Machine Learning (ML) is a broad domain within Artificial Intelligence (AI) that focuses on building systems that learn from data and improve over time. One of the most fascinating and complex branches of Machine Learning is Reinforcement Learning (RL). Unlike other types of learning that rely on predefined datasets or labels, Reinforcement Learning involves an agent learning to make decisions by interacting with its environment to maximize some notion of cumulative reward. This blog will explore the fundamental concepts of Reinforcement Learning, key algorithms, practical applications, and how to implement these techniques.
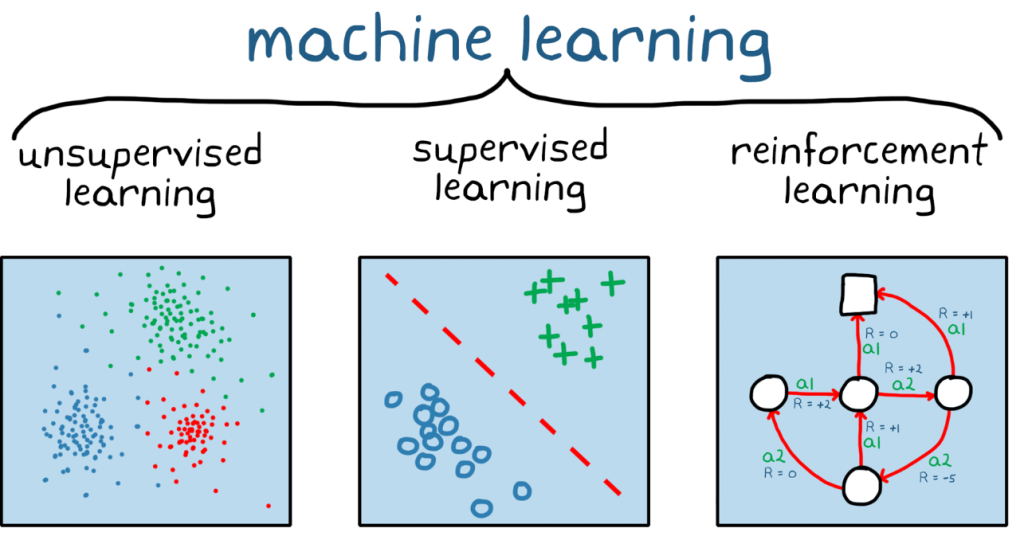
What is Reinforcement Learning?
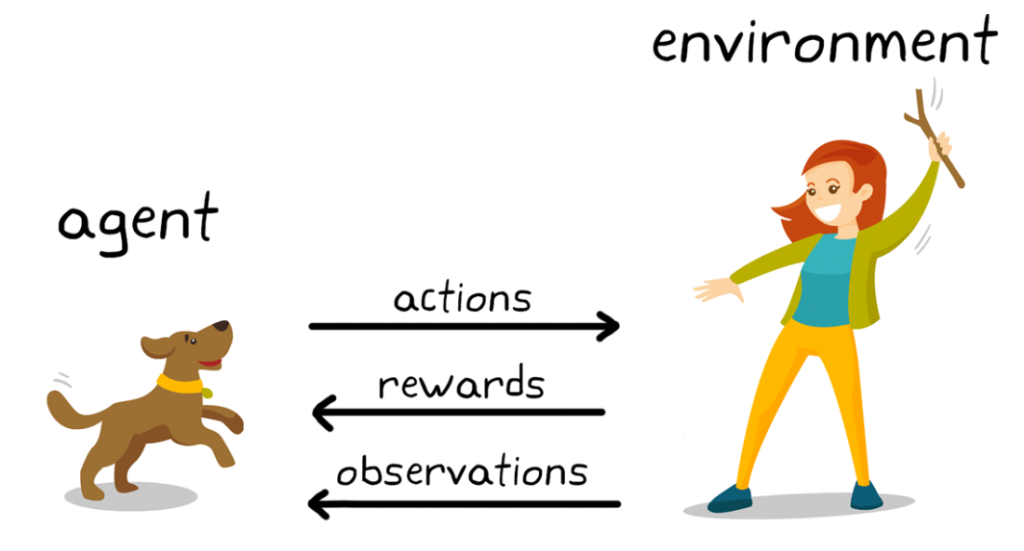
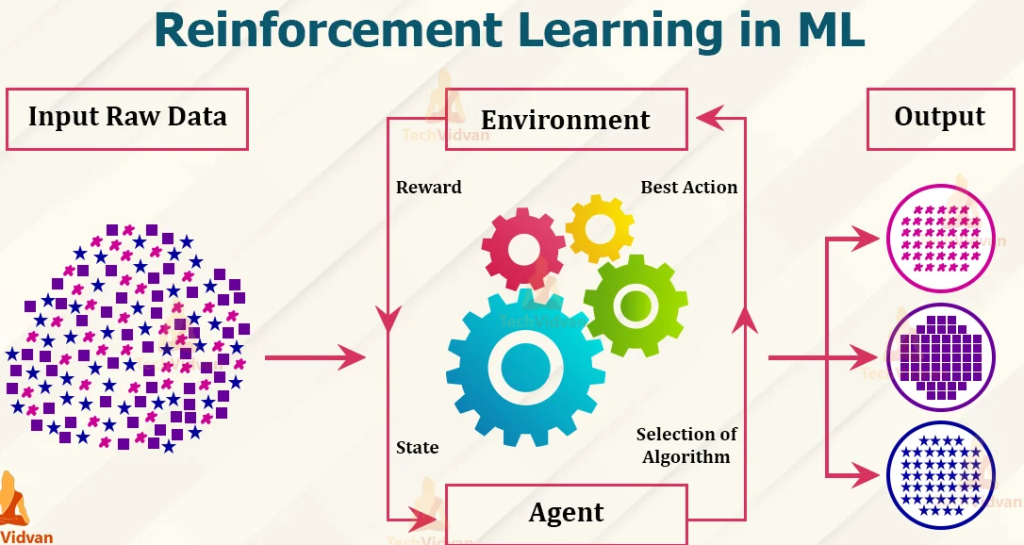
Reinforcement Learning is a type of Machine Learning where an agent learns to make decisions by performing actions in an environment to achieve a goal. The agent receives feedback from the environment in the form of rewards or penalties, which it uses to improve its decision-making strategy over time. The key components of a Reinforcement Learning system are:
- Agent: The learner or decision-maker.
- Environment: Everything the agent interacts with to achieve its goal.
- State: The current situation of the environment as perceived by the agent.
- Action: The decisions or moves the agent can make.
- Reward: The feedback from the environment in response to the agent’s action, indicating the success or failure of the action.
- Policy: The strategy that the agent uses to determine its actions based on the current state.
- Value Function: A function that estimates the expected future rewards that can be obtained from each state.
- Q-Value (Action-Value) Function: A function that estimates the expected future rewards for taking a particular action in a given state.
Key Concepts in Reinforcement Learning
1. Markov Decision Process (MDP)
- MDP is a mathematical framework used to describe the environment in Reinforcement Learning. It includes a set of states, actions, transition probabilities, and rewards. MDP assumes the Markov property, which means that the future state depends only on the current state and action, not on the sequence of events that preceded it.
2. Exploration vs. Exploitation
- Exploration: Refers to the agent trying new actions to discover more about the environment.
- Exploitation: Refers to the agent choosing actions that it knows will yield the highest reward based on its current knowledge.
- Balancing exploration and exploitation is a key challenge in Reinforcement Learning.
3. Reward Signal
- The reward signal is the feedback that the agent receives from the environment after taking an action. The goal of the agent is to maximize the cumulative reward over time, which guides its learning process.
4. Policy
- A policy defines the agent’s behavior by mapping states to actions. There are two types of policies:
- Deterministic Policy: Maps each state to a specific action.
- Stochastic Policy: Maps each state to a probability distribution over actions.
5. Value Function
- The value function estimates the expected cumulative reward for each state, indicating how valuable a state is in terms of future rewards. The value function helps the agent choose actions that lead to states with higher expected rewards.
6. Q-Function (Action-Value Function)
- The Q-function, or action-value function, estimates the expected cumulative reward for taking a specific action in a given state and following the optimal policy thereafter. It is a crucial concept in many RL algorithms.
Common Algorithms in Reinforcement Learning
Reinforcement Learning encompasses various algorithms, each with its strengths and suitable applications. Here are some of the most commonly used algorithms:
1. Q-Learning
- Type: Model-Free, Off-Policy
- Description: Q-Learning is a value-based algorithm that seeks to learn the optimal action-value function (Q-function) by updating Q-values iteratively based on the agent’s experiences. The agent chooses actions based on an epsilon-greedy strategy, where it mostly exploits the best-known action but occasionally explores new actions.
- Use Case: Game playing, where the agent learns the best moves to maximize its score.
2. SARSA (State-Action-Reward-State-Action)
- Type: Model-Free, On-Policy
- Description: SARSA is similar to Q-Learning but is an on-policy algorithm, meaning it updates the Q-values based on the action actually taken by the policy rather than the best possible action. This approach leads to more conservative learning.
- Use Case: Real-time decision-making scenarios where the agent’s policy may change dynamically.
3. Deep Q-Networks (DQNs)
- Type: Model-Free, Off-Policy
- Description: DQNs combine Q-Learning with deep neural networks to handle high-dimensional state spaces, such as raw pixel data in video games. DQNs introduced techniques like experience replay and fixed Q-targets to stabilize training.
- Use Case: Complex video games, where the agent learns to play directly from pixels.
4. Policy Gradient Methods
- Type: Model-Free, On-Policy
- Description: Policy Gradient methods directly optimize the policy by adjusting its parameters in the direction that increases the expected cumulative reward. These methods are particularly useful for environments with continuous action spaces.
- Use Case: Robotics, where the agent must control motors with continuous actions.
5. Actor-Critic Methods
- Type: Model-Free, On-Policy or Off-Policy
- Description: Actor-Critic methods combine the advantages of value-based and policy-based approaches. The “actor” updates the policy directly, while the “critic” evaluates the actions by estimating value functions. This combination allows for more stable and efficient learning.
- Use Case: Autonomous vehicles, where precise and stable control policies are required.
6. Proximal Policy Optimization (PPO)
- Type: Model-Free, On-Policy
- Description: PPO is a policy gradient method that improves training stability by limiting the change in policy update through a clipped objective function. PPO is widely used in many RL applications due to its ease of implementation and reliability.
- Use Case: Simulated environments like OpenAI Gym, where reliable and robust learning is necessary.
7. Deep Deterministic Policy Gradient (DDPG)
- Type: Model-Free, Off-Policy
- Description: DDPG is an actor-critic algorithm specifically designed for environments with continuous action spaces. It uses a deterministic policy with added noise for exploration, making it effective for tasks requiring fine control.
- Use Case: Robotic arm manipulation, where precise control is needed in a continuous action space.
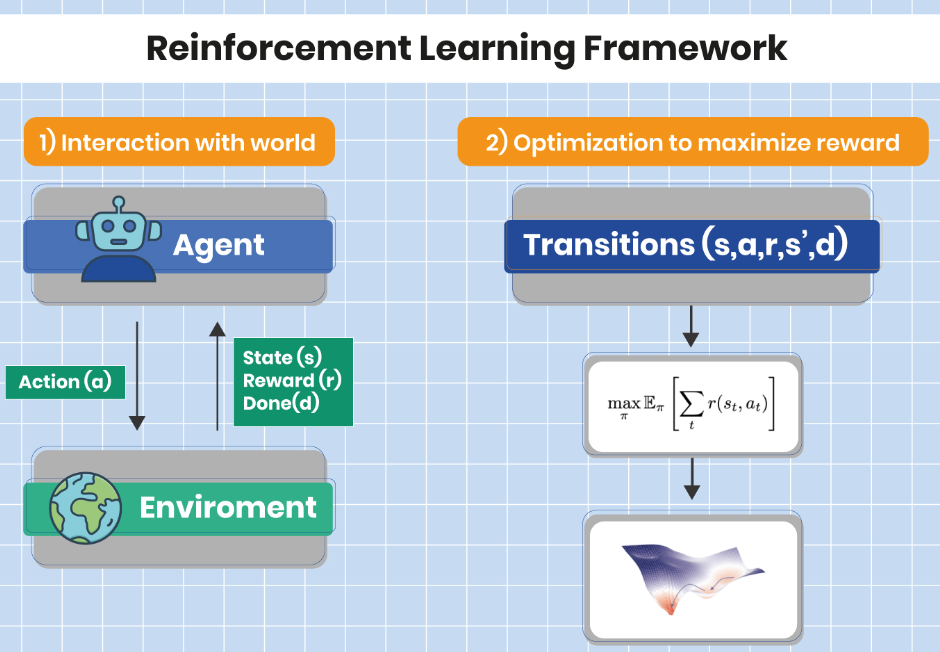
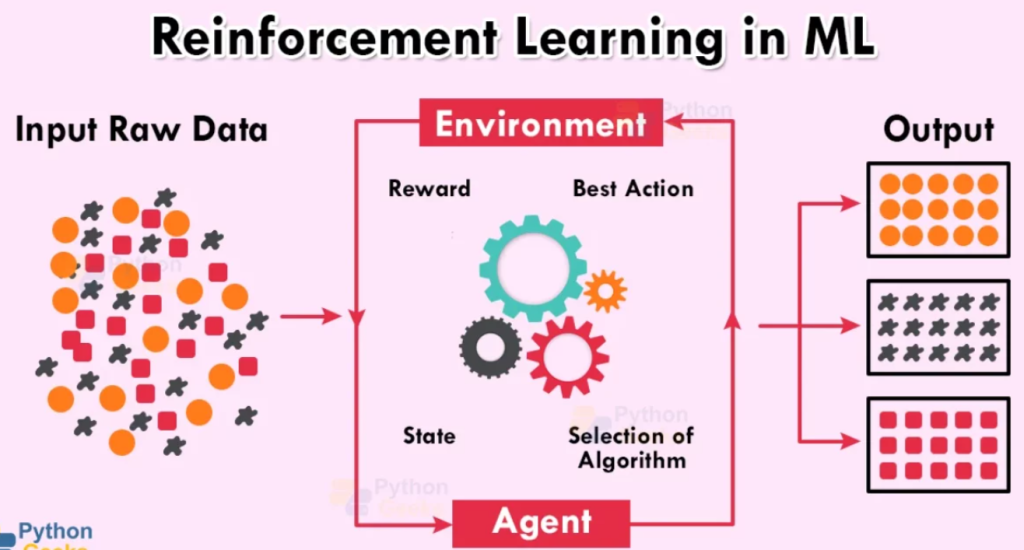
How to Implement Reinforcement Learning: A Step-by-Step Guide
Implementing Reinforcement Learning involves several steps, from defining the environment to training the agent and evaluating its performance. Here’s a basic outline:
1. Define the Environment
- The first step is to define the environment in which the agent will operate. This environment should include the states, actions, transition probabilities, and reward structure.
2. Define the Agent
- Define the agent’s policy, value function, and learning algorithm. The choice of algorithm will depend on the nature of the problem and the environment.
3. Initialize the Agent
- Initialize the agent’s policy and value functions. This often involves setting initial weights for a neural network or initial Q-values for a Q-Learning algorithm.
4. Training the Agent
- The agent interacts with the environment by taking actions, observing the resulting state, and receiving rewards. The agent updates its policy and value function based on these interactions.
- Exploration vs. Exploitation: Ensure that the agent balances exploration (trying new actions) and exploitation (choosing the best-known actions).
5. Evaluate the Agent
- After training, evaluate the agent’s performance by measuring the cumulative reward over several episodes or using specific metrics related to the task.
- Visual Inspection: In some cases, visually inspecting the agent’s behavior (e.g., in a game) can provide valuable insights.
6. Hyperparameter Tuning
- Adjust hyperparameters such as learning rate, discount factor, and exploration rate to optimize the agent’s performance. This step may involve running multiple experiments and comparing results.
7. Deploying the Agent
- Once satisfied with the agent’s performance, deploy it in the real environment or a production setting. Ensure that the agent continues to learn and adapt if the environment changes.
Applications of Reinforcement Learning
Reinforcement Learning has a wide range of applications across various industries:
- Gaming: RL has been used to create agents that play games like chess, Go, and video games at superhuman levels. Notable examples include DeepMind’s AlphaGo and OpenAI’s Dota 2 bot.
- Robotics: RL is used to teach robots to perform tasks such as walking, grasping objects, and navigating environments autonomously.
- Finance: RL is applied to algorithmic trading, portfolio management, and risk assessment, where the agent learns to make optimal financial decisions.
- Healthcare: RL is used for personalized treatment plans, optimizing drug dosages, and automated surgery planning.
- Autonomous Vehicles: RL is critical in developing self-driving cars, where the agent must make real-time decisions based on sensor data.
- Natural Language Processing: RL is used to train conversational agents, optimize text summarization, and improve machine translation.
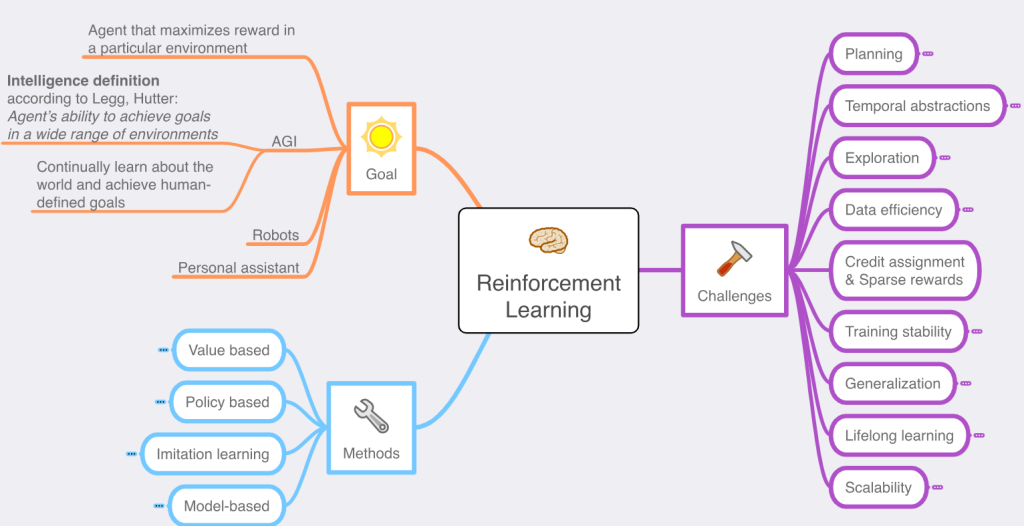
Challenges in Reinforcement Learning
Despite its potential, Reinforcement Learning comes with its own set of challenges:
- Sample Efficiency: RL algorithms often require a large number of interactions with the environment to learn effective policies, which can be time-consuming and computationally expensive.
- Exploration-Exploitation Dilemma: Balancing exploration and exploitation is a core challenge in RL. Too much exploration can lead to slow learning, while too much exploitation can prevent the agent from discovering better strategies.
- Stability and Convergence: Training RL agents, especially deep RL agents, can be unstable and may not always converge to an optimal solution.
- Reward Design: Designing an appropriate reward function is critical to the success of RL. Poorly designed rewards can lead to unintended behaviors.
- Real-World Deployment: Applying RL in real-world scenarios, such as autonomous driving or robotics, poses additional challenges like safety, robustness, and the need for continuous learning.
Conclusion
Reinforcement Learning is a powerful and dynamic field within Machine Learning that has the potential to solve complex, real-world problems where decision-making is key. By understanding the fundamental concepts, key algorithms, and best practices, you can harness the power of Reinforcement Learning to develop intelligent agents that can learn and adapt to their environments. As you explore the field, remember that the quality of your environment model, the choice of algorithms, and careful evaluation are all critical components of successful Reinforcement Learning. With continued learning and practice, you can master the art of Reinforcement Learning and contribute to the rapidly advancing field of Artificial Intelligence.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
