What is AWS Data Pipeline?
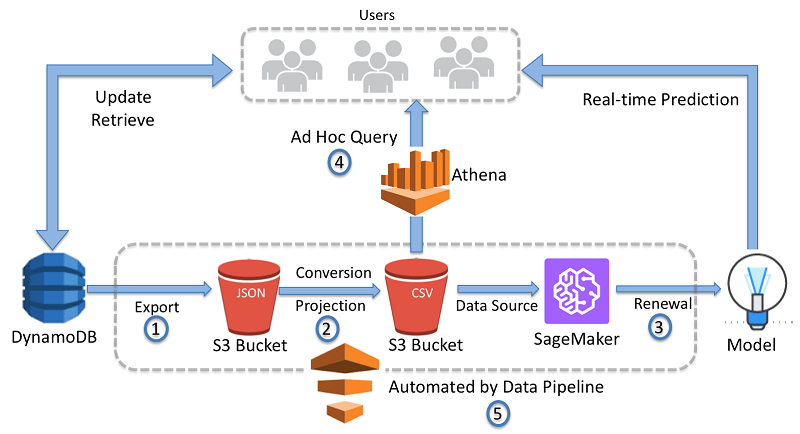
AWS Data Pipeline is a web service provided by Amazon Web Services (AWS) that enables you to orchestrate and automate the movement and transformation of data between different AWS services and on-premises data sources. It simplifies the process of creating complex data workflows and ETL (Extract, Transform, Load) tasks without the need for manual scripting or custom code. AWS Data Pipeline allows you to schedule, manage, and monitor data-driven workflows, making it easier to integrate and process data across various systems.
Top 10 use cases of AWS Data Pipeline:
- Data Transfer: Move data from on-premises data centers to AWS storage services like Amazon S3 or Amazon RDS, or vice versa.
- ETL (Extract, Transform, Load): Process and transform data from one format to another, such as converting CSV files to JSON format.
- Log Analytics: Collect and process log files from various AWS services for analysis or archival purposes.
- Backup and Restore: Automate the backup and restore of data between different storage locations.
- Data Warehouse Loading: Populate data warehouses like Amazon Redshift from different data sources.
- Cross-Region Replication: Replicate data between AWS regions for disaster recovery or data redundancy.
- Data Archiving: Archive data to long-term storage solutions like Amazon Glacier.
- Data Aggregation: Aggregate data from multiple sources into a centralized storage for reporting and analytics.
- Real-time Data Processing: Process streaming data using services like Amazon Kinesis.
- Hybrid Cloud Integration: Integrate data between on-premises systems and AWS cloud services.
What are the feature of AWS Data Pipeline?
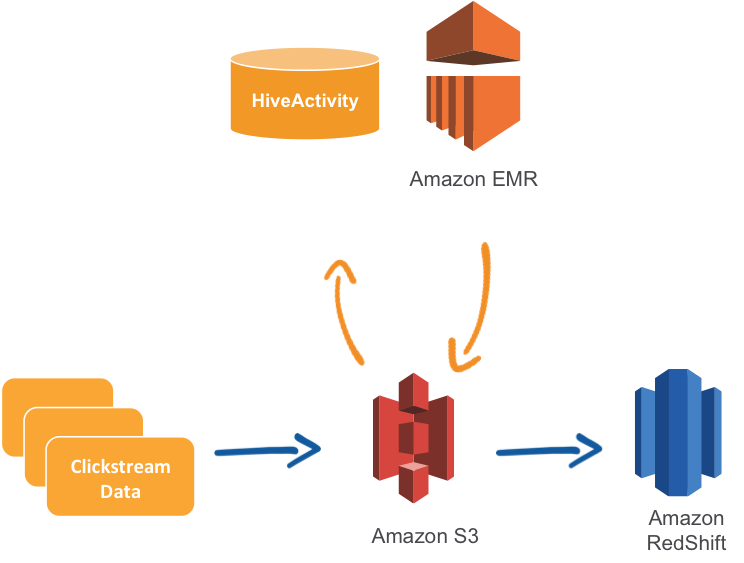
- Workflow Automation: Create complex data workflows with a drag-and-drop interface and schedule their execution.
- Data Source Flexibility: Support for various data sources, including AWS services and on-premises systems.
- Data Transformation: Perform data transformations and manipulations using built-in or custom activities.
- Error Handling: Handle errors and retries to ensure robust data processing.
- Monitoring and Alerts: Monitor pipeline activities and set up alerts for job status changes.
- Cost Optimization: Optimize data processing by defining resource limits and managing data retention.
- Security and Access Control: Use AWS Identity and Access Management (IAM) to control access to pipelines and resources.
- Data Encryption: Encrypt data at rest and in transit for enhanced security.
- Data Dependency Management: Define dependencies between pipeline activities to ensure proper execution order.
- Logging and Auditing: Log pipeline activities for auditing and troubleshooting purposes.
How AWS Data Pipeline works and Architecture?
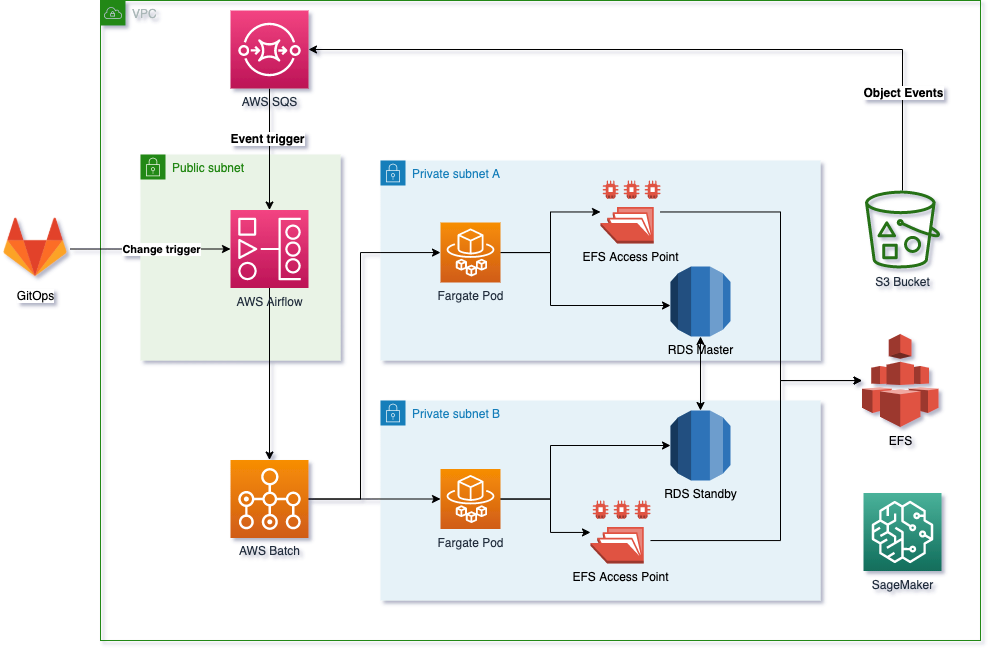
AWS Data Pipeline uses a pipeline definition, which is a JSON or AWS CloudFormation template that defines the workflow, data sources, activities, and dependencies. The pipeline definition is stored in AWS S3 or an AWS CloudFormation stack.
The architecture consists of the following components:
- Pipeline Definition: The JSON or CloudFormation template that specifies the pipeline’s structure and activities.
- Pipeline Execution Engine: The service responsible for managing the pipeline’s execution. It launches and manages the resources required for pipeline activities.
- Data Nodes: Data nodes represent the data sources, destinations, and temporary storage locations used by the pipeline.
- Activities: Activities are the tasks that perform the data processing or actions, such as running SQL queries, executing scripts, or copying data.
- IAM Roles: AWS Data Pipeline uses IAM roles to grant permissions to AWS services and actions required for pipeline execution.
- AWS S3: Pipeline definitions and temporary storage for intermediate data are stored in Amazon S3.
How to Install AWS Data Pipeline?
AWS Data Pipeline is a managed service provided by AWS, and you do not need to install it like traditional software. To use AWS Data Pipeline, you need to sign in to the AWS Management Console and start creating and configuring your pipelines.
Here are the general steps to get started with AWS Data Pipeline:
- Sign in to the AWS Management Console (https://aws.amazon.com/console/).
- Navigate to the AWS Data Pipeline service.
- Click on the “Create new pipeline” button.
- Define your pipeline by specifying data sources, destinations, activities, and scheduling options using the visual editor or JSON definition.
- Save and activate the pipeline to start its execution.
Remember that AWS Data Pipeline is a serverless service, so you don’t need to worry about installation or infrastructure management. Just configure your pipeline using the AWS Management Console or API, and AWS will take care of the underlying resources required for its execution.
Basic Tutorials of AWS Data Pipeline: Getting Started
Before we dive into the tutorials, let’s first go over the basics of AWS Data Pipeline.

Creating a Pipeline
The first step in using AWS Data Pipeline is to create a pipeline. To do this, navigate to the AWS Management Console and select “Data Pipeline” from the list of services. From here, click on the “Create Pipeline” button and follow the prompts to create your pipeline.
Defining Activities
Once you’ve created your pipeline, the next step is to define the activities that will be performed in your pipeline. This can include activities such as copying data from one location to another, transforming data, or running scripts.
To define your activities, click on the “Add Activity” button in your pipeline definition. From here, you can select the type of activity you want to perform and configure it accordingly.
Setting up Scheduling
After defining your activities, the next step is to set up scheduling for your pipeline. This will determine when your pipeline runs and how often it runs.
To set up scheduling, navigate to the “Schedule” tab in your pipeline definition and configure the scheduling options according to your needs.
Monitoring Your Pipeline
Once your pipeline is up and running, it’s important to monitor it to ensure that everything is running smoothly. AWS Data Pipeline provides several tools for monitoring your pipeline, including the ability to view pipeline logs, metrics, and notifications.
To monitor your pipeline, navigate to the “Monitoring” tab in your pipeline definition. From here, you can view pipeline logs, performance metrics, and set up notifications for pipeline events.
Tutorials
Now that we’ve gone over the basics of AWS Data Pipeline, let’s dive into some tutorials that cover how to use AWS Data Pipeline in more detail.
Tutorial 1: Copying Data from S3 to Redshift
In this tutorial, we’ll walk through how to use AWS Data Pipeline to copy data from an S3 bucket to a Redshift cluster.
- Create a new pipeline in AWS Data Pipeline.
- Define an S3 data node as the source and a Redshift data node as the destination.
- Define a copy activity to copy the data from S3 to Redshift.
- Set up scheduling for the pipeline to run on a regular basis.
Tutorial 2: Transforming Data with EMR
In this tutorial, we’ll walk through how to use AWS Data Pipeline to transform data using EMR.
- Create a new pipeline in AWS Data Pipeline.
- Define an S3 data node as the source and a Redshift data node as the destination.
- Define an EMR activity to transform the data.
- Set up scheduling for the pipeline to run on a regular basis.
Tutorial 3: Running Scripts with Lambda
In this tutorial, we’ll walk through how to use AWS Data Pipeline to run scripts using Lambda.
- Create a new pipeline in AWS Data Pipeline.
- Define an S3 data node as the source and a Redshift data node as the destination.
- Define a Lambda activity to run a script.
- Set up scheduling for the pipeline to run on a regular basis.
Conclusion
AWS Data Pipeline is an incredibly powerful tool for managing and processing data. With AWS Data Pipeline, you can automate the movement and transformation of your data, making it easy to manage and process large amounts of data. We hope these step-by-step tutorials have provided you with the knowledge and skills to start using AWS Data Pipeline in your own projects. Happy data processing!

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
