
About Logstash:

Logstash is a lightweight, open-source, server-side data processing pipeline that allows you to collect data from a variety of sources, transform it on the fly, and send it to your desired destination. It is most often used as a data pipeline for Elasticsearch, an open-source analytics and search engine.
Moving to the question answers
1. What Is File Beat?

Answer: The File beat consumer is a lightweight, useful resource-friendly device that collects logs from documents on the server and forwards those logs on your Logstash example for processing. File beat is designed for reliability and low latency. File beat has a light aid footprint at the host machine, and the Beats enter plugin minimizes the aid demands on the Logstash instance. Testing Tools Tutorial
2. What Is Grok Filter Plugin?
Answer: The grok filter plugin allows you to parse the unstructured log statistics into something based and question in a position.Because the grok filter plugin appears for patterns within the incoming log facts, configuring the plugin calls for you to make choices approximately how to discover the patterns that are of hobby on your use case.Hibernate Interview Questions
3. What Is GeoIP Plugin?
Answer: GeoIP plugin appears up IP addresses, derives geographic area records from the addresses, and adds that region statistics to the logs.HTML Interview Questions
4. How Do You Read Data From A Twitter Feed?
Answer: To upload a Twitter feed, you use the Twitter input plugin. To configure the plugin, you want numerous pieces of information: A patron key, which uniquely identifies your Twitter app.
A consumer secret, which serves as the password on your Twitter app.
One or extra keywords to search in the incoming feed. The example suggests the usage of “cloud” as a keyword, but you may use anything you want.
An OAuth token, which identifies the Twitter account using this app.
An OAuth token mystery, which serves because of the password of the Twitter account.
Ruby on Rails Tutorial
5. Can You Explain How Logstash Works?
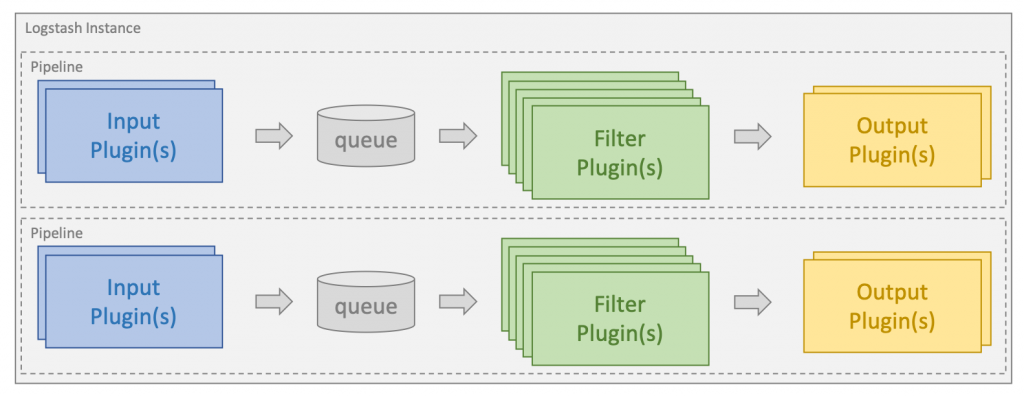
Answer :The Logstash event processing pipeline has three levels:inputs -> filters -> outputs.Inputs generate events, filters regulate them, and outputs deliver them in some other place. Inputs and outputs aid codecs that permit you to encode or decode the statistics as it enters or exits the pipeline without having to apply a separate clear out.
6. What Are Inputs In Logstash?
Answer: You use inputs to get records into Logstash.Some of the greater normally-used inputs are: File
Syslog
Redis
Beats
File: reads from a report on the filesystem, much like the UNIX command tail -0FSyslog: listens at the famous port 514 for Syslog messages and parses in keeping with the RFC3164 layout edits: reads from a Redis server, the use of each Redis channel and Redis lists. Redis is often used as a “dealer” in a centralized Logstash installation, which queues Logstash activities from faraway Logstash “shippers”.Beats: approaches activities sent by File beat.Ruby Interview Questions
7. What Is Logstash? Explain?
Answer: Logstash is an open supply records series engine with real-time pipelining talents. Logstash can dynamically unify facts from disparate sources and normalize the information into locations of your desire. Cleanse and democratize all your data for numerous advanced downstream analytics and visualization use cases.
8. What Is Logstash Used For?
Answer: Logstash is an open-source tool for amassing, parsing, and storing logs for future use. Kibana three is a web interface that can be used to search and view the logs that Logstash has listed. Both of these gear are primarily based on Elastic seek.HTML Interview Questions
9. What Does Logstash Forwarder Do?
Answer: File beat is based totally on the Logstash Forwarder supply code and replaces Logstash Forwarder as the method to apply for tailing log files and forwarding them to Logstash. The registry report, which shops the nation of the present study files, changed into modified.
10. What Is Elk Stack (elastic Stack)?
Answer: Elastic seek, Logstash, and Kibana, while used collectively is called an ELK stack.HTML Tutorial
11. What Is The Power Of Logstash?
Answer: The ingestion workhorse for Elastic search and greater – Horizontally scalable statistics processing pipeline with sturdy Elastic seek and Kibana synergy.
Pluggable pipeline structure – Mix, suit, and orchestrate special inputs, filters, and outputs to play in pipeline concord.
Community-extensible and developer-pleasant plugin surroundings – Over two hundred plugins to be had, plus the flexibility of creating and contributing your very own.
HTML 5 Interview Questions
12. How Many Types Of Logstash Configuration Files Are There?
Answer: Logstash has styles of configuration documents: pipeline configuration documents, which outline the Logstash processing pipeline, and settings files, which specify options that manage Logstash startup and execution.
13. What is the Power of Logstash?
Answer: The ingestion workhorse for Elasticsearch and more – Horizontally scalable data processing pipeline with strong Elasticsearch and Kibana synergy
Pluggable pipeline architecture – Mix, match, and orchestrate different inputs, filters, and outputs to play in pipeline harmony
Community-extensible and developer-friendly plugin ecosystem – Over 200 plugins available, plus the flexibility of creating and contributing your own
14. What are Logs and Metrics in Logstash?
Answer: Logs and Metrics – Logstash handles all types of logging data.
Easily ingest a multitude of weblogs like Apache and application logs like log4j for Java
Capture many other log formats like Syslog, networking and firewall logs, and more
Enjoy complimentary secure log forwarding capabilities with Filebeat
Collect metrics from Ganglia, collected, NetFlow, JMX, and many other infrastructure and application platforms over TCP and UDP
15. How does Logstash work with the web?
Answer: Transform HTTP requests into events
- Consume from web service firehoses like Twitter for social sentiment analysis
- Webhook support for GitHub, HipChat, JIRA, and countless other applications
- Enables many Watcher alerting use cases
- Create events by polling HTTP endpoints on demand
Universally capture health, performance, metrics, and other types of data from web application interfaces - Perfect for scenarios where the control of polling is preferred over receiving
16. Which Java version is required to install Logstash?
Answer: Logstash requires Java 8. Java 9 is not supported.\
17. What are the two required elements in the Logstash pipeline?
Answer: A Logstash pipeline has two required elements, input and output, and one optional element, filter. The input plugins consume data from a source, the filter plugins modify the data as you specify, and the output plugins write the data to a destination.
18. Can you explain how Logstash Works?
Answer: The Logstash event processing pipeline has three stages: inputs -> filters -> outputs. Inputs generate events, filters modify them and outputs ship them elsewhere. Inputs and outputs support codecs that enable you to encode or decode the data as it enters or exits the pipeline without having to use a separate filter.
19. What are Codecs in Logstash?
Answer: Codecs have basically streamed filters that can operate as part of an input or output. Codecs enable you to easily separate the transport of your messages from the serialization process. Popular codecs include json, msgpack, and plain (text).
json: encode or decode data in the JSON format.
multiline: merge multiple-line text events such as java exception and stacktrace messages into a single event.
20. How do you read data from a Twitter Feed?
Answer: To add a Twitter feed, you use the Twitter input plugin. To configure the plugin, you need several pieces of information:
A consumer key, which uniquely identifies your Twitter app.
A consumer secret, which serves as the password for your Twitter app.
One or more keywords to search in the incoming feed. The example shows using “cloud” as a keyword, but you can use whatever you want.
An oauth token, which identifies the Twitter account using this app.
An oauth token secret, which serves as the password of the Twitter account.
21. Give a brief explanation about Kibana?
Answer: Kibana is the platform designed for the visualization and exploration of the data from ElasticSearch. It is an open-source product that helps perform the data analysis in an advanced manner along with data visualization in the form of tables, charts, maps, etc. Kibana also helps in creating dynamic dashboards and sharing them as well. In simpler times, Kibana is the data visualization tool, a simple web-based interface used to perform the operations on the data using RESTful APIs.
22. What is Elastic APM?
Answer: Application Performance Monitoring (APM) is built on top of the Elastic Stack to monitor the application performance. APM is useful for the real-time monitoring of application and software services. It is quite simple to configure, as we only need to set up the APM agent for the application that we are using. As of now, the Elastic Stack supports APM agents for Java, .NET, Python’s Django and Flask frameworks, RUM-JS, Node.js, Go, Ruby on Rails, Rack, and more. Once we configure the APM agent, it will start collecting various application-related information, such as HTTP requests, the response time for various requests, and database queries, and send this information to the APM Server. It also collects unhandled exceptions and errors; this is quite important information and using this, we can stabilize the application further.
23. What is a cluster in Elasticsearch?
Answer: A cluster is a collection of one or more nodes (servers) that together holds your entire data and provide federated indexing and search capabilities across all nodes. A cluster is identified by a unique name which by default is “elasticsearch”.
24. What is a node in Elasticsearch?
Answer: A node is a single server that is part of your cluster, stores your data, and participates in the cluster’s indexing and search capabilities. Just like a cluster, a node is identified by a name which by default is a random Universally Unique IDentifier (UUID) that is assigned to the node at startup. In a single cluster, you can have as many nodes as you want.
25. What is Elasticsearch REST API?
Answer: Elasticsearch provides extensive REST APIs to integrate, query, and manage the data. We can do many things using Elasticsearch REST APIs like:
- Check our cluster, node, and index health, status, statistics, etc.
- Administer our cluster, node, and index data and metadata.
- Perform CRUD (Create, Read, Update, and Delete) and search operations against our indexes.
Execute advanced search operations such as paging, sorting, filtering, scripting, aggregations, etc.
26. How can we create an index in Elasticsearch?
Answer:

Answer: To delete the index, we can execute the following command:
DELETE /blogs?pretty
28. Does Elasticsearch support the schema?
Answer: By nature Elasticseach is schema-less and we can create any document without explicitly creating the schema. But Elasticsearch supports the schema definition and it is good to create the schema before indexing the documents. Elasticsearch automatically guesses the data type for the indexed document but the guess can always not be right so it is good to define the schema.
29. How can we search for any data in Elasticsearch?
Answer: We have basically two types of search APIs in Elasticsearch: ‘request URI based’ and ‘request body based. In REST request URI we use to pass the search criteria in the URL itself like:
GET /blogs/technical/_search?q=topic:kibana
In the REST request body, we use to construct the search block and write the search query inside the query block of Elasticsearch like:
GET /blogs/technical/_search
{
“query”: {
“term”: {
“topic”:”kibana”
}
}
}
So the URI-based search is quite a basic search where we just want to search a keyword whereas in the request body we can construct the complex queries. So we have the query language to work with request body-based searches.
30. What is Metrics Aggregation?
Answer: Metrics aggregation is those aggregations where we apply different types of metrics on fields of Elasticsearch documents like min, max, avg, top, and stats, etc.
31. What is Bucket Aggregation?
Answer: Bucket aggregation is like a group by the result of the RDBMS query where we group the result with a certain field. In the case of Elasticsearch, we use bucket data on the basis of certain criteria. In metrics aggregations, we can calculate metrics on a field while in the bucket we don’t perform calculations but just create buckets with the documents which can be clubbed on the basis of certain criteria. In bucket aggregations, we can create sub aggregations.
32. What are the advantages of using Logstash?
Answer: The key features that users of Logstash find beneficial include:
- Over 200 plugins are available
- Process unstructured data
- Pre-built and custom filters
- Built custom data processing pipelines
- Works as an extract, transform & load (ETL) tool
33. What is AWS Elasticsearch?
Answer: AWS Elasticsearch (also known as Open Distro for Elasticsearch) is currently being rebranded to Open Search & Open Dashboards. AWS’s offering of Elasticsearch & Kibana has a number of additional features including trace analytics, scheduled reports, index, document, and field-level security as well as a SQL and PPL query workbench.
34. How do you install Logstash plugins?
Answer: To find individual download and install commands specific to the Logstash plugin you are wishing to install, Once you’ve selected the plugin you wish to use you can add it to your Logstash installation using the following command: bin/logstash-plugin install logstash-input-Github
35. How can you test Logstash performance?
Answer: You can use the node stats API to retrieve runtime statistics from Logstash.
36. What is a Logstash pipeline?
Answer: A Logstash pipeline consists of these elements as listed in the following order: Input (the source of data), filter (processing, parsing & enrichment of data) & output (write the data for use within Elasticsearch & Kibana).
37. How do you start Kibana?
Answer: When Kibana has been installed using a .tar.gz package on Linux, it can be started from the command line using the following command:/bin/kibana.
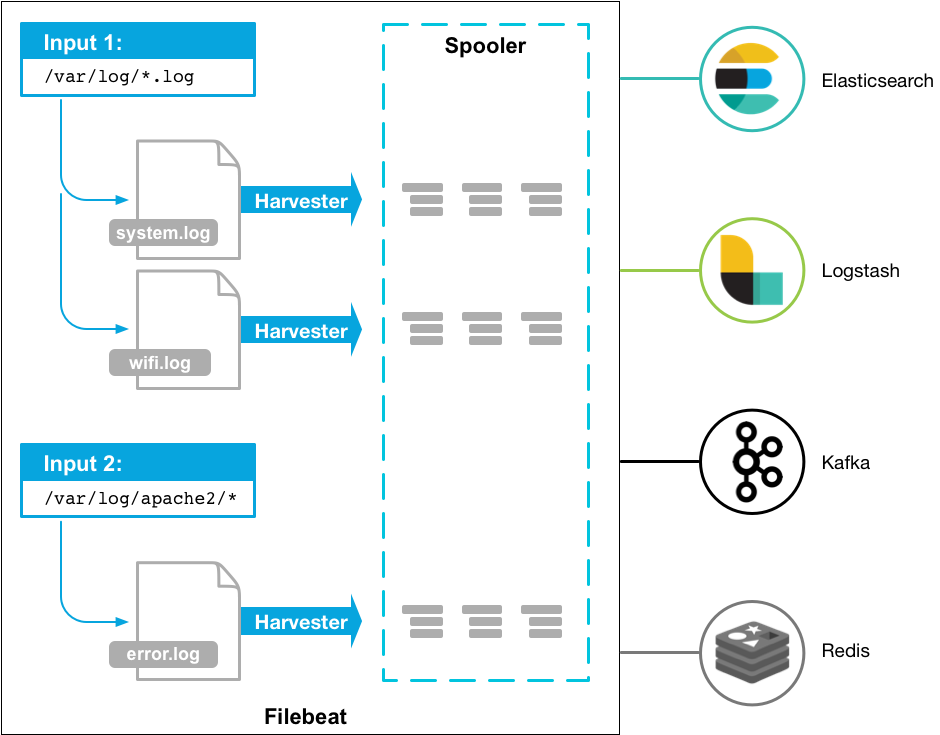
38. What is Filebeat?
Answer:
39. What is Metricbeat?
Answer: Metricbeat is a metrics shipper built on the Libbeat framework. It originated from Topbeat (which has now been deprecated) and is primarily used for collecting metrics prior to their enrichment within Logstash for further processing within Elasticsearch & Kibana. Some users of Metricbeat may not wish to automatically push their metrics data to Logstash, in this instance they would likely use a service (for example Kafka or Redis) to buffer the data.
40. What is Heartbeat?
Answer: Heartbeat is a lightweight shipping agent that was created to allow observability of the health of services running on a specified host, its results can then be forwarded to Logstash for further processing. Heartbeat is notable for the fact that it is the only member of the Beats family that Elastic themselves recommend you to install on a separate network/machine external to the one you are currently wishing to monitor.
41. What is WinLogBeat?
Answer: Winlogbeat is a log shipper used for collecting Windows event logs as it can easily read events from any event log channel using the Windows operating system. Windows log data once centralized within the ELK stack can then be monitored for anomaly detection & other security-related incidents.
42. What is reindexing?
Answer: Reindexing your Elasticsearch index is mainly required in the event that you wish to update mapping or settings associated with your current index. Reindexing means that you are copying preexisting data from an index that already exists to a new destination index. The command endpoint _reindex can be used for this purpose.
43. How do you view an index template?
Answer: There are two ways you can view the current index template of your ELK Stacks, one of these uses Kibana dev tools and the second option involves using the Template Index API.
44. What is fuzzy search?
Answer: Fuzzy search allows Elasticsearch to return positive matches for non-exact matches of the term you are searching for. This is especially beneficial for eCommerce retailers where site visitors may often have typos in their spelling when trying to locate a product they wish to purchase. Fuzzy match results mean that these visitors are not served with a blank page which would often lead to a user being less likely to convert.
45. What is Grok?
Answer: Grok is a filter plugin for Logstash that is used to parse unstructured data. It is often used for transforming Apache, Syslog, and other webserver logs into a structured and queryable format for easier data analysis to be performed.
46. How can you make balanced shards?
Answer: Your clusters and/or shards are considered balanced when they have an equal number of shards across each node, thankfully Elasticsearch will run an automatic process of rebalancing shards which moves shards between the nodes that make up your cluster in order to improve its performance. You may need to take manual action if your configurations for forced awareness or allocation filtering clashes with Elasticsearch’s attempts to automatically rebalance shards.
47. What does Logstash forwarder do?
Answer: Filebeat is based on the Logstash Forwarder source code and replaces Logstash Forwarder as the method to use for tailing log files and forwarding them to Logstash. The registry file, which stores the state of the currently read files, was changed.
48. What is the Power of Logstash?
Answer:
The ingestion workhorse for Elasticsearch and more – Horizontally scalable data processing pipeline with strong Elasticsearch and Kibana synergy
Pluggable pipeline architecture – Mix, match, and orchestrate different inputs, filters, and outputs to play in pipeline harmony
Community-extensible and developer-friendly plugin ecosystem – Over 200 plugins available, plus the flexibility of creating and contributing your own
49. What Are Codecs In Logstash?
Answer: Codecs are essentially streamed filters that could perform as a part of an entering or output. Codecs allow you to easily separate the delivery of your messages from the serialization manner. Popular codecs encompass json, msgpack, and plain (text).Json: encode or decode statistics in the JSON layout. Multiline: merge a couple of-line textual content events which include java exceptions and stack hint messages right into a single occasion.
50. How Many Types Of Logstash Configuration Files Are There?
Answer: Logstash has styles of configuration documents: pipeline configuration documents, which outline the Logstash processing pipeline, and settings files, which specify options that manage Logstash startup and execution.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
