What is Apache Flink?

Apache Flink is an open-source stream processing and batch processing framework designed for high-throughput, low-latency, and fault-tolerant data processing. It provides a unified programming model for both stream and batch processing, enabling developers to build real-time and batch data processing pipelines. Flink’s key strength lies in its ability to process data in a continuous and event-driven manner, making it suitable for applications that require fast and accurate data analysis.
Top 10 use cases of Apache Flink:
Here are the top 10 use cases of Apache Flink:
- Real-Time Analytics: Flink excels at processing and analyzing streaming data in real time, making it ideal for scenarios that require immediate insights from data as it arrives.
- Fraud Detection: Flink’s low-latency processing capabilities are well-suited for fraud detection applications, where timely identification of anomalies or suspicious activities is crucial.
- Event Monitoring: Flink can be used to monitor events in real time, such as monitoring social media feeds, tracking user interactions, and responding to events as they occur.
- Clickstream Analysis: For web applications and online businesses, Flink helps analyze user interactions, allowing organizations to optimize user experiences and conversions.
- IoT Data Processing: Internet of Things (IoT) applications generate massive streams of data from sensors and devices. Flink can process this data in real time to enable real-time monitoring and insights.
- Real-Time Recommendations: Flink’s fast processing capabilities make it suitable for generating real-time recommendations for users, such as personalized content or product recommendations.
- Streaming ETL (Extract, Transform, Load): Flink can be used to perform ETL operations on streaming data, enabling data preparation and transformation before storage or analysis.
- Log Analysis and Monitoring: Flink is used to process logs and events generated by systems and applications, allowing for real-time monitoring, anomaly detection, and troubleshooting.
- Predictive Analytics: Flink can be applied to predictive analytics use cases, where historical and streaming data are combined to make real-time predictions and forecasts.
- Supply Chain Optimization: In logistics and supply chain management, Flink can process data related to shipments, inventory, and demand to optimize routes and inventory levels.
- Financial Trading: Flink’s low-latency capabilities are valuable for processing real-time financial data and executing high-frequency trading strategies.
- Healthcare Data Processing: Flink can be used in healthcare applications for processing and analyzing real-time patient data, enabling timely interventions and monitoring.
These use cases highlight Flink’s versatility and ability to handle various real-time and data-intensive scenarios. Its support for event time processing, windowing, and stateful computations makes it suitable for applications that require accurate and efficient processing of streaming data.
What are the feature of Apache Flink?
Apache Flink offers a rich set of features that make it a powerful framework for both stream processing and batch processing. Its design aims to provide high performance, fault tolerance, and flexibility for building data processing applications. Here are some key features of Apache Flink:
- Stream and Batch Processing: Flink supports both stream processing and batch processing, providing a unified programming model for building real-time and batch data pipelines.
- Event Time Processing: Flink handles event time processing, allowing developers to process data based on the timestamp of events, even if they arrive out of order.
- Windowing: Flink provides flexible windowing mechanisms to group and process data in time-based or count-based windows. This is crucial for aggregations and analytics over time.
- Stateful Processing: Flink supports stateful computations, enabling applications to maintain and update state across event time and windows. This is useful for sessionization and complex analytics.
- Low Latency: Flink is designed for low-latency processing, making it suitable for real-time applications that require fast responses to incoming data.
- Exactly-Once Processing: Flink ensures exactly-once processing semantics, meaning that each piece of data is processed only once, even in the presence of failures.
- Fault Tolerance: Flink provides fault tolerance through mechanisms like distributed snapshots and checkpoints, allowing applications to recover from failures.
- Dynamic Scaling: Flink can dynamically scale the processing capacity up or down based on the incoming data volume, optimizing resource utilization.
- Event Time Watermarks: Flink uses watermarks to track event time progress and handle late data, ensuring accurate processing of event time-based operations.
- Connectors: Flink offers connectors to various data sources and sinks, including messaging systems, databases, file systems, and more.
- Iterative Processing: Flink supports iterative processing patterns, making it suitable for machine learning algorithms and graph processing.
- Rich API: Flink provides a rich set of APIs in multiple languages, including Java, Scala, and Python, enabling developers to write complex data processing logic.
How Apache Flink Works and Architecture?
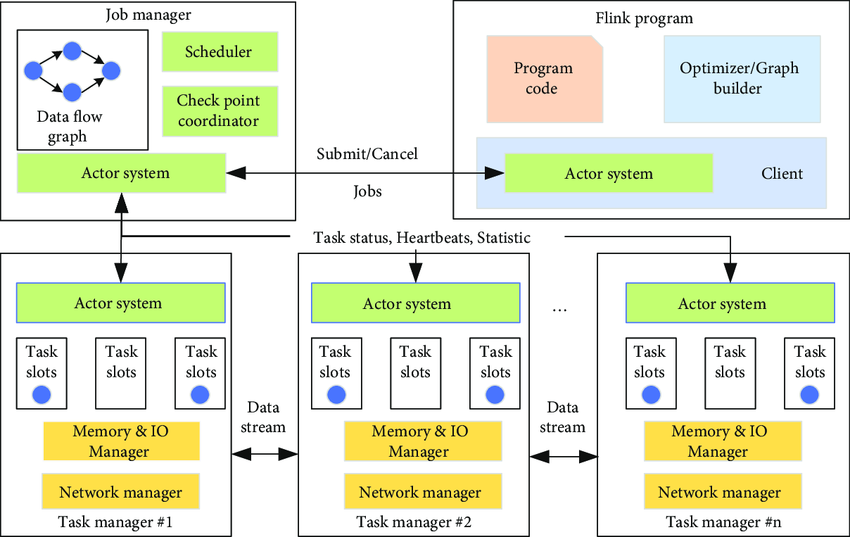
- Pipeline Definition: Developers define their data processing pipeline using Flink’s APIs. The pipeline includes sources (data input), transformations, and sinks (data output).
- DAG Generation: Flink translates the pipeline definition into a directed acyclic graph (DAG), representing the sequence of transformations and data flows.
- Job Submission: Users submit the Flink job to a Flink cluster for execution. The cluster consists of a JobManager and multiple TaskManagers.
- JobManager: The JobManager is responsible for coordinating the execution of the job. It splits the pipeline into tasks and distributes them to TaskManagers.
- TaskManagers: TaskManagers are worker nodes that execute the tasks. They receive tasks from the JobManager and process data in parallel.
- Data Processing: TaskManagers process data according to the defined transformations. Tasks can run in parallel across multiple TaskManagers.
- State Management: Flink manages state by periodically taking snapshots of the application’s state. In case of failure, the application can be restored from the last checkpoint.
- Windowing and Time Handling: Flink applies windowing logic to process data in time-based or count-based windows, supporting operations like aggregations.
- Event Time Handling: Flink handles event time by assigning watermarks to track progress and manage out-of-order events.
- Output: Processed data is sent to the specified output sinks, which could be databases, storage systems, messaging systems, and more.
- Fault Tolerance: Flink ensures fault tolerance by taking checkpoints and maintaining state. If a TaskManager fails, its tasks can be restarted on other TaskManagers.
- Completion and Cleanup: Once the job is completed, resources are released, and cleanup tasks are performed.
- Metrics and Monitoring: Flink provides metrics and monitoring capabilities to track the progress, performance, and health of the job.
Overall, Flink’s architecture combines its distributed nature with features like fault tolerance, event time processing, and windowing to enable accurate, real-time data processing across various use cases. The modular architecture of Flink allows it to be integrated with different data sources, processing engines, and storage systems, making it a versatile framework for building data processing applications.
How to Install Apache Flink?
Here are the steps on how to install Apache Flink on Windows:
- Install Java 8 or later. You can download the Java installer from the Oracle website: https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html.
- Download the Apache Flink binary distribution for Windows. You can find the download links on the Apache Flink website: https://flink.apache.org/downloads.html.
- Unzip the binary distribution to a directory of your choice.
- Add the directory where you unzipped the binary distribution to your system path. You can execute this by editing the
PATHenvironment variable.
Here are the steps on how to install Apache Flink on macOS:
- Install Java 8 or later. You can download the Java installer from the Oracle website: https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html.
- Download the Apache Flink binary distribution for macOS. You can find the download links on the Apache Flink website: https://flink.apache.org/downloads.html.
- Unzip the binary distribution to a directory of your choice.
- Add the directory where you unzipped the binary distribution to your system path. You can execute this by editing the
PATHenvironment variable.
Here are the steps on how to install Apache Flink on Linux:
- Install Java 8 or later. You can download the Java installer from the Oracle website: https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html.
- Download the Apache Flink binary distribution for Linux. You can find the download links on the Apache Flink website: https://flink.apache.org/downloads.html.
- Unzip the binary distribution to a directory of your choice.
- Add the directory where you unzipped the binary distribution to your system path. You can execute this by editing the
PATHenvironment variable.
Once you have installed Apache Flink, you can start running jobs. You can find more information about running jobs in the Apache Flink documentation: https://flink.apache.org/documentation/.
Here are some of the benefits of using Apache Flink:
- It is a distributed streaming engine that can process data in real time.
- It is fault-tolerant and can improve from failures.
- It is more scalable and can handle huge amounts of data.
- It is free to work and open-source.
Here are some of the drawbacks of using Apache Flink:
- It can be complex to learn and use.
- It is not as well-known as some other streaming engines, such as Spark Streaming.
Overall, Apache Flink is a powerful and versatile streaming engine that can be used to process data in real time. It is a good choice for developers who want to build scalable, reliable, and fault-tolerant streaming applications.
Basic Tutorials of Apache Flink: Getting Started

The following are the steps of basic tutorials of Apache Flink:
- Create a new Apache Flink project in IntelliJ IDEA
To create a new Apache Flink project in IntelliJ IDEA, you can follow these steps:
1. Open IntelliJ IDEA.
2. Click on the "Create New Project" button.
3. In the "New Project" dialog box, select the "Project" project type and click on the "Next" button.
4. In the "Choose a project SDK" dialog box, select the "Java SDK 1.8" option and click on the "Next" button.
5. In the "Configure Project" dialog box, enter a name for your project and click on the "Finish" button.Code language: JavaScript (javascript)- Add the Apache Flink dependency to your project
To add the Apache Flink dependency to your project, you can follow these steps:
1. In IntelliJ IDEA, Unlock your project.
2. In the project window, right-click on the "pom.xml" file and select the "Open Module Settings" menu item.
3. Choose the "Dependencies" tab in the "Module Settings" dialog box.
4. Click on the "+" button and select the "Add Library" menu item.
5. In the "Add Library" dialog box, select the "Maven" tab.
6. Type "org.apache.flink" in the "Group ID" field.
7. In the "Artifact ID" field, enter "flink-streaming-java_2.12".
8. Click on the "OK" button.Code language: JavaScript (javascript)- Write a simple Apache Flink job
A simple Apache Flink job can be written in a few lines of code. The following is an example of a simple job that reads a file and prints the contents of the file to the console:
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCountJob {
public static void main(String[] args) throws Exception {
// Set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Create a stream of text data
DataStream<String> textStream = env.socketTextStream("localhost", 9999);
// Transform the text into word-count pairs
DataStream<Tuple2<String, Integer>> wordCountStream = textStream
.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
for (String word : line.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
})
.keyBy(0)
.sum(1);
// Print the word counts to stdout
wordCountStream.print();
// Execute the job
env.execute("WordCountJob");
}
}Code language: JavaScript (javascript)- Run your Apache Flink job
To run your Apache Flink job, you can use the execute() method of the ExecutionEnvironment object. The following code runs the job that was created in the previous step:
env.execute("SimpleJob");Code language: JavaScript (javascript)
👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
