Machine learning models are the backbone of any machine learning system. They are the mathematical representations that learn patterns from data and make predictions or decisions based on that learning. Whether you’re predicting house prices, classifying emails as spam, or clustering customers into segments, the model you choose plays a critical role in the success of your machine learning project.
In this tutorial blog, we will explore what machine learning models are, the different types of models, and how to build, evaluate, and deploy them effectively.
Introduction to Machine Learning Models
What is a Machine Learning Model?
A machine learning model is a function that maps input data (features) to output predictions or decisions. This function is learned from historical data during a process called training. Once trained, the model can be used to make predictions on new, unseen data.
Why Are Machine Learning Models Important?
Machine learning models automate decision-making processes, making it possible to analyze large volumes of data, identify patterns, and make predictions without human intervention. They are used across various industries, from finance and healthcare to marketing and autonomous systems.
Core Concepts in Machine Learning Models
1. Training and Test Data
- Training Data: The dataset used to train the model. It includes input data and the corresponding output labels (in supervised learning).
- Test Data: A separate dataset used to evaluate the model’s performance after it has been trained.
2. Features and Labels
- Features: The input variables used by the model to make predictions. They can be numeric, categorical, or a mix of both.
- Labels: The output variable that the model is trying to predict. In classification tasks, labels are categories, while in regression tasks, labels are continuous values.
3. Model Parameters and Hyperparameters
- Model Parameters: Values that the model learns from the training data, such as the weights in a linear regression model.
- Hyperparameters: Settings that are configured before training begins, such as the learning rate or the number of layers in a neural network.
4. Overfitting and Underfitting
- Overfitting: When a model learns the training data too well, including noise, leading to poor generalization to new data.
- Underfitting: When a model is too simple to capture the underlying patterns in the data, resulting in poor performance on both the training and test data.
Here’s a tabular representation of the types of machine learning models along with their descriptions, common applications, and key characteristics:
| Type of Model | Model Name | Description | Common Applications | Key Characteristics |
|---|---|---|---|---|
| Regression Models | Linear Regression | Models the relationship between a dependent variable and one or more independent variables using a linear equation. | Predicting house prices, sales forecasting. | Assumes a linear relationship between variables. |
| Polynomial Regression | Extends linear regression by modeling the relationship as an nth-degree polynomial. | Growth trends, complex forecasting. | Captures nonlinear relationships. | |
| Ridge Regression | A linear regression model with L2 regularization to prevent overfitting. | Financial modeling, scenarios with many features. | Penalizes large coefficients to prevent overfitting. | |
| Lasso Regression | A linear regression model with L1 regularization for feature selection. | Feature selection, interpretative models. | Can reduce some coefficients to zero, effectively selecting features. | |
| Support Vector Regression (SVR) | Extends SVM to regression tasks, predicting continuous values while minimizing errors within a margin. | Predicting stock prices, real estate valuation. | Handles high-dimensional data well, robust to outliers. | |
| Classification Models | Logistic Regression | A linear model for binary classification, predicting the probability of a categorical outcome. | Spam detection, medical diagnosis. | Outputs probabilities, useful for binary outcomes. |
| Decision Trees | A tree-like model that splits the data into subsets based on feature values, leading to a decision or classification. | Customer segmentation, fraud detection. | Simple, interpretable, prone to overfitting without pruning. | |
| Random Forest | An ensemble of decision trees that improves accuracy by averaging their predictions. | Complex classification tasks, fraud detection. | Reduces overfitting, handles large datasets well, robust to noise. | |
| Support Vector Machines (SVM) | Finds the optimal hyperplane that separates classes in the feature space. | Image classification, bioinformatics. | Effective in high-dimensional spaces, works well with clear margin separation. | |
| k-Nearest Neighbors (k-NN) | Classifies data points based on the majority vote of their k-nearest neighbors in the feature space. | Recommender systems, pattern recognition. | Simple, no assumptions about data distribution, computationally intensive for large datasets. | |
| Naive Bayes | A probabilistic classifier based on Bayes’ theorem, assuming feature independence. | Text classification, spam filtering. | Fast, works well with small datasets, assumes independence of features. | |
| Neural Networks | Models inspired by the human brain, consisting of layers of neurons capable of learning complex patterns. | Image recognition, speech recognition, NLP. | Handles complex, non-linear patterns, requires large datasets and computational power. | |
| Clustering Models | k-Means Clustering | Partitions data into k clusters by minimizing within-cluster variance. | Market segmentation, document clustering. | Requires pre-specification of k, sensitive to initial cluster centers. |
| Hierarchical Clustering | Builds a hierarchy of clusters through either merging or splitting based on similarity. | Social network analysis, gene expression analysis. | Does not require pre-specifying the number of clusters, interpretable. | |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise; groups points that are closely packed while marking outliers in low-density regions. | Geospatial data analysis, anomaly detection. | Handles noise and outliers well, does not require pre-specification of clusters. | |
| Gaussian Mixture Models (GMM) | Models data as a mixture of multiple Gaussian distributions, used for probabilistic clustering. | Density estimation, clustering tasks with complex datasets. | Captures complex cluster shapes, probabilistic rather than deterministic. | |
| Latent Dirichlet Allocation (LDA) | A generative model for discovering hidden topics in large collections of text. | Topic modeling, document classification. | Identifies underlying themes in text data, useful for unsupervised learning tasks. |
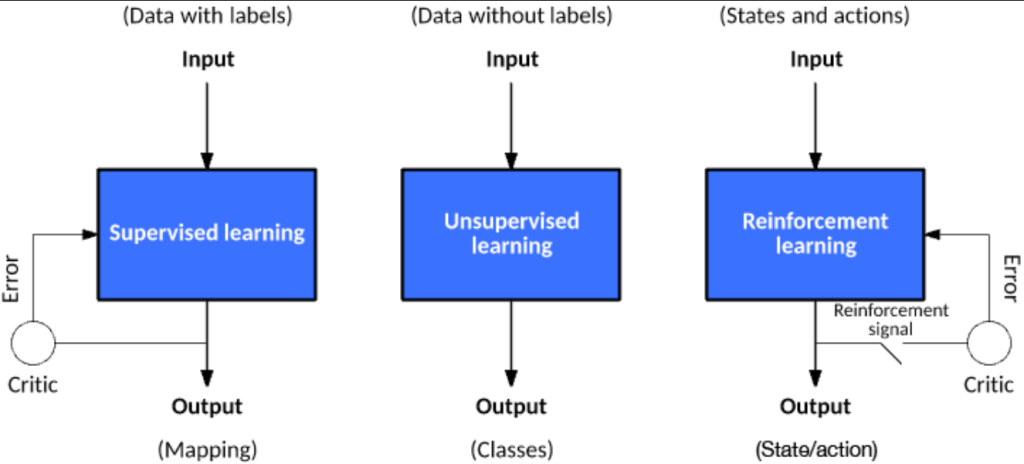
Types of Machine Learning Models
Machine learning models can be categorized into three main types: Regression Models, Classification Models, and Clustering Models. Let’s explore each type in detail.
1. Regression Models
Regression Models are used for predicting continuous outcomes based on input data. They are fundamental in tasks that involve forecasting, trend analysis, and estimating relationships between variables.
- Linear Regression
- Description: Models the relationship between the dependent variable and one or more independent variables using a straight line.
- Applications: Predicting house prices, sales forecasting.
- Polynomial Regression
- Description: Extends linear regression by modeling the relationship as an nth-degree polynomial.
- Applications: Modeling nonlinear trends, such as growth over time.
- Ridge and Lasso Regression
- Description: These models add regularization terms (L2 for Ridge, L1 for Lasso) to prevent overfitting by penalizing large coefficients.
- Applications: Financial modeling, high-dimensional data.
- Support Vector Regression (SVR)
- Description: An extension of SVMs to regression tasks, predicting continuous values while minimizing errors within a margin.
- Applications: Predicting continuous outcomes like prices and weather.
2. Classification Models
Classification Models predict categorical outcomes, such as whether an email is spam or not, or whether a patient has a certain disease.
- Logistic Regression
- Description: A linear model used for binary classification, predicting the probability that a given instance belongs to a particular class.
- Applications: Spam detection, medical diagnosis.
- Decision Trees
- Description: A tree-like model that splits the data into subsets based on feature values, leading to decisions.
- Applications: Customer segmentation, credit scoring.
- Random Forest
- Description: An ensemble of decision trees that improves accuracy by averaging their predictions.
- Applications: Fraud detection, complex classification tasks.
- Support Vector Machines (SVM)
- Description: Finds the optimal hyperplane that separates classes in the feature space.
- Applications: Image classification, bioinformatics.
- k-Nearest Neighbors (k-NN)
- Description: Classifies data points based on the majority vote of their k-nearest neighbors.
- Applications: Recommender systems, pattern recognition.
- Naive Bayes
- Description: A probabilistic classifier based on Bayes’ theorem with an assumption of feature independence.
- Applications: Text classification, spam filtering.
- Neural Networks
- Description: Models inspired by the human brain, consisting of layers of neurons. Capable of learning complex patterns.
- Applications: Image and speech recognition, NLP.
3. Clustering Models
Clustering Models group similar data points into clusters, helping to uncover the underlying structure in the data.
- k-Means Clustering
- Description: Partitions data into k clusters by minimizing within-cluster variance.
- Applications: Market segmentation, document clustering.
- Hierarchical Clustering
- Description: Builds a hierarchy of clusters through either merging or splitting operations.
- Applications: Social network analysis, bioinformatics.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Description: Groups closely packed points while marking outliers in low-density regions.
- Applications: Geospatial data analysis, anomaly detection.
- Gaussian Mixture Models (GMM)
- Description: Models data as a mixture of multiple Gaussian distributions, used for clustering by assuming each cluster follows a Gaussian distribution.
- Applications: Density estimation, image segmentation.
- Latent Dirichlet Allocation (LDA)
- Description: A generative model for discovering topics in large collections of text.
- Applications: Topic modeling, document classification.
Building and Evaluating Machine Learning Models
1. Data Collection and Preprocessing
- Data Collection: Gather high-quality, relevant data for the problem you are trying to solve.
- Preprocessing: Clean the data, handle missing values, and normalize or standardize features.
2. Model Selection
- Choosing the Right Model: Select a model based on the problem type and data characteristics.
- Training the Model: Use the training data to fit the model, adjusting its parameters to minimize errors.
3. Model Evaluation
- Validation and Cross-Validation: Evaluate the model on a separate validation set or use cross-validation to assess performance.
- Evaluation Metrics: Use appropriate metrics based on the task:
- Regression: Mean Squared Error (MSE), R-squared.
- Classification: Accuracy, Precision, Recall, F1-score, ROC-AUC.
- Clustering: Silhouette Score, Davies-Bouldin Index.
4. Hyperparameter Tuning
- Grid Search and Random Search: Tune hyperparameters to optimize performance.
- Regularization: Prevent overfitting using techniques like L1 or L2 regularization.
Deploying Machine Learning Models
Model Deployment
- Model Deployment: Deploy models in production environments, ensuring they are scalable and efficient.
- Monitoring: Continuously monitor model performance to detect drift and retrain if necessary.
Case Studies and Real-World Applications
- Case Study 1: Predicting house prices using linear regression.
- Case Study 2: Detecting fraud in credit card transactions using random forests.
- Case Study 3: Segmenting customers for targeted marketing using k-means clustering.
Best Practices for Building Machine Learning Models
- Feature Engineering: Invest time in creating and selecting the right features.
- Model Interpretability: Ensure models are interpretable, especially in critical applications like healthcare.
- Scalability: Design models that can scale to handle large datasets.
- Ethics in Machine Learning: Ensure fairness, transparency, and accountability in model deployment.
Lifecycle of Machine Learning Models
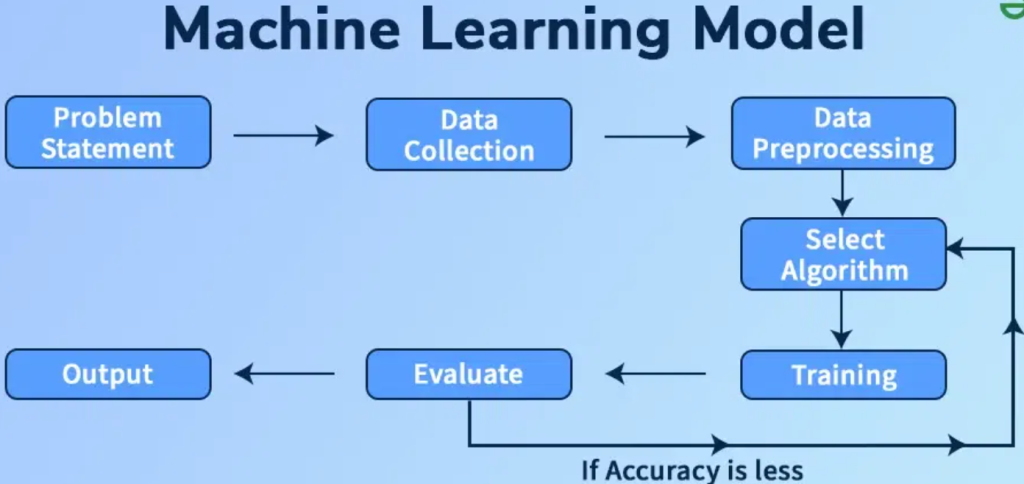
The lifecycle of a machine learning model encompasses the entire process from the initial problem definition to the final deployment and maintenance of the model in a production environment. Each stage in the lifecycle is crucial to building an effective and reliable model that can deliver accurate predictions and add value to the business. Below is an overview of the main stages in the lifecycle of a machine learning model.
| Stage | Description | Key Activities |
|---|---|---|
| 1. Problem Definition | Clearly define the problem you want to solve using machine learning, including specifying the goals, objectives, and success criteria. | – Understand the business problem. – Determine if machine learning is the right approach. – Define the scope and objectives. – Set success metrics. |
| 2. Data Collection | Gather the relevant data that will be used to train the model. This data can come from various sources, including databases, APIs, sensors, and external datasets. | – Identify data sources. – Collect raw data from different sources. – Ensure data quality and completeness. – Store data securely. |
| 3. Data Preparation | Prepare the data for modeling by cleaning, transforming, and organizing it. Data preparation is a critical step to ensure the model receives high-quality input. | – Handle missing values and outliers. – Normalize or standardize data. – Encode categorical variables. – Split data into training, validation, and test sets. |
| 4. Feature Engineering | Create new features or select relevant ones to improve model performance. Feature engineering is often the most creative and time-consuming part of the process. | – Generate new features based on domain knowledge. – Select the most relevant features. – Transform features (e.g., scaling, binning). |
| 5. Model Selection | Choose the appropriate machine learning algorithm or model based on the problem type (e.g., regression, classification) and the nature of the data. | – Evaluate different algorithms. – Consider model complexity and interpretability. – Select the best model type (e.g., linear regression, decision tree). |
| 6. Model Training | Train the model using the training dataset. During this phase, the model learns patterns in the data and optimizes its parameters to minimize errors. | – Initialize model parameters. – Train the model on the training dataset. – Monitor training performance (e.g., loss, accuracy). |
| 7. Model Evaluation | Assess the model’s performance using a separate validation or test dataset to ensure it generalizes well to unseen data. | – Evaluate model performance using metrics (e.g., accuracy, MSE, F1-score). – Perform cross-validation. – Compare models to select the best performer. |
| 8. Hyperparameter Tuning | Optimize the model’s performance by fine-tuning hyperparameters, which are settings that control the learning process. | – Use techniques like grid search or random search. – Adjust hyperparameters (e.g., learning rate, number of trees). |
| 9. Model Deployment | Deploy the trained and validated model to a production environment where it can make predictions on new, real-world data. | – Integrate the model with existing systems. – Deploy the model to a server, cloud, or edge device. – Ensure scalability and performance. |
| 10. Monitoring & Maintenance | Continuously monitor the model’s performance in production and retrain it as necessary to handle changes in data patterns or business needs. | – Monitor model performance over time (e.g., accuracy, latency). – Detect and address model drift. – Retrain the model with new data as needed. |
| 11. Model Retirement | Retire the model when it is no longer effective or relevant, or when a new model replaces it. | – Archive the model and associated data. – Document reasons for retirement. – Plan for a smooth transition to the new model. |
Detailed Explanation of Each Stage
1. Problem Definition
- Objective: Clearly articulate the problem that the model is expected to solve. This includes understanding the business context, the specific questions the model will answer, and how success will be measured.
- Outcome: A well-defined problem statement with measurable goals.
2. Data Collection
- Objective: Collect data from various sources that are relevant to the problem. This could include historical records, real-time data feeds, or external datasets.
- Outcome: A comprehensive dataset that can be used for training and testing the model.
3. Data Preparation
- Objective: Clean and preprocess the data to make it suitable for modeling. This involves handling missing values, dealing with outliers, normalizing or standardizing the data, and splitting it into training, validation, and test sets.
- Outcome: A clean and well-prepared dataset that is ready for feature engineering and modeling.
4. Feature Engineering
- Objective: Enhance the dataset by creating new features or selecting the most relevant ones. Effective feature engineering can significantly improve model performance.
- Outcome: A set of features that best represent the underlying patterns in the data.
5. Model Selection
- Objective: Choose the most appropriate algorithm or model type based on the problem at hand and the characteristics of the data.
- Outcome: A selected model ready to be trained on the dataset.
6. Model Training
- Objective: Train the model using the training dataset. The model adjusts its parameters during this phase to learn from the data.
- Outcome: A trained model that can make predictions based on input data.
7. Model Evaluation
- Objective: Evaluate the model’s performance on a separate validation or test dataset to ensure it generalizes well to new data.
- Outcome: An assessment of the model’s accuracy, precision, recall, or other relevant metrics.
8. Hyperparameter Tuning
- Objective: Optimize the model’s performance by adjusting hyperparameters, which are external to the model and control the training process.
- Outcome: A fine-tuned model with optimized hyperparameters.
9. Model Deployment
- Objective: Deploy the model to a production environment where it can be used to make real-time predictions or batch predictions.
- Outcome: A deployed model that is integrated with the business process or application.
10. Monitoring & Maintenance
- Objective: Continuously monitor the model’s performance and maintain it to ensure it remains accurate and relevant as the underlying data or business environment changes.
- Outcome: A model that continues to perform well in production, with processes in place for updating or retraining as needed.
11. Model Retirement
- Objective: Retire the model when it is no longer useful or has been replaced by a newer model. This stage includes archiving the model and ensuring a smooth transition.
- Outcome: A retired model with all relevant documentation and data archived for future reference.
Workflow of Machine Learning Models
The workflow of machine learning models involves a systematic process that takes a problem from conceptualization to deployment and monitoring in production. This workflow ensures that models are built efficiently, perform well, and provide actionable insights. Below is a detailed overview of the typical workflow involved in developing machine learning models.
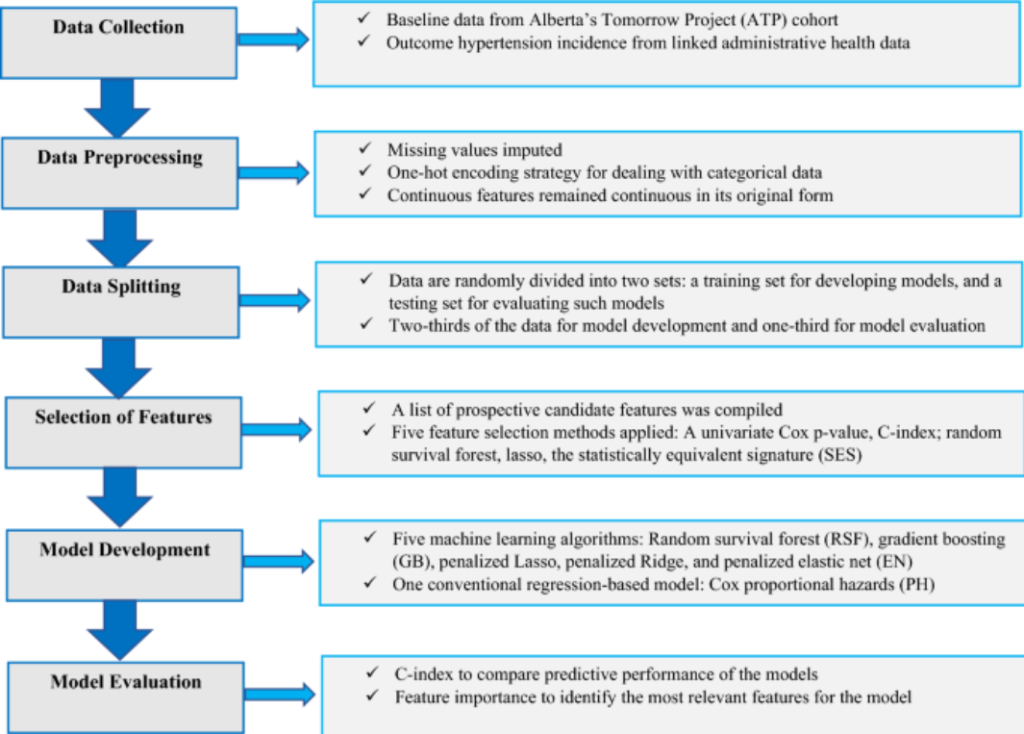
1. Problem Definition
- Objective: Clearly define the problem you aim to solve with machine learning. This includes understanding the business context, specifying the goals, and determining how success will be measured.
- Key Activities:
- Identify the business problem.
- Define the machine learning task (e.g., classification, regression).
- Set objectives and success criteria.
2. Data Collection
- Objective: Gather the necessary data that will be used to train, validate, and test the model. This step is crucial as the quality of data directly impacts model performance.
- Key Activities:
- Identify data sources (databases, APIs, sensors, etc.).
- Collect raw data relevant to the problem.
- Ensure data quality, completeness, and relevance.
3. Data Preprocessing
- Objective: Clean and preprocess the collected data to make it suitable for modeling. Preprocessing helps eliminate noise and inconsistencies in the data.
- Key Activities:
- Handle missing values (imputation, removal).
- Deal with outliers.
- Normalize or standardize data.
- Encode categorical variables.
- Split the data into training, validation, and test sets.
4. Exploratory Data Analysis (EDA)
- Objective: Explore the data to gain insights and identify patterns or relationships. EDA helps in understanding the distribution of data and potential challenges.
- Key Activities:
- Visualize data distributions and relationships using plots and graphs.
- Identify trends, correlations, and anomalies.
- Summarize the main characteristics of the data.
5. Feature Engineering
- Objective: Enhance the dataset by creating new features or selecting the most relevant ones. This step is critical for improving model accuracy and interpretability.
- Key Activities:
- Create new features from existing data (e.g., date to day of the week).
- Transform features (e.g., log transformation, polynomial features).
- Select important features using techniques like correlation analysis or feature importance scores.
6. Model Selection
- Objective: Choose the most appropriate machine learning algorithm or model type based on the problem type and the nature of the data.
- Key Activities:
- Compare different algorithms (e.g., decision trees, SVM, neural networks).
- Consider model complexity, interpretability, and scalability.
- Select a model for initial training.
7. Model Training
- Objective: Train the selected model on the training dataset. The model learns patterns in the data and optimizes its parameters to minimize prediction errors.
- Key Activities:
- Initialize model parameters.
- Train the model using the training data.
- Monitor the training process (e.g., loss curves, accuracy).
8. Model Validation
- Objective: Validate the model’s performance using a separate validation dataset. This step helps in tuning hyperparameters and preventing overfitting.
- Key Activities:
- Evaluate the model using the validation set.
- Perform cross-validation to assess model stability.
- Adjust hyperparameters to optimize performance.
9. Model Evaluation
- Objective: Evaluate the final model on a test dataset to ensure it generalizes well to new, unseen data.
- Key Activities:
- Calculate performance metrics (e.g., accuracy, precision, recall, F1-score, MSE).
- Compare the model’s performance against baseline models.
- Analyze errors and potential areas of improvement.
10. Hyperparameter Tuning
- Objective: Fine-tune the model’s hyperparameters to maximize its performance. This is an iterative process that seeks to optimize the model’s predictive capabilities.
- Key Activities:
- Use grid search or random search to explore hyperparameter combinations.
- Evaluate the performance of each combination.
- Select the best set of hyperparameters.
11. Model Deployment
- Objective: Deploy the trained and validated model to a production environment where it can make predictions on real-time or batch data.
- Key Activities:
- Integrate the model with production systems or applications.
- Deploy the model on servers, cloud platforms, or edge devices.
- Set up APIs or services to facilitate model predictions.
12. Monitoring and Maintenance
- Objective: Continuously monitor the model’s performance in production and maintain it to ensure it remains accurate and effective over time.
- Key Activities:
- Monitor model performance metrics (e.g., accuracy, latency).
- Detect model drift or changes in data distribution.
- Retrain the model periodically with new data.
- Update the model to adapt to changing conditions.
13. Model Re-evaluation and Updating
- Objective: Regularly re-evaluate the model to ensure it still meets the business objectives. Update or replace the model if necessary.
- Key Activities:
- Periodically test the model on new data.
- Compare model performance against newer models or techniques.
- Update the model with new training data and retrain if required.
14. Model Retirement
- Objective: Retire the model when it is no longer effective or relevant, or when a new model replaces it. This stage includes archiving the model and ensuring a smooth transition.
- Key Activities:
- Archive the model and associated data.
- Document the reasons for retirement.
- Transition to a new or updated model.
Final Thoughts
This comprehensive guide provides a detailed roadmap for writing a tutorial blog on machine learning models. By covering the fundamental concepts, different types of models, and best practices, you will create a valuable resource that can help readers of all levels understand the intricacies of machine learning models and how to apply them effectively.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
