
 Starting: 1st of Every Month
Starting: 1st of Every Month  +91 8409492687
+91 8409492687  Contact@DevOpsSchool.com
Contact@DevOpsSchool.comWhat is Stanford CoreNLP?

Stanford CoreNLP is an open-source natural language processing (NLP) toolkit developed by the Stanford NLP Group. It provides a set of NLP tools and libraries that can be used for a variety of text processing tasks, including tokenization, part-of-speech tagging, named entity recognition, dependency parsing, sentiment analysis, and more. CoreNLP is written in Java and offers both pre-trained models and customizable components for various NLP tasks.
Top 10 use cases of Stanford CoreNLP:
Here are the top 10 use cases of Stanford CoreNLP:
- Text Analysis: CoreNLP can analyze text data, providing insights into sentence structure, part-of-speech tagging, and word dependencies, which are useful for linguists and researchers.
- Named Entity Recognition (NER): CoreNLP can identify and classify named entities such as names of people, organizations, locations, and dates in text.
- Sentiment Analysis: CoreNLP can determine the sentiment polarity of text, helping businesses understand public opinion and customer feedback.
- Dependency Parsing: CoreNLP performs dependency parsing to analyze the grammatical relationships between words in a sentence, which aids in understanding sentence structure.
- Tokenization: CoreNLP’s tokenization module breaks down text into individual tokens (words and punctuation), a fundamental step in various NLP tasks.
- Constituency Parsing: CoreNLP can generate constituency parse trees, which represent the syntactic structure of a sentence using hierarchical structures.
- Coreference Resolution: CoreNLP can identify and resolve coreference relationships, helping to understand which words or phrases refer to the same entities.
- Text Summarization: By extracting key phrases and relationships from text, CoreNLP can assist in generating concise and coherent text summaries.
- Question Answering: CoreNLP can be used in question answering systems to identify relevant information and relationships in text for answering user queries.
- Entity Linking: CoreNLP can link recognized named entities to external knowledge bases like Wikipedia, providing additional context and information about the entities.
These use cases highlight CoreNLP’s versatility in addressing a wide range of NLP tasks. It’s worth noting that while CoreNLP is a powerful toolkit, it requires some programming skills to set up and use effectively. Additionally, there are other NLP libraries and tools available, such as spaCy, NLTK, and Hugging Face Transformers, each with its own strengths and features.
What are the feature of Stanford CoreNLP?
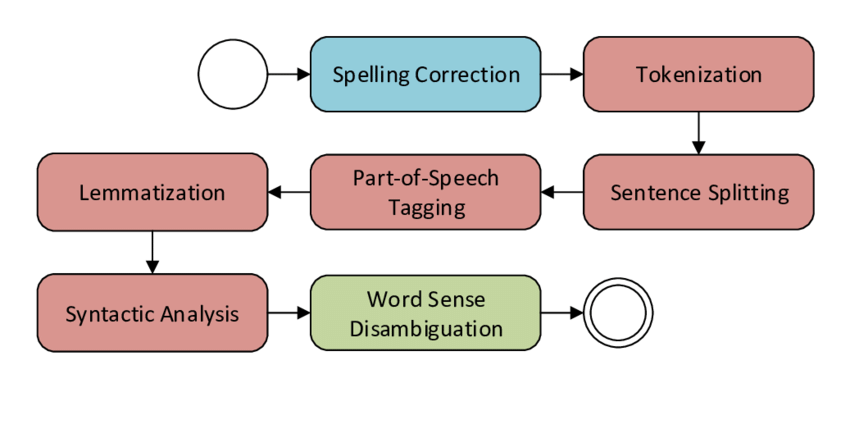
Stanford CoreNLP is a comprehensive natural language processing (NLP) toolkit developed by the Stanford NLP Group. It provides a wide range of features for analyzing and processing text data. Here are some of the key features of Stanford CoreNLP:
- Tokenization: CoreNLP can tokenize text, splitting it into individual words, punctuation, and other meaningful units.
- Part-of-Speech Tagging: CoreNLP can assign part-of-speech tags to words in a sentence, indicating their grammatical roles (noun, verb, adjective, etc.).
- Named Entity Recognition (NER): CoreNLP can identify and classify named entities in text, such as names of people, organizations, locations, and more.
- Dependency Parsing: CoreNLP performs dependency parsing to analyze the grammatical relationships between words in a sentence, creating a syntactic tree structure.
- Coreference Resolution: CoreNLP can identify and resolve coreference relationships, determining which words refer to the same entities in a text.
- Sentiment Analysis: CoreNLP can determine the sentiment polarity of text, classifying it as positive, negative, or neutral.
- Constituency Parsing: CoreNLP generates constituency parse trees that represent the hierarchical structure of sentences.
- Lemma Generation: CoreNLP can generate lemmas, which are the base or dictionary forms of words, aiding in text normalization.
- NER Features: CoreNLP provides fine-grained named entity recognition with features like temporal and numeric entity recognition.
- Language Support: CoreNLP supports multiple languages and offers pre-trained models for various languages.
How Stanford CoreNLP works and Architecture?
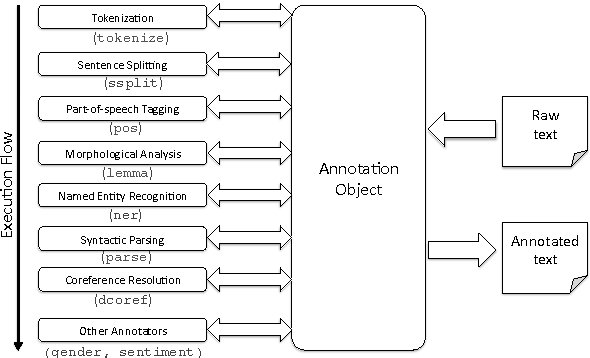
Now, let’s delve into how Stanford CoreNLP works and its architecture:
1. Text Annotation Pipeline:
CoreNLP processes text through an annotation pipeline, which consists of a sequence of processing stages. Each stage adds annotations to the text, enriching it with linguistic information.
2. Input Text: The input text is tokenized into words, sentences, and other units, forming the basis for further analysis.
3. Tokenization and Part-of-Speech Tagging: CoreNLP tokenizes the text and assigns part-of-speech tags to each token, providing grammatical context.
4. Named Entity Recognition (NER): CoreNLP identifies named entities in the text and classifies them into predefined categories like person, organization, location, and more.
5. Dependency Parsing: CoreNLP performs dependency parsing, analyzing word relationships to create a syntactic tree that represents sentence structure.
6. Coreference Resolution: CoreNLP resolves coreference relationships by determining which words refer to the same entities in the text.
7. Sentiment Analysis: CoreNLP’s sentiment analysis module classifies text into positive, negative, or neutral sentiment categories.
8. Output Annotations: The output annotations provide a rich representation of the input text’s linguistic properties, including tokenization, part-of-speech tags, named entities, syntactic dependencies, and more.
9. Customization: CoreNLP offers customizable options, allowing users to select which processing stages to include and adapt models to specific tasks or domains.
10. Integration: CoreNLP can be integrated into various applications through Java programming or command-line usage. It also provides server and web-based interfaces for easy access.
CoreNLP’s architecture emphasizes modularity and flexibility, enabling users to select and configure processing components based on their requirements. By following the annotation pipeline, CoreNLP transforms unstructured text data into structured annotations that capture linguistic insights.
How to Install Google Cloud Natural Language API
There are two ways to install Stanford CoreNLP:
- Using pip
- Open a terminal window.
- Install Stanford CoreNLP using the following command:
pip install stanfordcorenlp- Downloading and installing from source
- Download the Stanford CoreNLP distribution from the Stanford NLP website: https://stanfordnlp.github.io/CoreNLP/.
- Unzip the distribution.
- Navigate to the directory, after opening a terminal window where you unzipped the distribution.
- Run the following command to install Stanford CoreNLP:
java -cp "*" -mx4g edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 This will start a Stanford CoreNLP server on port 9000.
Once Stanford CoreNLP is installed, you can verify the installation by running the following command in a Python interpreter:
import stanfordcorenlpIf the installation is successful, this command will not print any output.
Here are some additional things to keep in mind when installing Stanford CoreNLP:
- Stanford CoreNLP requires Java 8 or higher.
- Stanford CoreNLP also requires some additional libraries, such as protobuf and xom. These libraries are included in the Stanford CoreNLP distribution.
- Stanford CoreNLP is a large and complex software package. It may take some time to install and configure.
Basic Tutorials of Stanford CoreNLP: Getting Started

The following are the steps of basic tutorials of Stanford CoreNLP:
- Importing Stanford CoreNLP
- Import the Stanford CoreNLP library:
Python
import stanfordcorenlp
- Creating a pipeline
- Create a pipeline that includes the following components:
- Tokenizer: This component breaks the text into tokens.
- Part-of-speech tagger: This component assigns part-of-speech tags to each token.
- Named entity recognizer: This component identifies named entities in the text.
- Create a pipeline that includes the following components:
Python
pipeline = stanfordcorenlp.Pipeline()
- Processing text
- Pass the text to the pipeline:
Python
document = pipeline.process("This is a sentence.")
This will return a document object that contains the outcomes of the processing. - Accessing the results
- The document object has a number of properties that you can access, such as the tokens, the part-of-speech tags, and the named entities.
Python
for token in document.tokens:
print(token.text, token.pos)
This will print the tokens in the document, along with their part-of-speech tags. - Named entity recognition
- Identify named entities in the document:
Python
for entity in document.entities:
print(entity.text, entity.type)
This will print the named entities in the document, along with their types. These are just a few of the basic tutorials available for Stanford CoreNLP. I encourage you to explore the documentation and tutorials to learn more about this powerful natural language processing toolkit.
Email- contact@devopsschool.com
