History & Origin of Apache MxNet
Apache MXNet.
The Apache MXNet framework (incubating at the Apache Software Foundation) was developed to enable multiple approaches to the problem of deep learning. One route for reducing the time it takes to train deep learning models involves defining the model and separating it from the algorithm. While this approach speeds training, it can add constraints and complexity because it is hard to update as understanding of the problem improves. Other neural network libraries address this by adding more flexibility, but at the cost of training speed.
Perhaps appropriately, the idea of taking more than one route to tackling a problem is paralleled in other technical aspects of the framework, and in the Apache MXNet community itself. MXNet gives developers the best of both worlds. It provides a concise, easy to understand, dynamic programming interface for defining both the model and the algorithm, without sacrificing training speed.
What is Apache MxNet ?
MXNet is an open-source deep learning framework that allows you to define, train, and deploy deep neural networks on a wide array of devices, from cloud infrastructure to mobile devices. It’s highly scalable, allowing for fast model training, and supports a flexible programming model and multiple languages.
WHY APACHE MXNET?
Apache MXNet offers the following key features and benefits:
- Hybrid frontend: The imperative symbolic hybrid Gluon API provides an easy way to prototype, train, and deploy models without sacrificing training speed. Developers need just a few lines of Gluon code to build linear regression, CNN, and recurrent LSTM models for such uses as object detection, speech recognition, and recommendation engines.
- Scalability: Designed from the ground up for cloud infrastructure, MXNet uses a distributed parameter server that can achieve an almost linear scale using multiple GPUs or CPUs. Deep learning workloads can be distributed across multiple GPUs with near-linear scalability and auto-scaling. Tests run by Amazon Web Services found that MXNet performed 109 times faster across a cluster of 128 GPUs than with a single GPU. It’s because of the ability to scale to multiple GPUs (across multiple hosts) along with development speed and portability that AWS adopted MXNet as its deep learning framework of choice over alternatives such as TensorFlow, Theano, and Torch.
- Ecosystem: MXNet has toolkits and libraries for computer vision, natural language processing, time series, and more.
- Languages: MXNet-supported languages include Python, C++, R, Scala, Julia, Matlab, and JavaScript. MXNet also compiles to C++, producing a lightweight neural network model representation that can run on everything from low-powered devices like Raspberry Pi to cloud servers.
How Apache MxNet works aka Apache MxNet architecture?
MXNet System Architecture
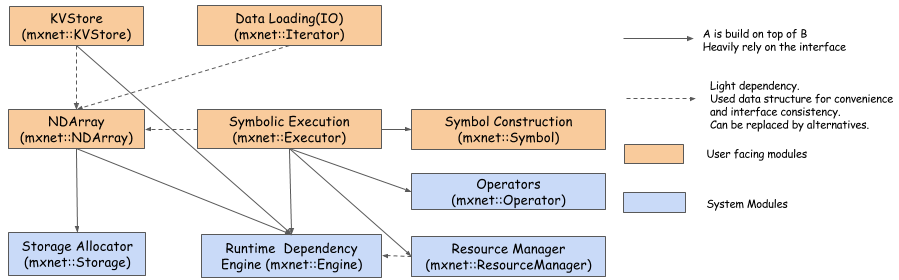
This figure shows the major modules and components of the MXNet system and their interaction. The modules are:
- Runtime Dependency Engine: Schedules and executes the operations according to their read/write dependency.
- Storage Allocator: Efficiently allocates and recycles memory blocks on host (CPU) and devices (GPUs).
- Resource Manager: Manages global resources, such as the random number generator and temporal space.
- NDArray: Dynamic, asynchronous n-dimensional arrays, which provide flexible imperative programs for MXNet.
- Symbolic Execution: Static symbolic graph executor, which provides efficient symbolic graph execution and optimization.
- Operator: Operators that define static forward and gradient calculation (backprop).
- SimpleOp: Operators that extend NDArray operators and symbolic operators in a unified fashion.
- Symbol Construction: Symbolic construction, which provides a way to construct a computation graph (net configuration).
- KVStore: Key-value store interface for efficient parameter synchronization.
- Data Loading(IO): Efficient distributed data loading and augmentation.
MXNet System Components
Execution Engine
You can use MXNet’s engine not only for deep learning, but for any domain-specific problem. It’s designed to solve a general problem: execute a bunch of functions following their dependencies. Execution of any two functions with dependencies should be serialized. To boost performance, functions with no dependencies can be executed in parallel. For a general discussion of this topic, see our notes on the dependency engine.
Interface
The following API is the core interface for the execution engine:
virtual void PushSync(Fn exec_fun, Context exec_ctx,
std::vector<VarHandle> const& const_vars,
std::vector<VarHandle> const& mutate_vars) = 0;This API allows you to push a function (exec_fun), along with its context information and dependencies, to the engine. exec_ctx is the context information in which the exec_fun should be executed, const_vars denotes the variables that the function reads from, and mutate_vars are the variables to be modified. The engine provides the following guarantee:
The execution of any two functions that modify a common variable is serialized in their push order.
Function
The function type of the engine is:
using Fn = std::function<void(RunContext)>;RunContext contains runtime information, which is determined by the engine:
struct RunContext {
// stream pointer which could be safely cast to
// cudaStream_t* type
void *stream;
};Alternatively, you could use mxnet::engine::DAGEngine::Fn, which has the same type definition.
All of the functions are executed by the engine’s internal threads. In such a model, it’s usually not a good idea to push blocking functions to the engine (usually for dealing with I/O tasks like disk, web service, UI, etc.) because it will occupy the execution thread and reduce total throughput. In that case, we provide another asynchronous function type:
using Callback = std::function<void()>;
using AsyncFn = std::function<void(RunContext, Callback)>;MXNet Architecture
Building a high-performance deep learning library requires many systems-level design decisions. In this design note, we share the rationale for the specific choices made when designing MXNet. We imagine that these insights may be useful to both deep learning practitioners and builders of other deep learning systems.
Deep Learning System Design Concepts
The following pages address general design concepts for deep learning systems. Mainly, they focus on the following 3 areas: abstraction, optimization, and trade-offs between efficiency and flexibility. Additionally, we provide an overview of the complete MXNet system.
- MXNet System Overview
- Deep Learning Programming Style: Symbolic vs Imperative
- Dependency Engine for Deep Learning
- Optimizing the Memory Consumption in Deep Learning
- Efficient Data Loading Module for Deep Learning
- Exception Handling in MXNet
Use case of Apache MxNet
Smartphone Apps
MXNet is well-suited for image recognition, and its ability to support models that run on low-power, limited-memory platforms make it a good choice for mobile phone deployment. Models built with MXNet have been shown to provide highly reliable image recognition results running natively on laptop computers. Combining local and cloud processors could enable powerful distributed applications in areas like augmented reality, object, and scene identification.
Voice and image recognition applications also have intriguing possibilities for people with disabilities. For example, mobile apps could help vision-impaired people to better perceive their surroundings and people with hearing impairments to translate voice conversations into text.
Autonomous Vehicles
Self-driving cars and trucks must process an enormous amount of data to make decisions in near-real-time. The complex networks that are developing to support fleets of autonomous vehicles use distributed processing to an unprecedented degree to coordinate everything from the braking decisions in a single car to traffic management across an entire city.
TuSimple—which is building an autonomous freight network of mapped routes that allow for autonomous cargo shipments across the southwestern U.S.—chose MXNet as its foundational platform for artificial intelligence model development. The company is bringing self-driving technology to an industry plagued with a chronic driver shortage as well as high overhead due to accidents, shift schedules, and fuel inefficiencies.
TuSimple chose MXNet because of its cross-platform portability, training efficiency, and scalability. One factor was a benchmark that compared MXNet against TensorFlow and found that in an environment with eight GPUs, MXNet was faster, more memory-efficient, and more accurate.
Feature and Advantage of using Apache MxNet
Various Features
If you are looking for a flexible deep learning library to quickly develop cutting-edge deep learning research or a robust platform to push production workload, your search ends at Apache MXNet. It is because of the following features of it:
Distributed Training
Whether it is multi-gpu or multi-host training with near-linear scaling efficiency, Apache MXNet allows developers to make most out of their hardware. MXNet also support integration with Horovod, which is an open source distributed deep learning framework created at Uber.
For this integration, following are some of the common distributed APIs defined in Horovod:
- horovod.broadcast()
- horovod.allgather()
- horovod.allgather()
In this regard, MXNet offer us the following capabilities:
- Device Placement − With the help of MXNet we can easily specify each data structure (DS).
- Automatic Differentiation − Apache MXNet automates the differentiation i.e. derivative calculations.
- Multi-GPU training − MXNet allows us to achieve scaling efficiency with number of available GPUs.
- Optimized Predefined Layers − We can code our own layers in MXNet as well as the optimized the predefined layers for speed also.
Best Alternative of Apache MxNet
- TensorFlow. TensorFlow is an open source software library for numerical computation using. …
- PyTorch. PyTorch is not a Python binding into a monolothic C++ framework. …
- Theano. Theano is a Python library that lets you to define, optimize, and evaluate mathematical. …
- Gluon. …
- NumPy. …
- Flux. …
- scikit-learn.
Best Resources, Tutorials and Guide for Apache MxNet
Free Video Tutorials of Apache MxNet
Interview Questions and Answer for Apache MxNet
- Why Apache MXNet is a powerful open-source deep learning software framework instrument helping developers build, train, and deploy Deep Learning models?
The Apache MXNet is a powerful open-source deep learning software framework instrument helping developers build, train, and deploy Deep Learning models.
2. What are the best deep learning platforms?
There are various deep learning platforms like Torch7, Caffe, Theano, TensorFlow, Keras, Microsoft Cognitive Toolkit, etc.
3. Which is a Gluon toolkit for computer vision powered by MXNet?

GluonCV is a Gluon toolkit for computer vision powered by MXNet.
4. Which of the following are features of GluonCV?
All of the below are features of GluonCV:-
- More than 170+ high quality pretrained models
- Embrace flexible development pattern
- Easy to understand implementations
5. GluonTS is a Gluon toolkit for Probabilistic Time Series Modeling powered by MXNet. State true or flase?
True, GluonTS is a Gluon toolkit for Probabilistic Time Series Modeling powered by MXNet.
6. Which module provides flexible imperative programs for Apache MXNet?
NDArray : It provides flexible imperative programs for Apache MXNet. They are dynamic and asynchronous n-dimensional arrays.
7. Which is a Gluon toolkit for Natural Language Processing (NLP) powered by MXNet?

GluonNLP is a Gluon toolkit for Natural Language Processing (NLP) powered by MXNet.
8. Which API is not thread safe which means that only one thread should make engine API calls at a time?
Push API is not thread safe which means that only one thread should make engine API calls at a time.
9. Operator system module consists of all the operators that define static forward and gradient calculation?
Yes, Operator system module consists of all the operators that define static forward and gradient calculation.
10. What is the difference between Machine Learning and Deep Learning?
Machine Learning forms a subset of Artificial Intelligence, where we use statistics and algorithms to train machines with data, thereby, helping them improve with experience.
Deep Learning is a part of Machine Learning, which involves mimicking the human brain in terms of structures called neurons, thereby, forming neural networks.
11. What is a perceptron?
A perceptron is similar to the actual neuron in the human brain. It receives inputs from various entities and applies functions to these inputs, which transform them to be the output.
A perceptron is mainly used to perform binary classification where it sees an input, computes functions based on the weights of the input, and outputs the required transformation.
12. How is Deep Learning better than Machine Learning?
Machine Learning is powerful in a way that it is sufficient to solve most of the problems. However, Deep Learning gets an upper hand when it comes to working with data that has a large number of dimensions. With data that is large in size, a Deep Learning model can easily work with it as it is built to handle this.
13. What are some of the most used applications of Deep Learning?
Deep Learning is used in a variety of fields today. The most used ones are as follows:
- Sentiment Analysis
- Computer Vision
- Automatic Text Generation
- Object Detection
- Natural Language Processing
- Image Recognition
14. What is the meaning of overfitting?
Overfitting is a very common issue when working with Deep Learning. It is a scenario where the Deep Learning algorithm vigorously hunts through the data to obtain some valid information.
This makes the Deep Learning model pick up noise rather than useful data, causing very high variance and low bias. This makes the model less accurate, and this is an undesirable effect that can be prevented.
15. What are activation functions?
Activation functions are entities in Deep Learning that are used to translate inputs into a usable output parameter. It is a function that decides if a neuron needs activation or not by calculating the weighted sum on it with the bias.
Using an activation function makes the model output to be non-linear. There are many types of activation functions:
ReLU
Softmax
Sigmoid
Linear
Tanh
16. Why is Fourier transform used in Deep Learning?
Fourier transform is an effective package used for analyzing and managing large amounts of data present in a database. It can take in real-time array data and process it quickly. This ensures that high efficiency is maintained and also makes the model more open to processing a variety of signals.
17. What are the steps involved in training a perception in Deep Learning?
There are five main steps that determine the learning of a perceptron:
- Initialize thresholds and weights
- Provide inputs
- Calculate outputs
- Update weights in each step
- Repeat steps 2 to 4
18. What is the use of the loss function?
The loss function is used as a measure of accuracy to see if a neural network has learned accurately from the training data or not. This is done by comparing the training dataset to the testing dataset.
The loss function is a primary measure of the performance of the neural network. In Deep Learning, a good performing network will have a low loss function at all times when training.
19. What are some of the Deep Learning frameworks or tools that you have used?
This question is quite common in a Deep Learning interview. Make sure to answer based on the experience you have with the tools.
However, some of the top Deep Learning frameworks out there today are:
- TensorFlow
- Keras
- PyTorch
- Caffe2
- CNTK
- MXNet
- Theano
20. What is the use of the swish function?
The swish function is a self-gated activation function developed by Google. It is now a popular activation function used by many as Google claims that it outperforms all of the other activation functions in terms of computational efficiency.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I am working at Cotocus. I blog tech insights at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at I reviewed , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at PINTEREST
Rajesh Kumar at QUORA
Rajesh Kumar at WIZBRAND

Thanks for sharing Apache MxNet blog… this is very helpful for beginners. Keep it up team.