Trunk
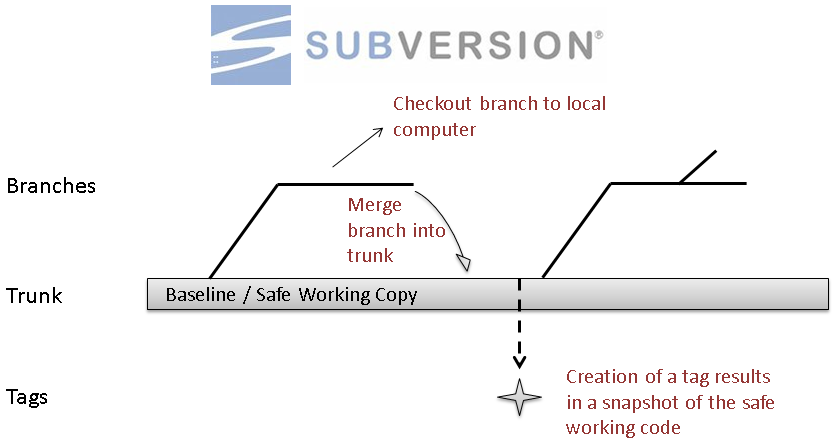
Trunk would be the main body of development, originating from the start of the project until the present. The main development area. This is where your next major release of the code lives, and generally has all the newest features.
Branch
Branch will be a copy of code derived from a certain point in the trunk that is used for applying major changes to the code while preserving the integrity of the code in the trunk. If the major changes work according to plan, they are usually merged back into the trunk. Every time you release a major version, it gets a branch created. This allows you to do bug fixes and make a new release without having to release the newest – possibly unfinished or untested – features.
Tag
Tag will be a point in time on the trunk or a branch that you wish to preserve. The two main reasons for preservation would be that either this is a major release of the software, whether alpha, beta, RC or RTM, or this is the most stable point of the software before major revisions on the trunk were applied. Every time you release a version (final release, release candidates (RC), and betas) you make a tag for it. This gives you a point-in-time copy of the code as it was at that state, allowing you to go back and reproduce any bugs if necessary in a past version, or re-release a past version exactly as it was. Branches and tags in SVN are lightweight – on the server, it does not make a full copy of the files, just a marker saying “these files were copied at this revision” that only takes up a few bytes. With this in mind, you should never be concerned about creating a tag for any released code. As I said earlier, tags are often omitted and instead, a changelog or other document clarifies the revision number when a release is made.
In open source projects, major branches that are not accepted into the trunk by the project stakeholders can become the bases for forks — e.g., totally separate projects that share a common origin with other source code.
The branch and tag subtrees are distinguished from the trunk in the following ways:
Subversion allows sysadmins to create hook scripts which are triggered for execution when certain events occur; for instance, committing a change to the repository. It is very common for a typical Subversion repository implementation to treat any path containing “/tag/” to be write-protected after creation; the net result is that tags, once created, are immutable (at least to “ordinary” users). This is done via the hook scripts, which enforce the immutability by preventing further changes if tag is a parent node of the changed object.
Subversion also has added features, since version 1.5, relating to “branch merge tracking” so that changes committed to a branch can be merged back into the trunk with support for incremental, “smart” merging.
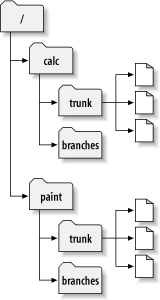
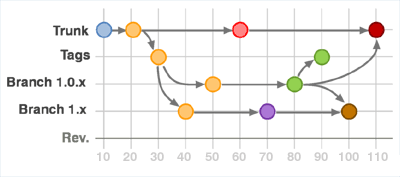
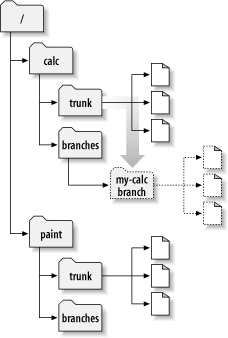
Example and Use Cases of Trunk Vs Branch Vs Tag
For example, let’s say you start a new project. You start working in “trunk”, on what will eventually be released as version 1.0.
- trunk/ – development version, soon to be 1.0
- branches/ – empty
Once 1.0.0 is finished, you branch trunk into a new “1.0” branch, and create a “1.0.0” tag. Now work on what will eventually be 1.1 continues in trunk.
- trunk/ – development version, soon to be 1.1
- branches/1.0 – 1.0.0 release version
- tags/1.0.0 – 1.0.0 release version
You come across some bugs in the code, and fix them in trunk, and then merge the fixes over to the 1.0 branch. You can also do the opposite, and fix the bugs in the 1.0 branch and then merge them back to trunk, but commonly projects stick with merging one-way only to lessen the chance of missing something. Sometimes a bug can only be fixed in 1.0 because it is obsolete in 1.1. It doesn’t really matter: you only want to make sure that you don’t release 1.1 with the same bugs that have been fixed in 1.0.
- trunk/ – development version, soon to be 1.1
- branches/1.0 – upcoming 1.0.1 release
- tags/1.0.0 – 1.0.0 release version
Once you find enough bugs (or maybe one critical bug), you decide to do a 1.0.1 release. So you make a tag “1.0.1” from the 1.0 branch, and release the code. At this point, trunk will contain what will be 1.1, and the “1.0” branch contains 1.0.1 code. The next time you release an update to 1.0, it would be 1.0.2.
- trunk/ – development version, soon to be 1.1
- branches/1.0 – upcoming 1.0.2 release
- tags/1.0.0 – 1.0.0 release version
- tags/1.0.1 – 1.0.1 release version
Eventually you are almost ready to release 1.1, but you want to do a beta first. In this case, you likely do a “1.1” branch, and a “1.1beta1” tag. Now, work on what will be 1.2 (or 2.0 maybe) continues in trunk, but work on 1.1 continues in the “1.1” branch.
- trunk/ – development version, soon to be 1.2
- branches/1.0 – upcoming 1.0.2 release
- branches/1.1 – upcoming 1.1.0 release
- tags/1.0.0 – 1.0.0 release version
- tags/1.0.1 – 1.0.1 release version
- tags/1.1beta1 – 1.1 beta 1 release version
Once you release 1.1 final, you do a “1.1” tag from the “1.1” branch.
You can also continue to maintain 1.0 if you’d like, porting bug fixes between all three branches (1.0, 1.1, and trunk). The important takeaway is that for every main version of the software you are maintaining, you have a branch that contains the latest version of code for that version.
Another use of branches is for features. This is where you branch trunk (or one of your release branches) and work on a new feature in isolation. Once the feature is completed, you merge it back in and remove the branch.
trunk/ – development version, soon to be 1.2
branches/1.1 – upcoming 1.1.0 release
branches/ui-rewrite – experimental feature branch
The idea of this is when you’re working on something disruptive (that would hold up or interfere with other people from doing their work), something experimental (that may not even make it in), or possibly just something that takes a long time (and you’re afraid if it holding up a 1.2 release when you’re ready to branch 1.2 from trunk), you can do it in isolation in branch. Generally you keep it up to date with trunk by merging changes into it all the time, which makes it easier to re-integrate (merge back to trunk) when you’re finished.
In short
- A trunk in SVN is main development area, where major development happens.
- A branch in SVN is sub development area where parallel development on different functionalities happens. After completion of a functionality, a branch is usually merged back into trunk.
- A tag in SVN is read only copy of source code from branch or tag at any point of time. tag is mostly used to create a copy of released source code for restore and backup.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND

Dear Rajesh,
I quickly learned from your article terms like trunk, branche, and tag.
Thank you for your work.
Kind regards
Leszek