Machine Learning (ML) is a rapidly evolving field within Artificial Intelligence (AI) that enables computers to learn from data and make decisions with minimal human intervention. At the heart of Machine Learning is the concept of Supervised Learning, one of its most widely used and understood branches. This blog provides a detailed exploration of Supervised Learning, covering its fundamental concepts, key algorithms, practical applications, and how to get started with implementing these techniques.
What is Machine Learning?
Before diving into Supervised Learning, it’s essential to understand the basic idea of Machine Learning. The term “Machine Learning” can be broken down into two components:
- Machine: Refers to the computers or systems that perform tasks. These machines are capable of processing data, running algorithms, and executing tasks without explicit human programming for each action.
- Learning: Implies the ability of these machines to improve their performance on a task over time. This learning is achieved by identifying patterns, making predictions, or adjusting to new data through various algorithms and techniques.
Thus, Machine Learning is a field of study that allows machines to learn from data, adapt to changes, and improve their performance on specific tasks.
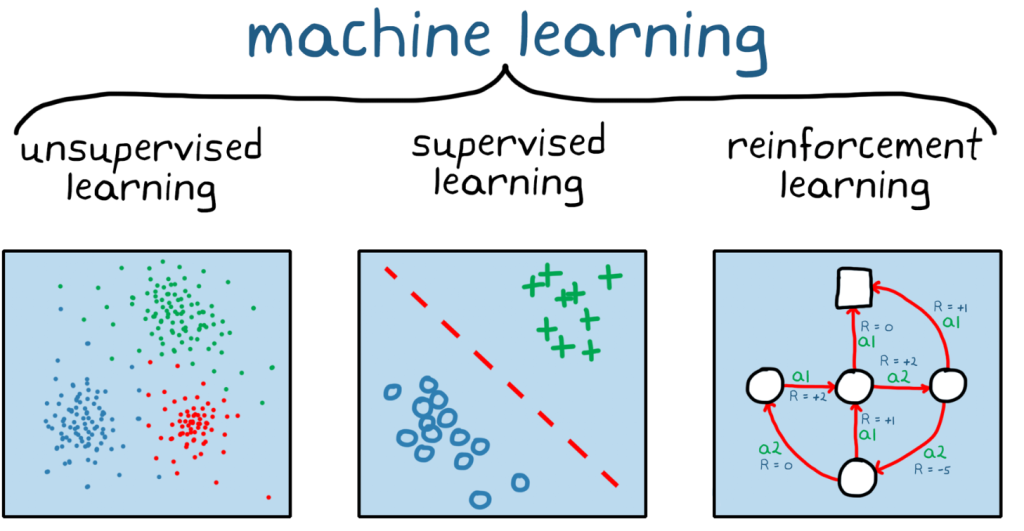
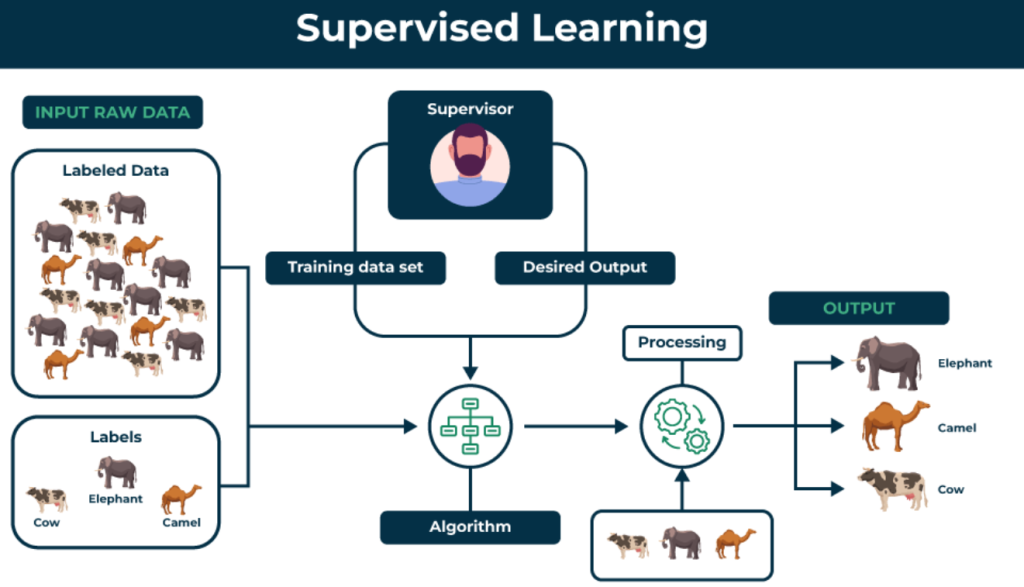
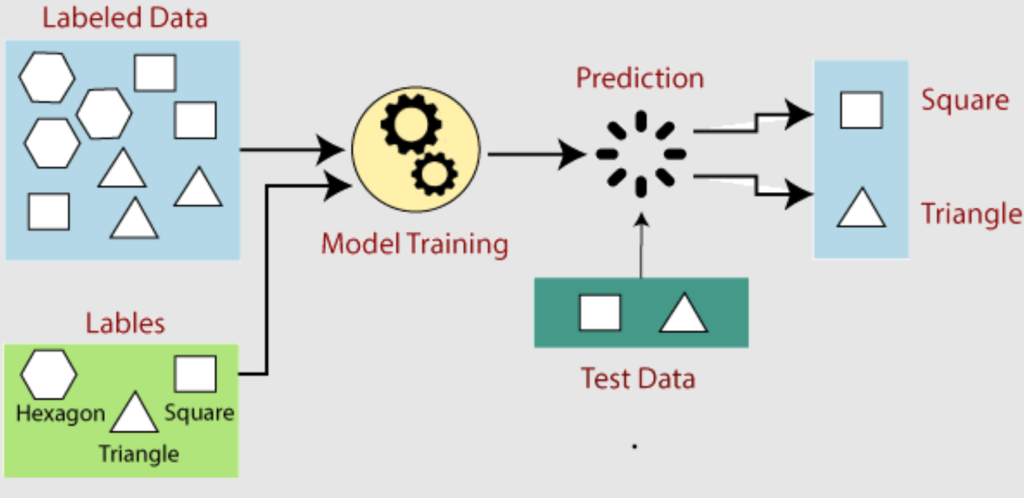
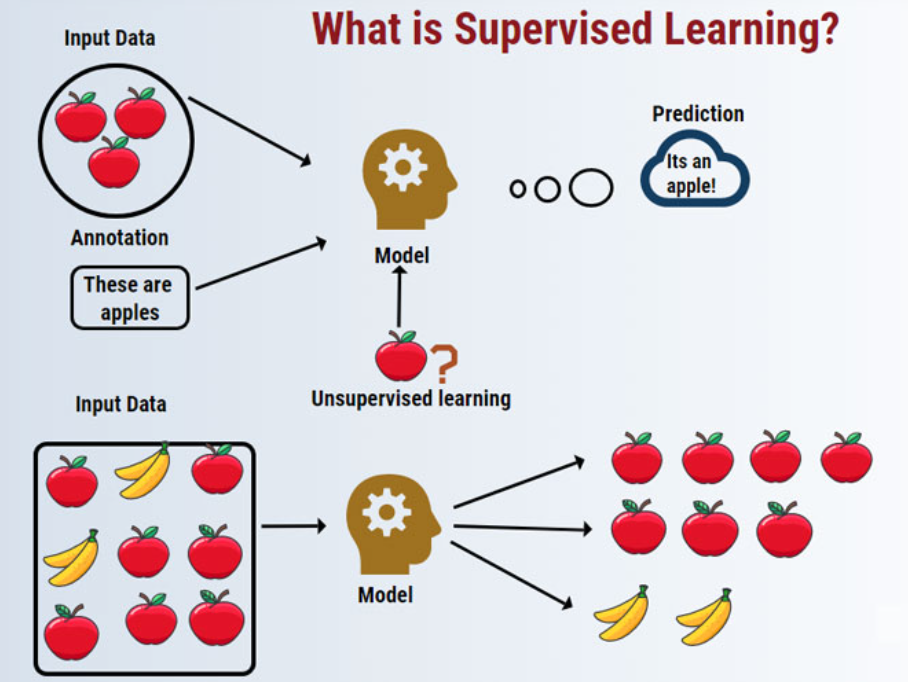
What is Supervised Learning?
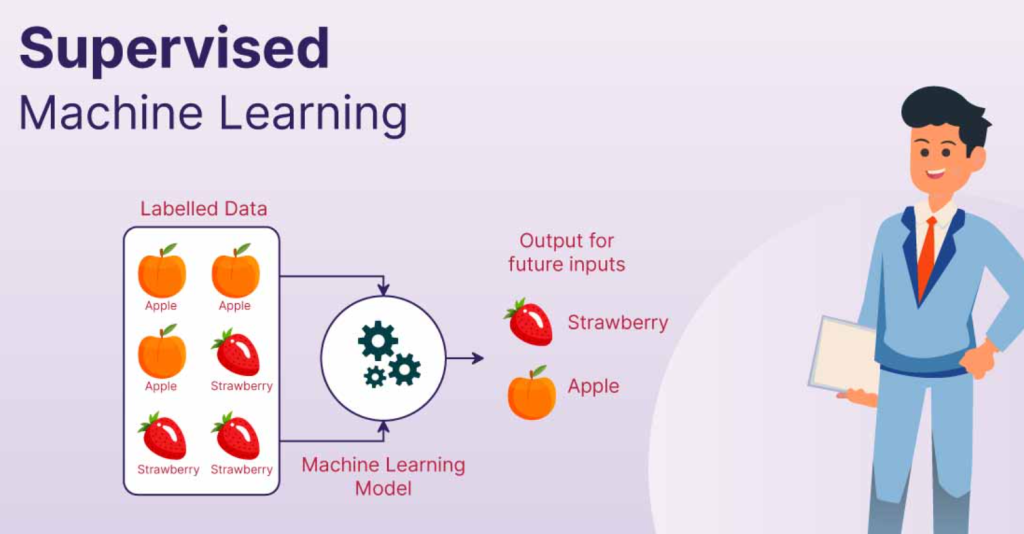
Supervised Learning is a subset of Machine Learning where the model is trained on a labeled dataset. In this context:
- Labeled Data: Refers to a dataset where each example is paired with an output label. For instance, in a dataset used to classify emails as spam or not spam, each email (input) is labeled as either “spam” or “not spam” (output).
The primary goal of Supervised Learning is to learn a mapping function from input to output, enabling the model to predict the output for new, unseen data. Supervised Learning can be broadly categorized into two types:
- Classification: When the output variable is categorical (e.g., “spam” or “not spam”).
- Regression: When the output variable is continuous (e.g., predicting house prices).
Key Concepts in Supervised Learning
1. Training and Testing
- Training Set: The dataset used to train the model. It includes input-output pairs that the model learns from.
- Testing Set: A separate dataset used to evaluate the model’s performance. It ensures that the model generalizes well to unseen data.
2. Features and Labels
- Features: The input variables or attributes used to make predictions. For example, in a housing dataset, features could include the number of bedrooms, square footage, and location.
- Labels: The output or target variable that the model is trying to predict. In the housing example, the label could be the house price.
3. Model Evaluation Metrics
- Accuracy: The percentage of correct predictions made by the model.
- Precision and Recall: Precision measures the proportion of true positive results among all positive predictions, while recall measures the proportion of true positives identified out of all actual positives.
- Mean Squared Error (MSE): Used in regression, it measures the average squared difference between actual and predicted values.
Common Algorithms in Supervised Learning
Several algorithms can be used for Supervised Learning, each with its strengths and suitable use cases. Below are some of the most commonly used algorithms:
1. Linear Regression
- Type: Regression
- Description: Linear Regression models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data. It is one of the simplest and most interpretable algorithms.
- Use Case: Predicting house prices based on features like size, number of rooms, and location.
2. Logistic Regression
- Type: Classification
- Description: Despite its name, Logistic Regression is used for classification tasks. It predicts the probability that a given input belongs to a specific class using the logistic function.
- Use Case: Classifying emails as spam or not spam.
3. Decision Trees
- Type: Classification and Regression
- Description: Decision Trees are tree-like models where decisions are made by splitting the data into subsets based on the values of input features. Each branch represents a decision rule, and each leaf represents an outcome.
- Use Case: Predicting customer churn in a subscription service.
4. Support Vector Machines (SVM)
- Type: Classification
- Description: SVM finds the hyperplane that best separates different classes in the feature space. It is effective in high-dimensional spaces and is used for both linear and non-linear classification.
- Use Case: Image classification tasks, such as identifying objects in images.
5. k-Nearest Neighbors (k-NN)
- Type: Classification and Regression
- Description: k-NN is a simple, instance-based learning algorithm where predictions are made based on the majority vote of the k-nearest neighbors in the feature space.
- Use Case: Recommender systems, where recommendations are made based on the preferences of similar users.
6. Random Forest
- Type: Classification and Regression
- Description: Random Forest is an ensemble learning method that builds multiple decision trees and merges their predictions to improve accuracy and control overfitting.
- Use Case: Diagnosing diseases based on patient data.
7. Neural Networks
- Type: Classification and Regression
- Description: Neural Networks consist of layers of interconnected nodes (neurons) that transform input data to predict the output. They are the foundation of deep learning and are used for complex pattern recognition tasks.
- Use Case: Handwriting recognition, speech recognition, and image classification.
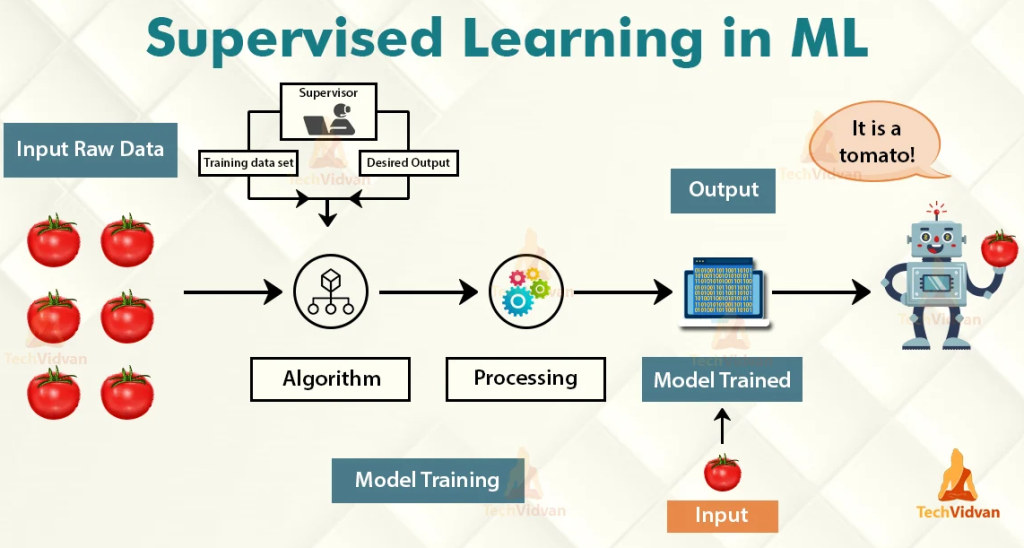
How to Implement Supervised Learning: A Step-by-Step Guide
Implementing Supervised Learning involves several steps, from data preparation to model evaluation. Here’s a basic outline:
1. Data Collection
- Gather data relevant to the problem you want to solve. The quality and quantity of data significantly impact the model’s performance.
2. Data Preprocessing
- Cleaning: Handle missing values, remove duplicates, and address inconsistencies in the data.
- Normalization/Standardization: Scale features so that they contribute equally to the model’s predictions.
- Splitting: Divide the dataset into training and testing sets.
3. Choosing a Model
- Select an appropriate algorithm based on the problem type (classification or regression) and the characteristics of your data.
4. Training the Model
- Use the training set to teach the model by allowing it to learn from the input-output pairs.
5. Evaluating the Model
- Use the testing set to evaluate the model’s performance using appropriate metrics like accuracy, precision, recall, or MSE.
6. Hyperparameter Tuning
- Optimize the model by adjusting parameters to improve performance.
7. Deploying the Model
- Once satisfied with the model’s performance, deploy it to make predictions on new data.
Applications of Supervised Learning
Supervised Learning is used in various industries to solve a wide range of problems:
- Healthcare: Predicting patient outcomes, diagnosing diseases, and personalizing treatment plans.
- Finance: Credit scoring, fraud detection, and stock price prediction.
- Marketing: Customer segmentation, targeted advertising, and sentiment analysis.
- Retail: Demand forecasting, inventory management, and recommendation systems.
Challenges in Supervised Learning
Despite its widespread use, Supervised Learning comes with its own set of challenges:
- Overfitting: When a model learns the training data too well, including noise and outliers, leading to poor performance on new data.
- Underfitting: When a model is too simple to capture the underlying patterns in the data, resulting in poor performance on both training and testing sets.
- Data Dependency: Requires large amounts of labeled data, which can be time-consuming and expensive to obtain.
- Bias and Variance: Balancing bias (error due to oversimplified assumptions) and variance (error due to model complexity) is crucial for optimal model performance.
Conclusion
Supervised Learning is a powerful tool in the Machine Learning arsenal, enabling models to make accurate predictions and decisions across a variety of domains. By understanding the fundamental concepts, key algorithms, and best practices, you can harness the power of Supervised Learning to solve real-world problems effectively. As you embark on your journey into Supervised Learning, remember that the quality of your data, the choice of algorithms, and careful evaluation are all critical components of building successful models. With continued learning and practice, you can master the art of Supervised Learning and contribute to the rapidly advancing field of Artificial Intelligence.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
