
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comWhat is NLTK?

NLTK stands for Natural Language Toolkit. It’s a popular open-source Python library that provides tools and resources for working with human language data (text) for natural language processing (NLP) tasks. NLTK was developed by the Natural Language Processing Group at the University of Pennsylvania and is widely used by researchers, developers, and students in the field of NLP.
Top 10 use cases of NLTK:
Here are the top 10 use cases of NLTK:
- Text Tokenization: NLTK offers tools to break down text into individual words or sentences, a fundamental step in many NLP tasks.
- Part-of-Speech Tagging: NLTK can tag words in a text with their corresponding part-of-speech (e.g., noun, verb, adjective), which is crucial for understanding sentence structure and meaning.
- Sentiment Analysis: NLTK can be used to determine the sentiment or emotional tone of a piece of text, helping businesses gauge public opinion about products, services, or events.
- Text Classification: NLTK enables the creation of models for categorizing text into predefined classes, such as spam detection, topic classification, or sentiment-based categorization.
- Named Entity Recognition (NER): NLTK can identify and classify named entities in text, such as names of people, organizations, locations, and dates.
- Language Modeling: NLTK supports the creation of language models that predict the likelihood of a word or sequence of words occurring in a given context, which is useful for tasks like auto-completion.
- Information Retrieval: NLTK can help build search engines or information retrieval systems that rank and retrieve relevant documents based on user queries.
- Concordance and Collocation Analysis: NLTK can assist in analyzing word collocations (words that frequently appear together) and generate concordances (contexts in which words appear) for specific terms in a text.
- Machine Translation: While NLTK isn’t primarily designed for machine translation, it can be used as a foundation to develop simple translation systems.
- Language Learning and Teaching: NLTK can aid in creating educational tools for language learners by providing resources to analyze text, understand grammar, and learn vocabulary in context.
These are just a few examples of the wide range of applications that NLTK supports. Its comprehensive collection of text processing libraries, corpora (textual datasets), and algorithms make it a versatile toolkit for various NLP tasks.
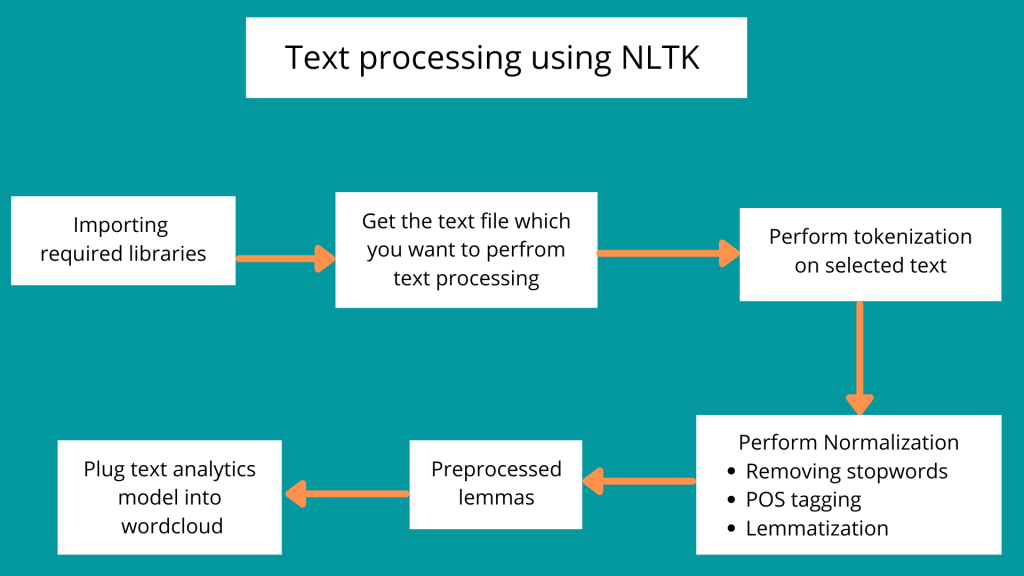
What are the feature of NLTK?
The Natural Language Toolkit (NLTK) is a suite of libraries and programs for natural language processing (NLP) in Python. It provides a wide range of tools, resources, and algorithms for working with human language data. Here are some of the key features of NLTK:
- Text Processing Utilities: NLTK offers a variety of functions for text preprocessing, such as tokenization, stemming, lemmatization, and stopword removal.
- Part-of-Speech Tagging: NLTK includes tools for assigning part-of-speech tags to words in a text, enabling syntactic and grammatical analysis.
- Named Entity Recognition (NER): NLTK can identify and classify named entities like names of people, organizations, locations, and more.
- Sentiment Analysis: NLTK includes sentiment analysis modules that help classify text as positive, negative, or neutral, based on its emotional tone.
- Parsing: NLTK provides parsers that can be used to analyze the grammatical structure of sentences and generate syntactic trees.
- Corpora and Language Resources: NLTK comes with a wide range of corpora (textual datasets) and language resources that can be used for training and testing NLP models.
- Language Modeling: NLTK supports the creation of language models that predict the likelihood of words or sequences of words occurring in specific contexts.
- Information Retrieval: NLTK includes tools for building search engines, indexing documents, and ranking results based on relevance.
- Concordance and Collocation Analysis: NLTK provides features to analyze word collocations (common word pairs) and generate concordances (contextual occurrences) for specific words.
- Machine Learning: While not as extensive as dedicated machine learning libraries, NLTK includes some basic machine learning algorithms for tasks like classification and clustering.
- Categorization and Classification: NLTK supports text categorization tasks, where text documents are assigned to predefined categories.
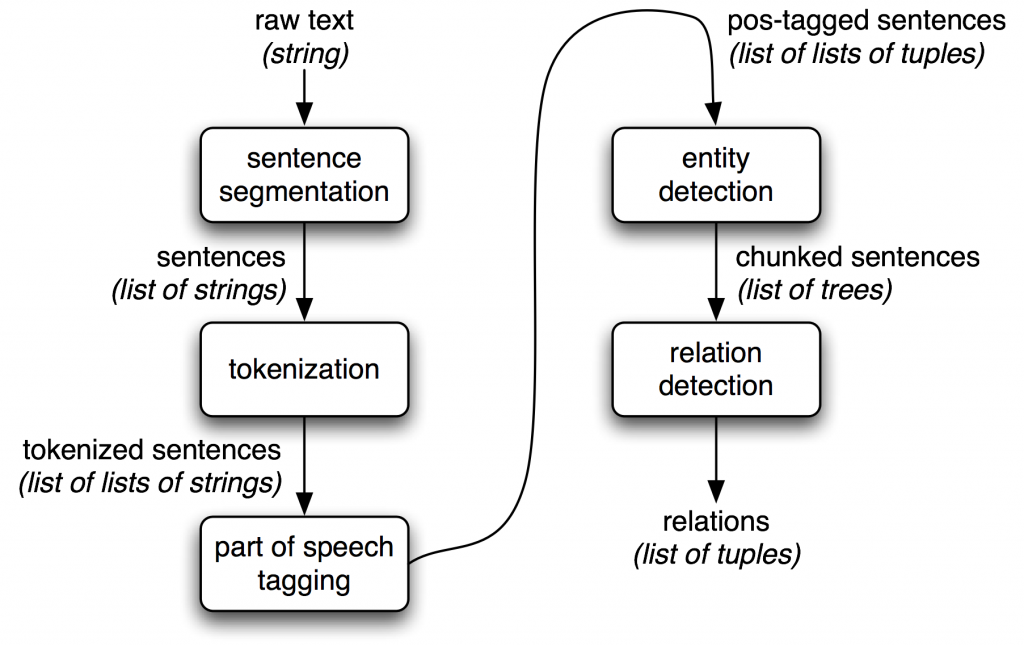
How NLTK works and Architecture?
Now, let’s discuss how NLTK works and its architecture:
1. Corpus and Data: NLTK offers various corpora and linguistic resources that serve as datasets for training and testing NLP models. These datasets cover a wide range of languages and topics.
2. Tokenization and Preprocessing: Before analyzing text, NLTK preprocesses it by breaking it into words or sentences through tokenization. It may also perform stemming, lemmatization, and other text cleaning tasks.
3. Analysis and Tagging: NLTK provides tools to analyze the syntactic and semantic aspects of text, including part-of-speech tagging and parsing to understand sentence structure.
4. Named Entity Recognition: NLTK includes models and algorithms for recognizing named entities in text, such as identifying names, dates, and locations.
5. Sentiment Analysis: NLTK’s sentiment analysis modules use predefined lexicons or machine learning algorithms to determine the sentiment polarity of text.
6. Machine Learning: While NLTK includes some basic machine learning algorithms, it’s not as focused on machine learning as some other libraries. For more advanced machine learning, users might combine NLTK with other dedicated libraries like scikit-learn.
7. Information Retrieval: NLTK provides tools to build simple search engines, index documents, and retrieve relevant information based on user queries.
8. Language Resources: NLTK offers resources like word lists, thesauri, and language models that can aid in various NLP tasks.
NLTK’s architecture is not as formalized as some other software systems. It’s organized as a collection of modules that cover different areas of NLP. Users can import and use specific modules based on their requirements. NLTK’s architecture is designed to provide flexibility and modularity, allowing users to choose the functionalities they need while working with text data.
How to Install NLTK?
There are two ways to install NLTK:
- Using pip
- Open a terminal window.
- Install NLTK using the following command:
pip install nltk- Using Anaconda
- If you have Anaconda installed, you can install NLTK using the following command:
conda install nltkOnce NLTK is installed, you can verify the installation by running the following command in a Python interpreter:
import nltkIf the installation is successful, this command will not print any output.
Here are some additional things to keep in mind when installing NLTK:
- NLTK requires Python 3.6 or higher.
- NLTK also requires some additional libraries, such as NumPy and SciPy. These libraries will be installed automatically when you install NLTK using pip or Anaconda.
- NLTK comes with a large number of corpora (datasets of text and speech). These corpora are not installed by default. To install a corpus, you can use the following command:
nltk.download('corpus_name')For example, to install the Brown corpus, you would run the following command:
nltk.download('brown')Basic Tutorials of NLTK: Getting Started

The following steps are the basic tutorials of NLTK:
- Tokenization
- Import the necessary modules:
import nltk
- Tokenize a sentence:
- Import the necessary modules:
sentence = "This is a sentence."tokens = nltk.word_tokenize(sentence)print(tokens)
This will print the following output: ['This', 'is', 'a', 'sentence']
2. Stemming and Lemmatization
- Stemming is the method of decreasing a word to its base form. For example, the word “running” would be stemmed to “run”.
- Lemmatization is the process of grouping together words that have the same meaning, even if they have different forms. For example, the words “running”, “ran”, and “run” would all be lemmatized to “run”.
- Import the necessary modules:
import nltk from nltk.stem import PorterStemmer from nltk.stem import WordNetLemmatizer - Stem a word:
stemmer = PorterStemmer() stemmed_word = stemmer.stem("running") print(stemmed_word)This will print the following output:run - Lemmatize a word: lemmatizer = WordNetLemmatizer()
lemmatized_word = lemmatizer.lemmatize(“running”)
print(lemmatized_word)This will print the following output:run
3. Part-of-speech tagging
- The Part-of-speech tagging method is used for allocating a part-of-speech tag to each word in a sentence. The most common part-of-speech tags are noun, verb, adjective, adverb, pronoun, preposition, conjunction, and interjection.
- Import the necessary modules: import nltk
from nltk.tag import pos_tag
“` - Tag a sentence:
sentence = "NLTK is a powerful library for natural language processing." tags = pos_tag(sentence) print(tags)This will print the following output: “`
[(‘NLTK’, ‘NNP’), (‘is’, ‘VBZ’), (‘a’, ‘DT’), (‘powerful’, ‘JJ’), (‘library’, ‘NN’), (‘for’, ‘IN’), (‘natural’, ‘JJ’), (‘language’, ‘NN’), (‘processing’, ‘NN’), (‘sentence’, ‘NN’)] Every tuple is a word is the first element and the part-of-speech tag is the second element.
4. Named entity recognition
- Named entity recognition (NER) is the method of recognizing named entities in a text. Named entities are things like people, organizations, locations, and dates.
- Import the necessary modules: import nltk
from nltk.tag import named_entities
“` - In a sentence, identify named entities:
sentence = "Bard is a large language model from Google AI, trained on a massive dataset of text and code."
named_entities = named_entities(sentence)
print(named_entities) This will print the following output: “`
[(‘Bard’, ‘PERSON’), (‘Google AI’, ‘ORGANIZATION’)] The first element of each tuple is the named entity, and the second element is the type of named entity.
These are just a few of the basic tutorials available for NLTK. I encourage you to explore the documentation and tutorials to learn more about this powerful natural language processing toolkit.
Email- contact@devopsschool.com
