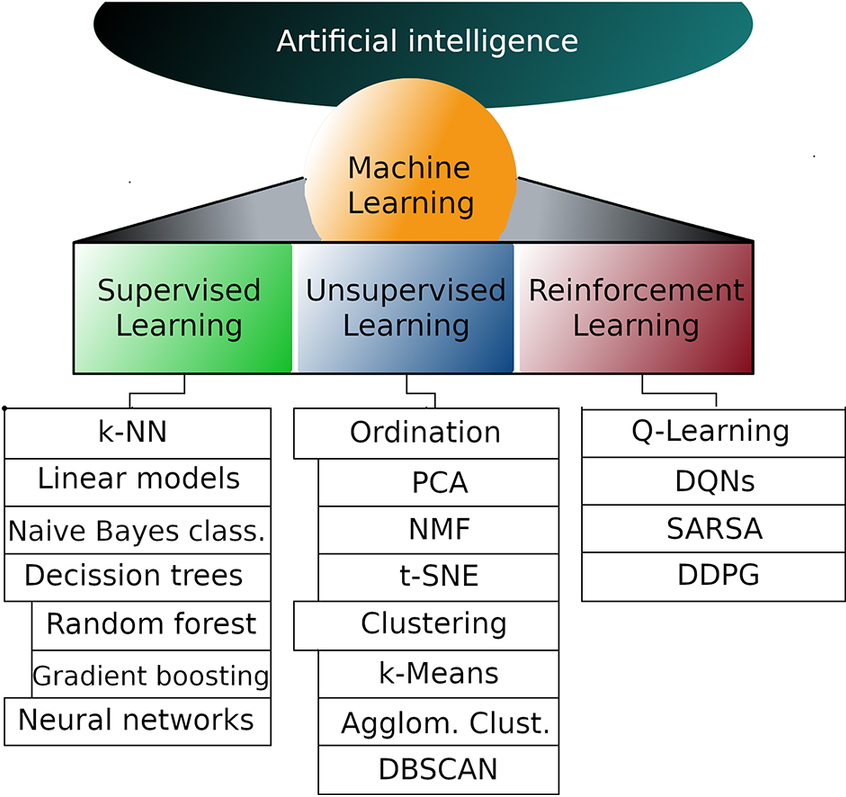
Machine Learning (ML) is a pivotal aspect of Artificial Intelligence (AI), driving innovations in numerous fields from healthcare to finance and beyond. As ML techniques evolve, it becomes crucial to understand the different branches and subbranches that make up this vast and dynamic field. The image above provides a structured overview, categorizing the various aspects of ML into three primary branches: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Each of these branches has its own set of specialized techniques and algorithms, which we’ll explore in detail.
1. Supervised Learning
Supervised Learning is one of the most commonly used branches of Machine Learning, where the model is trained on a labeled dataset. This means that for each input, the corresponding output is already known, allowing the model to learn by comparing its predictions with the actual outcomes. Supervised Learning is particularly effective for tasks where the objective is clear, such as classification and regression problems.
- k-Nearest Neighbors (k-NN): The k-NN algorithm is a simple, non-parametric method used for classification and regression. In k-NN, the output is determined by the majority vote of the k-nearest neighbors in the feature space, making it a powerful tool for simple, small-scale problems.
- Linear Models: Linear models, including linear regression and logistic regression, are foundational in machine learning. These models assume a linear relationship between input features and the target variable, making them highly interpretable and easy to implement.
- Naive Bayes Classifier: The Naive Bayes classifier is a probabilistic model that applies Bayes’ theorem with the assumption that features are independent given the class. Despite its simplicity, it is highly effective for text classification tasks such as spam detection.
- Decision Trees: Decision trees are hierarchical models that make decisions by splitting the data into subsets based on feature values. Each internal node represents a decision based on a feature, and each leaf node represents a class label or a continuous value.
- Random Forest: Random Forest is an ensemble learning method that builds multiple decision trees during training and merges their predictions to improve accuracy and control overfitting. It is particularly robust for both classification and regression tasks.
- Gradient Boosting: Gradient Boosting is another ensemble technique that builds models sequentially, each new model correcting the errors of the previous one. It is widely used in competitive machine learning tasks due to its high performance.
- Neural Networks: Neural Networks are inspired by the structure of the human brain and are used to model complex patterns in data. They consist of interconnected layers of nodes (neurons) that transform the input data to predict the output. Neural networks are the foundation of deep learning and are widely used in applications such as image and speech recognition.
2. Unsupervised Learning
Unsupervised Learning is used when the data is not labeled, meaning that the algorithm must find patterns, groupings, or structures in the data on its own. This branch is essential for discovering hidden structures within data, making it particularly useful for clustering, dimensionality reduction, and anomaly detection.
- Ordination Techniques: Ordination techniques are used for reducing the dimensionality of data, simplifying complex datasets while retaining their essential patterns.
- Principal Component Analysis (PCA): PCA is a widely used technique that reduces the dimensionality of large datasets by transforming the data into a set of orthogonal (uncorrelated) variables called principal components. It is useful for visualizing high-dimensional data and for reducing computational costs in machine learning models.
- Non-negative Matrix Factorization (NMF): NMF is a dimensionality reduction technique where the data is factorized into matrices with non-negative elements, often used in text mining and image processing.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): t-SNE is a powerful technique for visualizing high-dimensional data by reducing it to two or three dimensions while preserving the local structure of the data. It is particularly effective for visualizing clusters in complex datasets.
- Clustering Algorithms: Clustering algorithms group data points into clusters based on their similarity, without any predefined labels. This is crucial in exploratory data analysis and for tasks like market segmentation and anomaly detection.
- k-Means: k-Means is one of the most popular clustering algorithms, which partitions the data into k distinct clusters by minimizing the variance within each cluster.
- Agglomerative Clustering: This is a hierarchical clustering technique that builds nested clusters by merging or splitting them successively, which can be visualized in a dendrogram.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): DBSCAN is a clustering method that groups together points that are closely packed and marks points in low-density areas as outliers. It is particularly useful for data with noise and varying cluster sizes.
3. Reinforcement Learning
Reinforcement Learning (RL) is a branch where an agent learns to make decisions by interacting with an environment to maximize cumulative rewards. Unlike supervised learning, RL does not rely on labeled input/output pairs but instead learns through the consequences of actions, making it ideal for sequential decision-making tasks.
- Q-Learning: Q-Learning is a model-free reinforcement learning algorithm that seeks to find the best action to take given the current state. It learns a value function that estimates the expected future rewards for taking an action in a given state.
- Deep Q-Networks (DQNs): DQNs combine Q-Learning with deep neural networks to handle environments with high-dimensional input spaces, such as those encountered in video games. This technique has been pivotal in the success of RL in complex environments.
- SARSA (State-Action-Reward-State-Action): SARSA is a variation of Q-Learning where the action used to update the value function is the actual action taken by the agent, rather than the optimal action, leading to a more conservative learning strategy.
- Deep Deterministic Policy Gradient (DDPG): DDPG is a model-free, off-policy algorithm used for environments with continuous action spaces. It combines the benefits of both policy gradient methods and Q-learning, making it effective for complex tasks like robotic control.
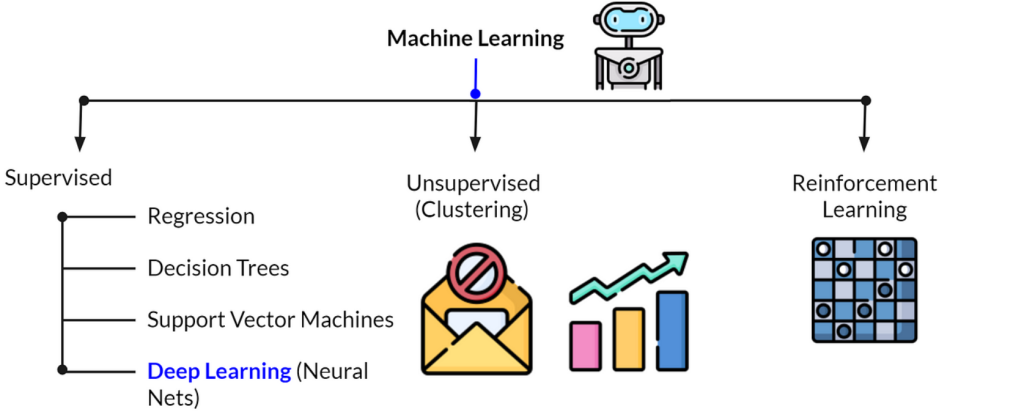
Machine Learning (ML) is a foundational component of Artificial Intelligence (AI), offering a range of methodologies to enable machines to learn from data, identify patterns, and make decisions with minimal human intervention. The image you’ve provided presents a streamlined view of the primary branches of Machine Learning: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Each branch encompasses a variety of techniques and algorithms tailored to specific types of tasks and data. Let’s delve into these branches to understand their significance and applications.
1. Supervised Learning
Supervised Learning is the most common and widely used branch of Machine Learning. It involves training a model on a labeled dataset, where each input data point is paired with a corresponding output. The model learns to map inputs to outputs, enabling it to predict outcomes for new, unseen data.
- Regression: Regression techniques are used when the output variable is continuous and we aim to predict numerical values. For instance, predicting house prices based on features like square footage and location is a regression problem. Linear regression is one of the simplest and most interpretable models used in regression tasks.
- Decision Trees: Decision Trees are versatile models that split the data into subsets based on feature values. The process continues recursively, resulting in a tree-like model where each branch represents a decision rule, and each leaf represents an outcome. Decision Trees are intuitive and can handle both classification and regression tasks.
- Support Vector Machines (SVM): SVM is a powerful classification algorithm that finds the hyperplane which best separates the classes in the feature space. SVM is particularly effective in high-dimensional spaces and when the number of dimensions exceeds the number of samples. It is widely used for tasks like text classification and image recognition.
- Deep Learning (Neural Networks): Deep Learning, a subset of machine learning, leverages neural networks with many layers to model complex patterns in large datasets. Neural networks are particularly effective for tasks like image recognition, natural language processing, and game playing, where the data is vast and the patterns are intricate. Deep learning has revolutionized many fields by achieving human-like performance in tasks that were previously thought to be beyond the capabilities of machines.
2. Unsupervised Learning
Unsupervised Learning is employed when the data is unlabeled, meaning that the algorithm must identify patterns and structures without any guidance. This branch is particularly useful for exploratory data analysis, discovering hidden structures, and identifying relationships in data.
- Clustering: Clustering is a common unsupervised learning technique that groups similar data points together. Unlike supervised learning, there is no predefined output, so the algorithm must infer the natural groupings in the data. Techniques like k-Means, hierarchical clustering, and DBSCAN are popular methods for clustering tasks. Clustering is used in various applications such as customer segmentation, anomaly detection, and organizing large datasets.
Unsupervised learning is crucial in scenarios where labeling data is impractical or impossible, making it a key tool for data exploration and dimensionality reduction.
3. Reinforcement Learning
Reinforcement Learning (RL) is a distinct branch of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties based on the actions it takes, and its goal is to learn a strategy that maximizes the cumulative reward.
In reinforcement learning, the agent’s learning process is akin to trial and error, where it explores various actions and their consequences to gradually improve its performance. This approach is particularly effective for tasks that require sequential decision-making, such as game playing, robotic control, and autonomous driving.
- Reinforcement Learning in Practice: Reinforcement Learning has been successfully applied in a variety of domains, most notably in gaming, where algorithms like Deep Q-Networks (DQN) and AlphaGo have demonstrated superhuman performance in complex games like Go and chess. Beyond gaming, RL is also used in robotics, where robots learn to perform tasks like walking, grasping objects, or navigating environments through trial and error.
Conclusion
The field of Machine Learning is vast and ever-evolving, with each branch and subbranch offering unique methods and approaches to solving different types of problems. The image provided serves as a roadmap, guiding you through the intricate web of techniques that define the landscape of Machine Learning. Understanding these branches and their subbranches is essential for anyone looking to delve into AI and Machine Learning, whether you are a researcher, practitioner, or enthusiast. As ML continues to grow, so too will the complexity and capability of the algorithms within each of these categories, driving innovation across countless domains.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
