to generate data quality reports to track the progress of data quality initiatives.
- Data quality training: IIA can be used to train users on how to use the IIA platform to improve the quality of data.
What are the features of IBM InfoSphere Information Analyzer?

IBM InfoSphere Information Analyzer offers a wide range of features, including:
- A visual interface that makes it easy to understand and manipulate data.
- A variety of data profiling tools to identify quality issues.
- Powerful data cleansing capabilities to correct errors, remove duplicates, and standardize data formats.
- Advanced data matching functionality to identify and resolve duplicate records.
- Flexible data enrichment options to add additional information to data.
- Comprehensive data governance features to ensure the quality of data.
- Data lineage tracking to understand where data came from and how it was used.
- Data quality dashboards to monitor the quality of data over time.
- Data quality automation to automate data quality tasks.
- Data quality reporting to track the progress of data quality initiatives.
- Data quality training to help users learn how to use IIA.
How IBM InfoSphere Information Analyzer works and Architecture?
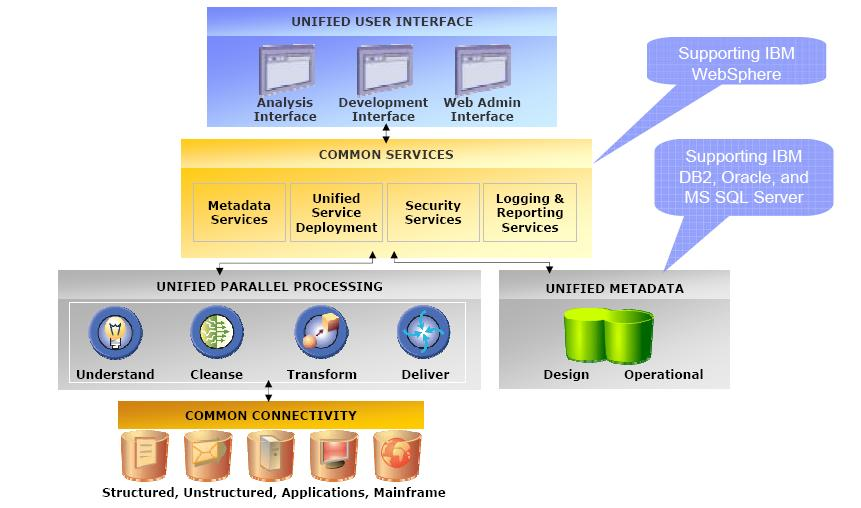
IBM InfoSphere Information Analyzer works by first profiling the data to identify quality issues. Once the quality issues have been identified, IIA can be used to cleanse the data, match the data, and enrich the data. IIA also offers a variety of data governance features to help organizations ensure the quality of their data.
The architecture of IBM InfoSphere Information Analyzer is based on a three-tier architecture:
- The Data Access Layer provides access to the data sources.
- The Data Quality Engine performs the data profiling, cleansing, matching, and enrichment operations.
- The Data Quality Management Layer provides a user interface for managing data quality tasks.
The Data Access Layer provides access to the data sources, such as databases, files, and web services. The Data Quality Engine performs the data profiling, cleansing, matching, and enrichment operations. The Data Quality Management Layer provides a user interface for managing data quality tasks, such as creating and managing data quality rules, monitoring data quality, and reporting on data quality.
How to Install IBM InfoSphere Information Analyzer?
To install IBM InfoSphere Information Analyzer, you will need to download the installation package from the IBM website. Once you have downloaded the installation package, you can follow the instructions in the installation guide to install IIA.
Here are the steps on how to install IBM InfoSphere Information Analyzer:
- Download the installation package from the IBM website.
- Run the installation package.
- Apply the on-screen instructions in the installation guide.
- Once the installation is complete, you can start using IIA.
Here are some of the system requirements for installing IBM InfoSphere Information Analyzer:
- Operating system: Windows 10, Windows Server 2016, or Linux
- Processor: Intel Core i5 or equivalent
- Memory: 8 GB RAM
- Hard disk space: 10
Basic Tutorials of IBM InfoSphere Information Analyzer: Getting Started
Here is a step-by-step basic tutorial to get started with IBM InfoSphere Information Analyzer:
Step-by-Step Basic Tutorial of IBM InfoSphere Information Analyzer:
Step 1: Install IBM InfoSphere Information Analyzer
- Obtain the installation media or download links for IBM InfoSphere Information Analyzer.
- Run the installer and follow the on-screen instructions to install the tool on your computer or server.
Step 2: Launch IBM InfoSphere Information Analyzer
- After installation, launch IBM InfoSphere Information Analyzer.
Step 3: Create a New Project
- In IBM InfoSphere Information Analyzer, create a new project to organize your data quality assessment tasks.
- Give the project a descriptive name and optionally add a description.
Step 4: Define Data Sources
- Connect to your data sources (e.g., databases, files) from which you want to perform data quality assessments.
- Define the data source connections within the project.
Step 5: Discover and Profile Data
- Use IBM InfoSphere Information Analyzer’s data profiling capabilities to discover and analyze the quality of data in your data sources.
- Define data profiling rules and metrics to assess data completeness, accuracy, consistency, and uniqueness.
Step 6: Run Data Quality Assessments
- Execute data quality assessments on the selected data sources based on the defined profiling rules and metrics.
- Analyze the results to identify data quality issues and anomalies.
Step 7: Data Quality Remediation
- Based on the data quality assessment results, address data quality issues and inconsistencies in the source data.
- Implement data cleansing and correction processes as needed.
Step 8: Data Quality Monitoring and Reporting
- Monitor data quality over time to detect changes and trends in data quality metrics.
- Create reports and dashboards to visualize data quality metrics and share insights with stakeholders.
Step 9: Schedule Data Quality Jobs (Optional)
- Schedule data quality assessments and monitoring jobs to run at regular intervals.
- Automate data quality checks for recurrent data updates.
Step 10: Data Quality Governance (Optional)
- Implement data quality governance processes to enforce data quality standards and policies.
- Establish data quality rules and thresholds for different data domains.
Please note that this is a basic tutorial to get started with IBM InfoSphere Information Analyzer. For more in-depth tutorials and advanced use cases, I recommend referring to IBM’s official documentation, and training materials.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
