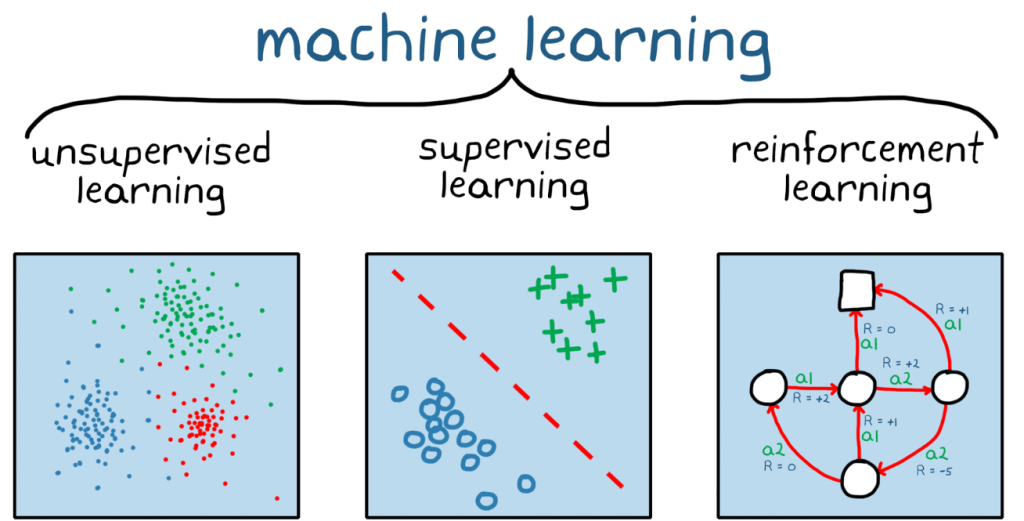
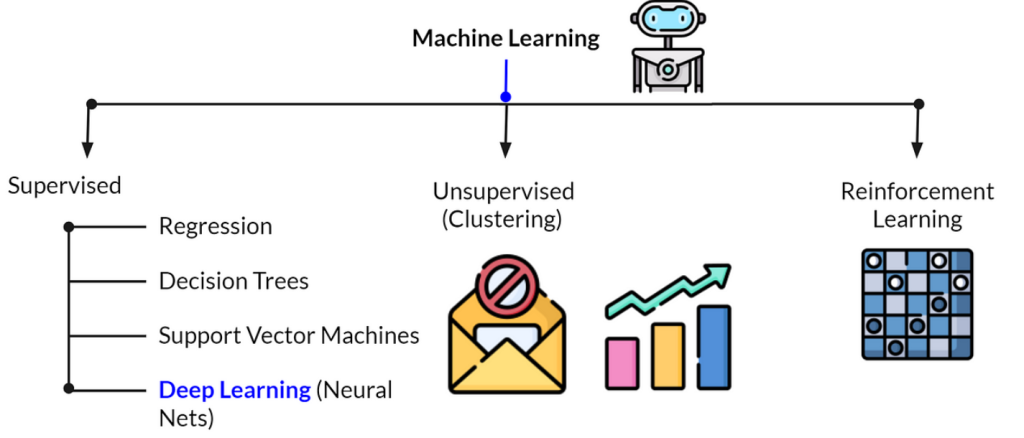
Machine Learning: A Comparison of Supervised Learning, Unsupervised Learning, and Reinforcement Learning
Machine Learning (ML) is a multifaceted field that includes various approaches to teaching machines how to learn from data and improve their performance on tasks. Among these approaches, Supervised Learning, Unsupervised Learning, and Reinforcement Learning are the most prominent. Each has its unique methods, applications, and challenges. In this blog, we will compare these three branches of Machine Learning, highlighting their differences, similarities, and where they are best applied.
Supervised Learning
What is Supervised Learning?
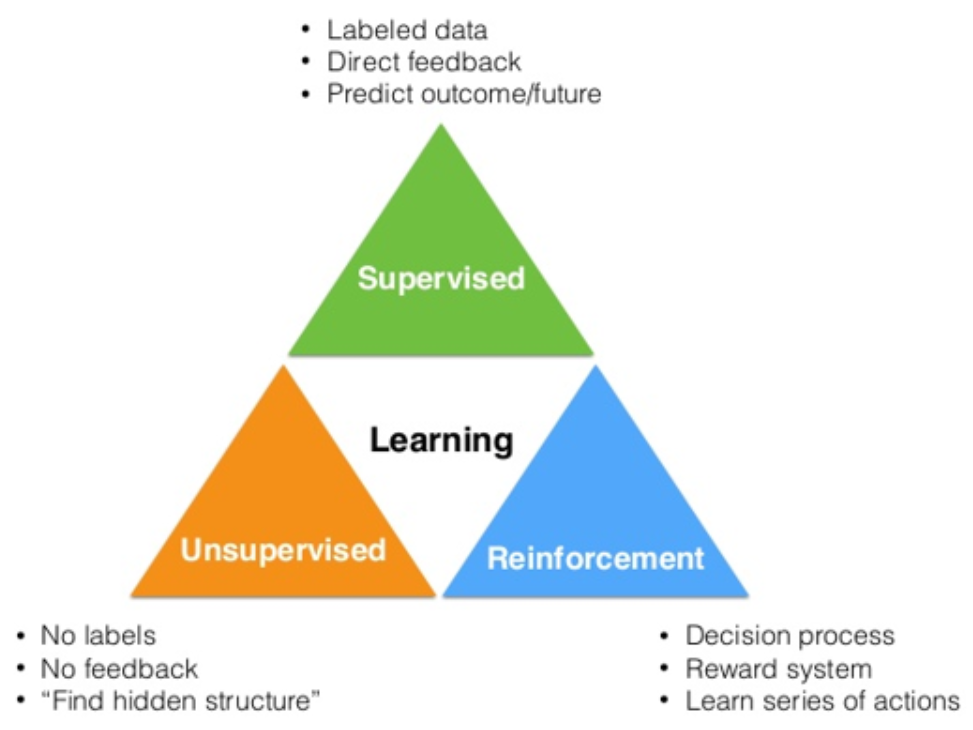
Supervised Learning is a type of machine learning where the model is trained on a labeled dataset. In this context:
- Labeled Data: Each input data point is paired with the correct output label. The model learns to map inputs to outputs based on this training data.
- Goal: The goal is to make accurate predictions or classifications on new, unseen data based on the patterns learned during training.
Key Characteristics:
- Data Requirement: Requires a large amount of labeled data for training.
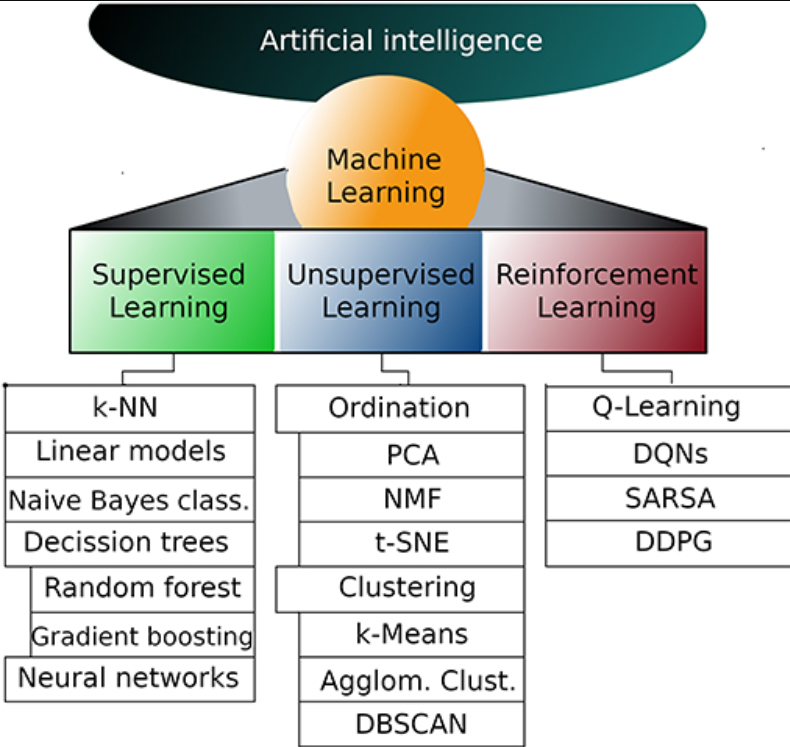
- Model Types: Classification (categorical outputs) and regression (continuous outputs).
- Learning Process: The model is provided with both input data and corresponding output labels during training.
- Evaluation: The performance is evaluated using metrics such as accuracy, precision, recall, and mean squared error (MSE).
Applications:
- Spam Detection: Classifying emails as spam or not spam.
- Image Classification: Identifying objects within images, such as detecting faces.
- Predictive Maintenance: Predicting when a machine is likely to fail based on historical data.
Unsupervised Learning
What is Unsupervised Learning?
Unsupervised Learning is a type of machine learning where the model is trained on a dataset without labeled responses. The model attempts to find hidden patterns or intrinsic structures within the data.
- Unlabeled Data: The data lacks predefined labels, so the model must find structure on its own.
- Goal: The goal is to discover underlying patterns, groupings, or representations within the data.
Key Characteristics:
- Data Requirement: Works with unlabeled data.
- Model Types: Clustering, dimensionality reduction, and anomaly detection.
- Learning Process: The model explores the data to identify patterns or groupings without explicit guidance on what to look for.
- Evaluation: Evaluation is less straightforward than in supervised learning, often relying on metrics like silhouette scores or visual inspection of clusters.
Applications:
- Customer Segmentation: Grouping customers based on purchasing behavior.
- Market Basket Analysis: Identifying items frequently purchased together.
- Anomaly Detection: Detecting outliers in data, such as fraudulent transactions.
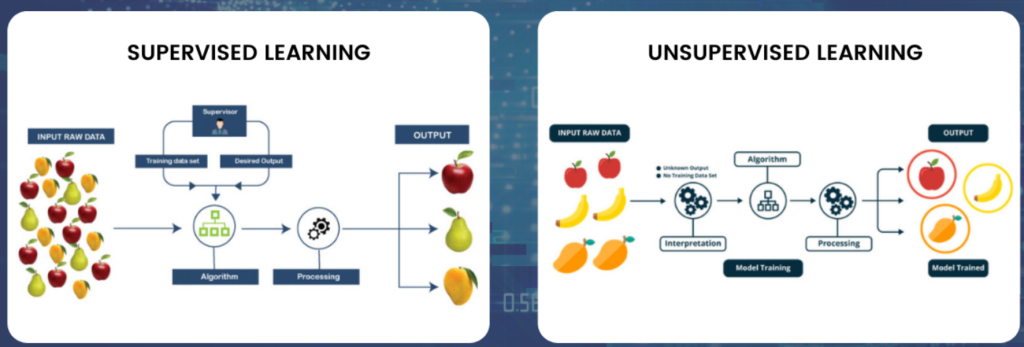
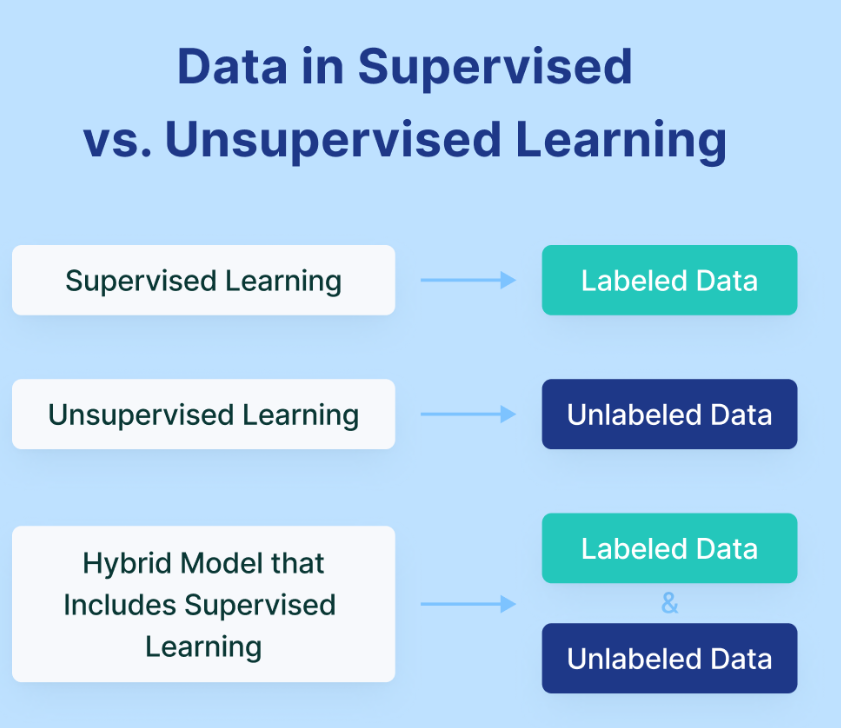
Reinforcement Learning
What is Reinforcement Learning?
Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties, which it uses to learn optimal behavior.
- Interactive Learning: The agent learns by taking actions and observing the consequences in a dynamic environment.
- Goal: The goal is to learn a strategy (policy) that maximizes cumulative rewards over time.
Key Characteristics:
- Data Requirement: The agent learns through trial and error, interacting with the environment.
- Model Types: Q-learning, SARSA, deep Q-networks (DQN), and policy gradient methods.
- Learning Process: The agent balances exploration (trying new actions) and exploitation (choosing the best-known actions) to learn the optimal policy.
- Evaluation: Performance is evaluated based on the cumulative reward obtained by the agent.
Applications:
- Game Playing: Agents learning to play games like chess, Go, or video games at superhuman levels.
- Robotics: Teaching robots to perform tasks like grasping objects or walking.
- Autonomous Vehicles: Developing self-driving cars that can make decisions in real-time based on sensor data.
Comparing Supervised Learning, Unsupervised Learning, and Reinforcement Learning

| Feature | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data Requirement | Labeled data | Unlabeled data | Interactive environment |
| Learning Process | Learn from input-output pairs | Discover patterns in data | Learn from actions and rewards |
| Model Types | Classification, Regression | Clustering, Dimensionality Reduction | Q-learning, Policy Gradients |
| Goal | Predict or classify new data points | Identify hidden structures | Maximize cumulative rewards |
| Examples | Spam detection, Image classification | Customer segmentation, Anomaly detection | Game playing, Robotics |
| Evaluation | Accuracy, Precision, Recall, MSE | Silhouette Score, Explained Variance | Cumulative reward |
| Challenges | Requires large labeled datasets, overfitting | Interpretability, evaluation difficulty | Exploration-exploitation trade-off, sample efficiency |
When to Use Each Approach
- Supervised Learning is ideal when you have a well-labeled dataset and need to predict outcomes or classify data. It’s commonly used in situations where the relationships between inputs and outputs are already known and need to be modeled.
- Unsupervised Learning is useful when you have a dataset without labels and want to explore its structure. It’s perfect for discovering underlying patterns or grouping data into clusters. It’s often used for exploratory data analysis, feature learning, and anomaly detection.
- Reinforcement Learning is suitable for scenarios where an agent needs to learn a strategy over time by interacting with an environment. This approach is particularly useful in complex decision-making tasks like robotics, game playing, and autonomous systems.
Conclusion
Supervised Learning, Unsupervised Learning, and Reinforcement Learning represent the three pillars of Machine Learning, each offering unique methods to solve different types of problems. Understanding the differences between these approaches is crucial for selecting the right method for your specific task. Whether you’re dealing with labeled data, seeking to uncover hidden patterns, or trying to optimize decision-making processes, there’s a Machine Learning approach tailored to meet your needs. As you continue to explore and apply these techniques, you’ll find that each has its strengths, challenges, and ideal applications, contributing to the ever-growing field of Artificial Intelligence.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
