
Apache Druid is among the most popular open-source Apache Druid is a real-time analytics database designed for fast slice-and-dice analytics (OLAP). As pre-existing open-source databases like Relational Database Management System (RDBMS) and NoSQL were incapable of offering a low latency data ingestion and query platform for interactive applications, the need for Druid was stimulated.
Apache Druid has been initially designed for problem-solving around ingesting and exploring large log data quantities. Apache Druid aims to quickly compute drill-downs and aggregate the data sets. Due to its features, Druid is being used by renowned brands like Netflix and Airbnb to run queries on data streams constituting billions of events per minute. The most remarkable being:
- Scalability, thanks to a self-healing architecture
- Typical <1s to 4–5s query latency
- Flexible table schemas over a columnar dataset
- Time-based partitioning and querying
- Native JSON + standard SQL querying
- Fast data pre-aggregations
Common application areas for Druid include:
- Clickstream analytics including web and mobile analytics
- Network telemetry analytics including network performance monitoring
- Server metrics storage
- Supply chain analytics including manufacturing metrics
- Application performance metrics
- Digital marketing/advertising analytics
- Business intelligence/OLAP
History
Apache Druid was started in 2011 by Eric Tschetter, Fangjin Yang, Gian Merlino and Vadim Ogievetsky to power the analytics product of Met markets. The project was open-sourced under the GPL license in October 2012 and moved to an Apache License in February 2015.
In Apache Druid, there are three types of columns:
- Timestamp → used for partitioning and sorting
- Dimension → a field that can be queried via filters
- Metric → an optional field, representing data aggregated from other fields (e.g the sum of characters in another field)
What is Apache Druid Architecture?
The Druid architecture can be divided in three different layers:
- Data servers
- Master servers
- Query servers
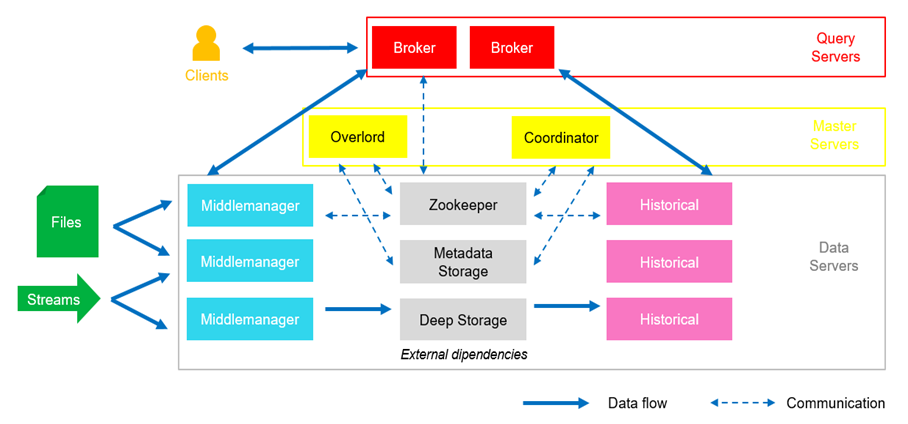
- Data Server Layer
In this layer, data is ingested, stored and retrieved.
Data enter the framework through Middle Managers, the component that handles ingestions by processing tasks and creating new Segments. They are responsible of how data is indexed, pre-aggregated, split into segments and published into Deep Storage.
- Master Server Layer
This layer manages data availability and ingestion using Overlords, components that balance data over MiddleManager processes, assigning ingestion tasks and coordinating segment availability. Coordinators, on the other hand, are components that balance data among Historical processes, notifying them when segments need to be loaded, dropping outdated segments and managing segment replication.
- Query Server Layer
This layer is responsible for handling queries from external clients and providing the results. It uses components called Brokers that receive queries from clients, identify which Historical and MiddleManager nodes are serving those segments, split and rewrite the main query into subqueries and send everything to each one of these processes. At the very end, Brokers collect and merge the results to be provided to the client.
What are the key features of Apache Druid?
Apache Druid’s core architecture combines ideas from data warehouses, time series databases, and log search systems. Some of Druid’s key features are:
- Columnar storage format
Druid uses column-oriented storage. This means it only loads the exact columns needed for a particular query. This greatly improves speed for queries that retrieve only a few columns. Additionally, to support fast scans and aggregations, Druid optimizes column storage for each column according to its data type.
- Scalable distributed system
Typical Druid deployments span clusters ranging from tens to hundreds of servers. Druid can ingest data at the rate of millions of records per second while retaining trillions of records and maintaining query latencies ranging from the sub-second to a few seconds.
- Real-time or batch ingestion
Apache Druid can ingest data either real-time or in batches. Ingested data is immediately available for querying.
- Self-healing, self-balancing, easy to operate
As an operator, you add servers to scale out or remove servers to scale down. The Druid cluster re-balances itself automatically in the background without any downtime. If a Druid server fails, the system automatically routes data around the damage until the server can be replaced. Druid is designed to run continuously without planned downtime for any reason. This is true for configuration changes and software updates.
- Cloud-native, fault-tolerant architecture that won’t lose data
After ingestion, Apache Druid safely stores a copy of your data in deep storage. Deep storage is typically cloud storage, HDFS, or a shared filesystem. You can recover your data from deep storage even in the unlikely case that all Druid servers fail. For a limited failure that affects only a few Druid servers, replication ensures that queries are still possible during system recoveries.
- Indexes for quick filtering
Apache Druid uses roaring or CONCISE compressed bitmap indexes to create indexes to enable fast filtering and searching across multiple columns.
- Time-based partitioning
Apache Druid first partitions data by time. You can optionally implement additional partitioning based upon other fields. Time-based queries only access the partitions that match the time range of the query which leads to significant performance improvements.
- Approximate algorithms
Apache Druid includes algorithms for approximate count-distinct, approximate ranking, and computation of approximate histograms and quantiles. These algorithms offer bounded memory usage and are often substantially faster than exact computations. For situations where accuracy is more important than speed, Druid also offers exact count-distinct and exact ranking.
- Automatic summarization at ingest time
Druid optionally supports data summarization at ingestion time. This summarization partially pre-aggregates your data, potentially leading to significant cost savings and performance boosts.
Conclusion
Apache Druid’s structure is not really lightweight, because of the amount of components involved. Still, this allows for a proper horizontal scaling of the architecture, simply by incrementing the number of the nodes (MiddleManagers, Historicals, etc.)
I hope you like this particular blog. Thank you!!
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND
