What are Big Data Processing Tools?
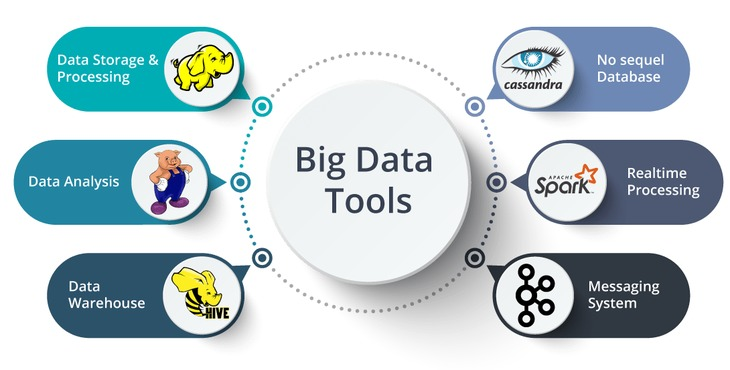
Big Data Processing Tools are software frameworks and platforms designed to handle and process large volumes of data efficiently. These tools are crucial for managing and analyzing massive datasets that exceed the processing capabilities of traditional data processing systems. They enable organizations to extract valuable insights, perform real-time analytics, and make data-driven decisions at scale.
Top 10 use cases of Big Data Processing Tools:
- Real-time Analytics: Processing and analyzing data streams in real-time to derive actionable insights.
- Batch Processing: Performing large-scale batch processing on massive datasets to extract patterns and trends.
- Data Warehousing: Storing and querying vast amounts of structured and unstructured data for business intelligence and analytics.
- Machine Learning: Training machine learning models on large datasets for predictive analysis and pattern recognition.
- Log Analytics: Analyzing log data from applications, servers, and devices to monitor and troubleshoot issues.
- Fraud Detection: Identifying anomalies and patterns in large datasets to detect fraudulent activities.
- Recommendation Systems: Building personalized recommendation systems based on user behavior and preferences.
- Internet of Things (IoT) Data Processing: Handling and analyzing data generated by IoT devices and sensors.
- Clickstream Analysis: Analyzing user clickstream data to optimize user experiences and marketing strategies.
- Genomics and Bioinformatics: Processing and analyzing genomic data for medical research and precision medicine.
What are the feature of Big Data Processing Tools?
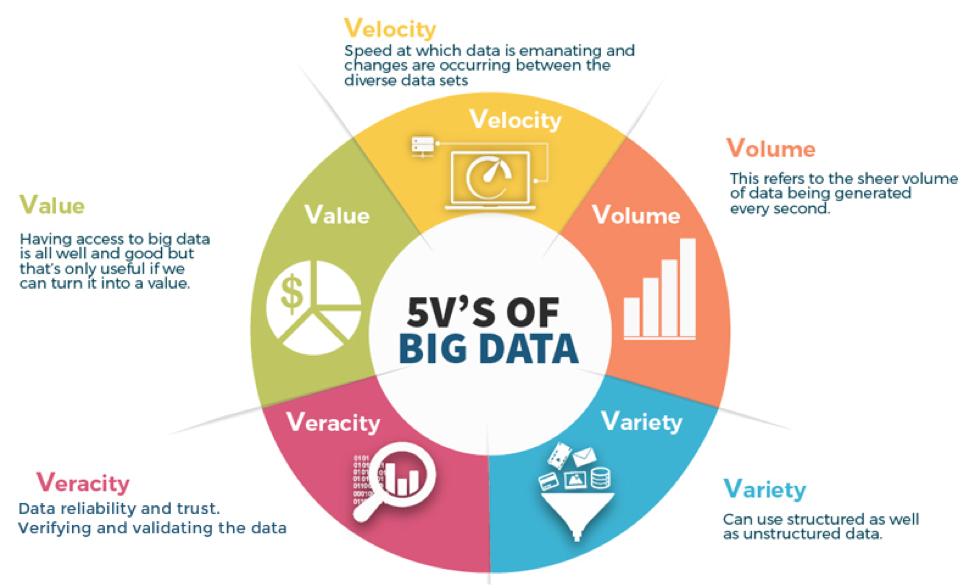
- Distributed Computing: Big Data Processing Tools distribute data and computation across multiple nodes or clusters to achieve scalability.
- Fault Tolerance: They provide mechanisms to handle node failures and ensure data integrity.
- Parallel Processing: Tools leverage parallel processing techniques to speed up data processing tasks.
- Data Replication: Data replication ensures data availability and resilience.
- Data Partitioning: Tools partition data for efficient processing and distribution across the cluster.
- Data Compression: Compression techniques reduce storage and transmission overhead.
How Big Data Processing Tools Work and Architecture?
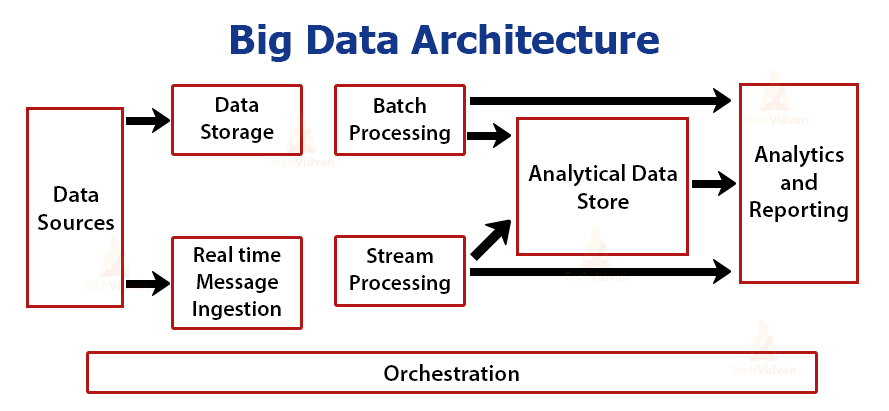
The architecture of Big Data Processing Tools is based on distributed computing principles. Generally, they involve the following components:
- Data Sources: Data is ingested from various sources, such as data lakes, databases, streaming platforms, or IoT devices.
- Data Ingestion: Data is ingested into the Big Data Processing Tool using connectors or APIs.
- Data Storage: Data is stored in distributed storage systems, like Hadoop Distributed File System (HDFS) or cloud storage.
- Processing Engine: The processing engine is responsible for executing data processing tasks.
- Distributed Computation: Data processing tasks are distributed across multiple nodes in a cluster for parallel execution.
- Data Processing: Data processing tasks, such as batch processing or stream processing, are performed on the data.
- Data Transformation: Data may undergo transformations like data cleaning, enrichment, or aggregation.
- Data Output: Processed data is stored or sent to downstream applications for analysis or consumption.
How to Install Big Data Processing Tools?
The installation process for Big Data Processing Tools depends on the specific tool or framework you want to use. Some popular Big Data Processing Tools include:
- Apache Hadoop: Download the Apache Hadoop distribution from the Apache Hadoop website (hadoop.apache.org) and follow the installation instructions.
- Apache Spark: Download the Apache Spark distribution from the Apache Spark website (spark.apache.org) and follow the installation instructions.
- Apache Flink: Download the Apache Flink distribution from the Apache Flink website (flink.apache.org) and follow the installation instructions.
Please visit the official websites of the respective Big Data Processing Tools for detailed and up-to-date installation instructions specific to each tool or framework.
Basic Tutorials of Big Data Processing Tools: Getting Started
Sure! Let’s provide step-by-step basic tutorials for three popular Big Data Processing Tools: Apache Hadoop, Apache Spark, and Apache Flink.

Big Data Processing Tool: Apache Hadoop
- Install Apache Hadoop:
- Download the Apache Hadoop distribution from the Apache Hadoop website (hadoop.apache.org).
- Extract the downloaded archive to a folder on your machine.
2. Configure Hadoop:
- Set up the Hadoop configuration files, including core-site.xml, hdfs-site.xml, and yarn-site.xml.
3. Start Hadoop Cluster:
- Start the Hadoop daemons by running the command
start-dfs.shto start HDFS andstart-yarn.shto start YARN.
4. Upload Data to HDFS:
- Use the
hdfs dfscommands to upload your data to HDFS (e.g.,hdfs dfs -put <local-path> <hdfs-path>).
5. Write MapReduce Job:
- Create a simple MapReduce job (e.g., Word Count) using Java, and compile it into a JAR file.
6. Run MapReduce Job:
- Submit the MapReduce job to Hadoop by running the command
hadoop jar <jar-file> <input-path> <output-path>.
7. Monitor Job Execution:
- Monitor the MapReduce job progress using the Hadoop JobTracker web interface or command-line tools.
Big Data Processing Tool: Apache Spark
- Install Apache Spark:
- Download the Apache Spark distribution from the Apache Spark website (spark.apache.org).
- Extract the downloaded archive to a folder on your machine.
2. Start Spark Cluster:
- Start a Spark cluster in standalone mode using the command
start-all.sh.
3. Run Spark Shell:
- Launch the Spark shell using
spark-shellfor Scala orpysparkfor Python.
4. Load Data and Create RDDs:
- Load data from a file or create an RDD (Resilient Distributed Dataset) using Spark API.
5. Transform and Process Data:
- Perform data transformations and processing on the RDD using Spark transformations (e.g., map, filter, reduce).
6. Run Spark Jobs:
- Create and run Spark jobs by chaining transformations and actions.
7. Stop Spark Cluster:
- Stop the Spark cluster using the command
stop-all.sh.
Big Data Processing Tool: Apache Flink
- Install Apache Flink:
- Download the Apache Flink distribution from the Apache Flink website (flink.apache.org).
- Extract the downloaded archive to a folder on your machine.
2. Start Flink Cluster:
- Start a Flink cluster in standalone mode using the command
start-cluster.sh.
3. Write Flink Job:
- Create a simple Flink job (e.g., Word Count) using Java or Scala, and compile it into a JAR file.
4. Submit Flink Job:
- Submit the Flink job to the cluster using the command
flink run <jar-file>.
5. Monitor Job Execution:
- Monitor the Flink job progress and statistics using the Flink web dashboard.
6. Stop Flink Cluster:
- Stop the Flink cluster using the command
stop-cluster.sh.
These step-by-step tutorials will help you get started with these popular Big Data Processing Tools. As you become more familiar with each tool, you can explore more advanced features and perform more complex data processing tasks.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
