
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comWhat is Microsoft Azure SQL Data Warehouse?

Microsoft Azure SQL Data Warehouse is a cloud-based, fully managed data warehousing solution provided by Microsoft Azure. It is designed to handle large volumes of data and deliver high-performance analytics for businesses of all sizes. Azure SQL Data Warehouse is built on a Massively Parallel Processing (MPP) architecture, allowing it to scale compute and storage resources independently. This enables users to pay for only the resources they need, making it a cost-effective solution for data warehousing and analytical workloads.
Top 10 use cases of Microsoft Azure SQL Data Warehouse:
- Data Warehousing: Storing and querying large datasets for analytical and reporting purposes.
- Business Intelligence (BI): Building and delivering interactive dashboards and reports for data-driven decision-making.
- Data Analytics: Running complex analytical queries on large volumes of data.
- ETL (Extract, Transform, Load): Ingesting, transforming, and loading data from various sources into Azure SQL Data Warehouse.
- Data Integration: Integrating and consolidating data from different sources for analysis.
- Real-time Analytics: Combining real-time data streams with Azure SQL Data Warehouse for near real-time analytics.
- Customer Segmentation: Analyzing customer data to identify segments and patterns.
- Predictive Analytics: Building and training predictive models for forecasting and data-driven insights.
- Financial Analytics: Analyzing financial data for budgeting, forecasting, and performance analysis.
- Data Archiving and Retention: Storing historical data for compliance and reporting purposes.
What are the feature of Microsoft Azure SQL Data Warehouse?
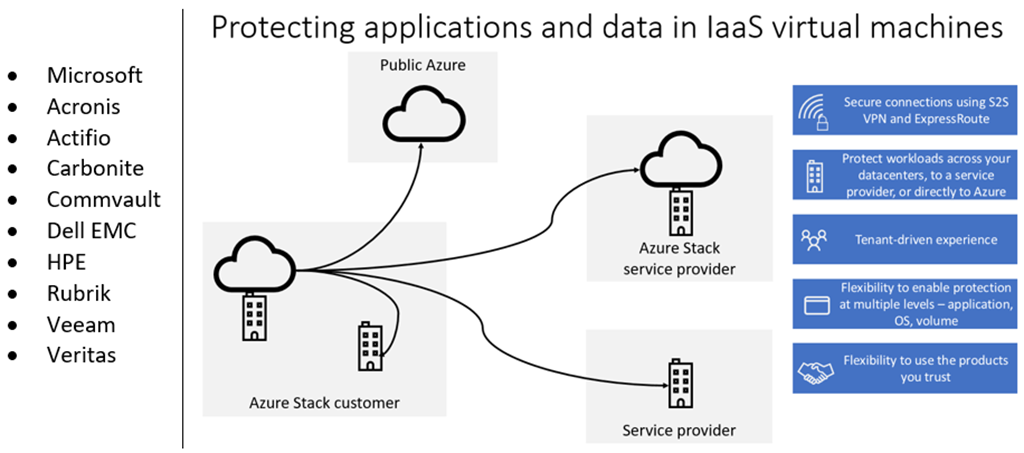
- Fully Managed: Azure SQL Data Warehouse is fully managed by Microsoft, reducing the need for administrative tasks.
- Elastic Scaling: It supports independent scaling of compute and storage resources to match the workload demands.
- Columnar Storage: Data is stored in a columnar format, optimizing query performance.
- MPP Architecture: Utilizes parallel processing across multiple nodes for faster query execution.
- Integration with Azure Ecosystem: Seamless integration with other Azure services like Azure Data Factory, Azure Databricks, etc.
- Security and Compliance: Provides robust security features, including data encryption, auditing, and compliance certifications.
- Automatic Backups: Offers automated backups and point-in-time recovery options for data protection.
How Microsoft Azure SQL Data Warehouse works and Architecture?
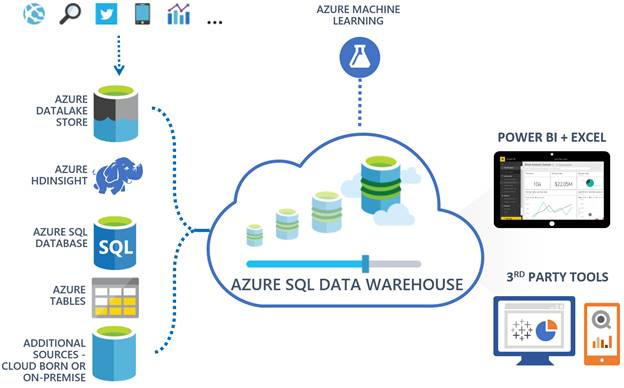
Azure SQL Data Warehouse follows a Massively Parallel Processing (MPP) architecture. It consists of two main components:
- Control Node: The control node acts as the gatekeeper for all queries submitted to the data warehouse. It optimizes queries, creates query plans, and coordinates the distribution of data processing across the compute nodes.
- Compute Nodes: The compute nodes are responsible for executing queries and processing data in parallel. They store and process data in columnar format, which enhances query performance.
Azure SQL Data Warehouse separates storage from compute, allowing users to scale them independently based on their workload requirements. Data is stored in Azure Blob Storage, and users can dynamically allocate or deallocate compute resources as needed.
How to Install Microsoft Azure SQL Data Warehouse?
To use Microsoft Azure SQL Data Warehouse, you don’t need to install it locally. Instead, you follow these steps to create and use an Azure SQL Data Warehouse:
- Sign in to Microsoft Azure: Go to the Microsoft Azure portal (https://portal.azure.com/) and sign in with your Azure account.
- Create an Azure SQL Data Warehouse: Create an Azure SQL Data Warehouse through the Azure portal. Configure the settings, such as resource group, server, performance level, and database name.
- Connect to Azure SQL Data Warehouse: Connect to your Azure SQL Data Warehouse using SQL Server Management Studio (SSMS) or other SQL clients.
- Load Data into Azure SQL Data Warehouse: Load data into your data warehouse using Azure Data Factory, Azure Databricks, or other ETL tools.
- Run Queries and Analyze Data: Use SQL queries to perform data analysis and gain insights from your data.
- Monitor and Optimize Performance: Monitor the performance of your Azure SQL Data Warehouse and optimize it for better query performance.
Please note that Microsoft Azure SQL Data Warehouse is a cloud-based service, and you interact with it using SQL clients or other Azure services through the Azure portal or APIs. There is no traditional installation process on your local machine.
Basic Tutorials of Microsoft Azure SQL Data Warehouse: Getting Started
Before you can start using Azure SQL Data Warehouse, you’ll need to sign up for a Microsoft Azure account. Once you have an account, you can create a new Azure SQL Data Warehouse instance.

Creating an Azure SQL Data Warehouse Instance
To create an Azure SQL Data Warehouse instance, follow these steps:
- Sign in to your Azure account
- Select the “Create a resource” option in the top left corner
- Search for “SQL Data Warehouse” and select it from the list of options
- Click “Create”
- Fill out the necessary information, such as the name of your instance and the pricing tier you want to use
- Click “Create”
Once your instance is created, you’re ready to start using Azure SQL Data Warehouse!
Basic Tasks in Azure SQL Data Warehouse
Creating Tables
To create a table in Azure SQL Data Warehouse, you’ll need to use Transact-SQL (T-SQL). See, I have an example of creating a simple table:
CREATE TABLE Sales (
ProductID INT,
ProductName NVARCHAR(50),
SaleDate DATE,
SaleAmount DECIMAL(10,2)
);This creates a table called “Sales” with four columns: ProductID, ProductName, SaleDate, and SaleAmount.
Loading Data into Tables
To load data into a table in Azure SQL Data Warehouse, you can use the COPY command. Here’s an example of copying data from a CSV file into the Sales table:
COPY INTO Sales
FROM 'https://example.com/sales.csv'
WITH (
FORMAT = 'CSV',
FIELDTERMINATOR = ','
);This copies the data from the sales.csv file into the Sales table.
Querying Data
To query data in Azure SQL Data Warehouse, you’ll use T-SQL. See, I have an example of a simple SELECT statement:
SELECT *
FROM Sales
WHERE SaleAmount > 1000;This selects all rows from the Sales table where the SaleAmount is greater than 1000.
Advanced Tasks in Azure SQL Data Warehouse
Partitioning Tables
Partitioning tables in Azure SQL Data Warehouse can improve query performance by dividing large tables into smaller, more manageable parts. Here’s an example of partitioning the Sales table by SaleDate:
CREATE CLUSTERED COLUMNSTORE INDEX Sales_CCI
ON Sales(SaleDate)
WITH (DROP_EXISTING = ON);This creates a clustered columnstore index on the Sales table, partitioned by SaleDate.
Optimizing Query Performance
To optimize query performance in Azure SQL Data Warehouse, you can use various techniques. One common technique is to use distributed tables, which can improve query performance by distributing data across multiple nodes. Here’s an example of creating a distributed table:
CREATE TABLE Sales_Distributed
WITH (
DISTRIBUTION = HASH(ProductID),
CLUSTERED COLUMNSTORE INDEX
)
AS SELECT *
FROM Sales;This creates a distributed table called “Sales_Distributed” that is distributed by the ProductID column.
In this article, we covered the basics of using Microsoft Azure SQL Data Warehouse. We started by getting started with Azure SQL Data Warehouse, then covered basic tasks like creating tables, loading data into tables, and querying data. We also covered advanced tasks like partitioning tables and optimizing query performance. With this knowledge, you’re well on your way to becoming an Azure SQL Data Warehouse expert!
Email- contact@devopsschool.com
