What is Databricks?

Databricks is a cloud-based platform for big data analytics and machine learning. It’s like a Swiss army knife for data scientists and engineers, offering a wide range of tools and features to make their lives easier. Databricks is built on top of Apache Spark and offers managed services for data processing, analytics, and machine learning, making it easier for organizations to extract insights from their data.
Top 10 use cases of Databricks:
Here are the top 10 use cases of Databricks:
- Data Exploration and Analysis: Databricks allows users to perform exploratory data analysis on large datasets, enabling data scientists and analysts to gain insights and identify patterns.
- Data Processing: Organizations can use Databricks to process and transform raw and unstructured data into usable formats, making it suitable for ETL (Extract, Transform, Load) processes.
- Data Warehousing: Databricks can serve as a data warehouse solution, allowing businesses to store and query large amounts of structured and semi-structured data.
- Machine Learning and AI: Databricks provides an environment for building, training, and deploying machine learning models. It supports popular libraries like TensorFlow, PyTorch, and scikit-learn.
- Real-time Analytics: Organizations can use Databricks for real-time analytics by processing and analyzing streaming data from various sources.
- Data Pipelines: Databricks can be used to create and manage complex data pipelines, orchestrating data transformations, enrichments, and processing steps.
- Predictive Analytics: By leveraging machine learning capabilities, Databricks can help organizations make predictions and forecasts based on historical data.
- Collaborative Work: Databricks provides a collaborative environment where data scientists, data engineers, and analysts can work together on the same platform.
- Interactive Data Exploration: Databricks notebooks allow users to combine code, queries, visualizations, and narrative explanations in an interactive and shareable format.
- Fraud Detection: Databricks can be used for fraud detection by analyzing large volumes of transaction data and identifying anomalous patterns.
- Customer Analytics: Organizations can leverage Databricks to analyze customer behavior, preferences, and engagement patterns, enabling targeted marketing and personalized experiences.
- Optimizing Business Processes: Databricks can be used to optimize and automate business processes by analyzing data to identify bottlenecks, inefficiencies, and areas for improvement.
Databricks’ ability to handle large-scale data processing, its integration with various data sources and cloud services, and its support for machine learning make it a versatile platform for organizations looking to extract valuable insights and drive informed decision-making from their data.
What are the feature of Databricks?
- Unified Platform: Databricks offers a unified environment for data engineering, data science, and business analytics, allowing teams to collaborate seamlessly.
- Apache Spark Integration: Databricks is built on top of Apache Spark, a powerful open-source data processing framework, providing high-performance data processing and analytics capabilities.
- Managed Services: Databricks provides managed services, including automated cluster management, scaling, and monitoring, freeing users from the complexities of infrastructure management.
- Collaborative Notebooks: Databricks notebooks allow users to write and execute code, visualize data, and add narrative text, enabling interactive and shareable data analysis.
- Data Processing: Databricks supports batch and real-time data processing, enabling the handling of large-scale data transformations and analyses.
- Machine Learning Libraries: The platform supports popular machine learning libraries like TensorFlow, PyTorch, scikit-learn, and MLlib, enabling the creation of predictive models.
- Streaming Analytics: Databricks supports processing and analyzing streaming data from various sources, enabling real-time analytics and insights.
- Data Visualization: Databricks allows users to create visualizations and dashboards to represent data patterns, trends, and insights.
- Data Access: Databricks supports integration with various data sources, data lakes, and cloud storage solutions, making it easy to access and process diverse data.
- Security and Compliance: Databricks provides robust security features, including data encryption, role-based access control, and compliance certifications.
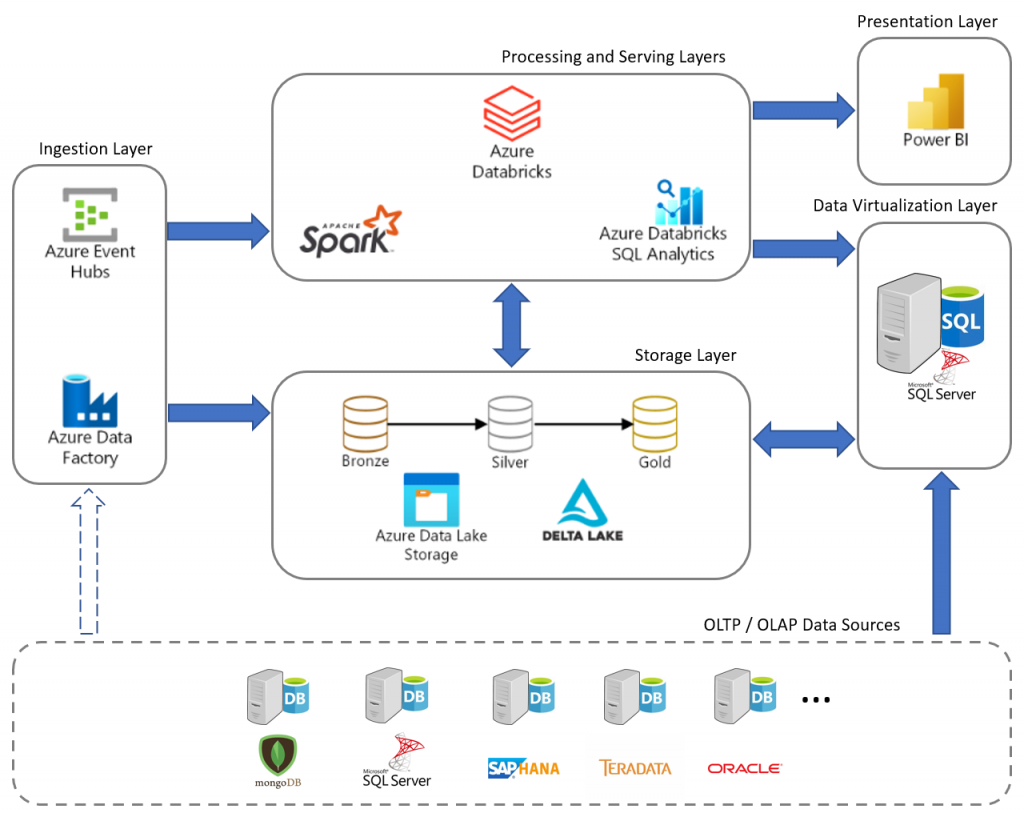
How Databricks Works and Architecture?
1. Databricks Workspace:
Databricks provides a web-based workspace where users can manage clusters, notebooks, and data. The workspace is accessible through a web browser.
2. Notebooks: Users create notebooks, which are interactive documents containing code, queries, visualizations, and explanatory text. Notebooks are organized into a hierarchical structure.
3. Clusters: A cluster is a computational environment that consists of virtual machines (VMs) used for processing data. Users can create and manage clusters based on their processing needs.
4. Execution and Jobs:
When a user runs a cell (code or query) within a notebook, the code is sent to the cluster for execution. The results and output are displayed within the notebook.
5. Libraries: Databricks supports installing and managing libraries and packages required for data processing and analysis, including machine learning libraries.
6. Databricks Runtime: Databricks Runtime is an optimized version of Apache Spark that comes preconfigured with performance optimizations and libraries for various tasks.
7. Integration: Databricks can integrate with various data sources, cloud storage, and other services, enabling access to data and resources across the organization.
8. Collaborative Work: Multiple users can collaborate on the same notebooks and clusters, enabling teamwork and sharing of insights.
9. Data Storage: Databricks can store data within its platform, integrate with external data lakes, or connect to cloud-based storage solutions.
10. Streaming and Batch Processing: Databricks supports both real-time streaming data processing and batch processing, providing flexibility for different use cases.
11. Serverless Mode: Databricks offers a serverless mode that automatically handles resource provisioning, allowing users to focus on analysis without worrying about cluster management.
12. Security: Databricks provides security features such as data encryption, authentication, role-based access control, and integration with identity providers.
13. Autoscaling: Clusters can be configured for autoscaling, meaning they automatically adjust the number of VMs based on workload demands.
Databricks’ architecture is designed to provide an efficient and collaborative environment for data processing, analysis, and machine learning. Its integration with Apache Spark, managed services, and support for various data sources make it a powerful platform for handling diverse data processing tasks.
How to Install Databricks?
There are two ways to install Databricks:
- Using the Databricks CLI
The Databricks CLI is a command-line tool that you can use to manage your Databricks workspace. To install the Databricks CLI, you need to have Python installed on your machine. Once you have Python installed, you can install the Databricks CLI by running the following command:
pip install databricks-cliOnce the Databricks CLI is installed, you can use it to create and manage Databricks clusters, run notebooks, and manage jobs.
- Using the Databricks Runtime
The Databricks Runtime is a pre-configured Docker image that you can use to run Databricks notebooks. To install the Databricks Runtime, you need to have Docker installed on your machine. Once you have Docker installed, you can install the Databricks Runtime by running the following command:
docker pull databricks/databricks-runtime:latestOnce the Databricks Runtime is installed, you can use it to run notebooks by mounting a local directory to the Docker container.
Here are the detailed steps on how to install Databricks using the Databricks CLI and the Databricks Runtime:
Installing Databricks using the Databricks CLI
- Install Python on your machine.
- Install the Databricks CLI by running the following command:
pip install databricks-cli- Create a Databricks account and get your personal access token.
- Configure the Databricks CLI by running the following command:
databricks configure --token <your-personal-access-token>Code language: HTML, XML (xml)- Create a Databricks cluster by running the following command:
databricks cluster create- Run a notebook by running the following command:
databricks notebook run <notebook-path>Code language: HTML, XML (xml)Installing Databricks using the Databricks Runtime
- Install Docker on your machine.
- Install the Databricks Runtime by running the following command:
docker pull databricks/databricks-runtime:latest- Create a directory to store your notebooks.
- Mount the directory to the Docker container by running the following command:
docker run -it -v :/dbfs/databricks/user/ databricks/databricks-runtime:latest
- Open a Jupyter notebook in the Docker container by running the following command:
jupyter notebookBasic Tutorials of Databricks: Getting Started

The following steps are the basic outline of Databricks:
- Create a Databricks account
To create a Databricks account, go to the Databricks website: https://databricks.com/. Hit the Sign up button and apply the live-screen instructions.
- Create a Databricks workspace
Once you have created a Databricks account, you will need to create a workspace. A workspace is a collection of resources, such as clusters, notebooks, and libraries, that you can use to run your data science projects. To create a workspace, click the Create workspace button and follow the on-screen instructions.
- Create a Databricks cluster
A cluster is a group of machines that are used to run your data science workloads. To create a cluster, click the Create cluster button and follow the on-screen instructions.
- Run a Databricks notebook
A notebook is a document that contains code, text, and visualizations. To run a notebook, click the Run button in the toolbar.
- Connect to a data source
Databricks can connect to a variety of data sources, such as databases, files, and cloud storage. To connect to a data source, click the Data tab and select the type of data source you want to connect to.
- Run a data analysis
Once you have connected to a data source, you can run data analysis using Databricks’ built-in tools and libraries.
- Share your work
You can share your work with others by publishing it to a Databricks repository. A repository is a collection of notebooks, libraries, and other artifacts that you can share with others.
Here are some additional tips for using Databricks:
- Use the Databricks documentation to learn more about the platform.
- Join the Databricks community to get help and support from other users.
- Attend Databricks training to learn how to use the platform more effectively.
Databricks Workflows
Databricks Workflows is a managed orchestration service that allows users to schedule and orchestrate data processing tasks on the Databricks platform. It provides tools for creating, managing, and monitoring complex data pipelines and workflows.
Key features of Databricks Workflows include:
- Jobs and Tasks: Jobs are the primary unit for scheduling and orchestrating workloads. They consist of one or more tasks, which can be notebooks, JAR files, Python scripts, SQL queries, or even other jobs[5][11].
- Flexible Task Types: Workflows support various task types, including Spark jobs, Delta Live Tables pipelines, SQL queries, and machine learning tasks[13].
- Scheduling and Triggers: Jobs can be scheduled to run at specific times or triggered by events like data arrivals[1].
- Dependency Management: Tasks within a job can be configured to run in sequence or parallel, with the ability to specify dependencies between tasks[8].
- Observability: Workflows provide deep monitoring capabilities, allowing users to track the progress and performance of their jobs and tasks[13].
- Integration with Databricks Platform: Workflows are tightly integrated with other Databricks features like Delta Lake, MLflow, and Databricks SQL[5].
Key Databricks Terminology
- Workspace: A web-based interface for creating data science and machine learning workflows, containing runnable commands, visualizations, and narrative text[3].
- Cluster: A set of computation resources and configurations on which jobs, notebooks, and queries run[3].
- Notebook: An interactive document that combines code execution, visualizations, and narrative text[3].
- Delta Lake: An open-source storage layer that brings reliability to data lakes, providing ACID transactions and unifying streaming and batch data processing[7].
- Delta Live Tables (DLT): A declarative framework for building reliable, maintainable, and testable data processing pipelines[7].
- Databricks Runtime: The set of core components that run on clusters managed by Databricks, including an optimized version of Apache Spark[10].
- DBFS (Databricks File System): A distributed file system mounted into Databricks clusters and objects stores[10].
- Databricks SQL: A set of features for executing SQL queries against datasets and visualizing results[10].
- Databricks Unit (DBU): A normalized unit of processing power used for measurement and pricing purposes[3].
- Data Lakehouse: A data management system that combines the benefits of data lakes and data warehouses, providing scalable storage and processing capabilities for various workloads[7].
By understanding these key concepts and features of Databricks Workflows and terminology, data professionals can effectively leverage the Databricks platform to build, manage, and optimize their data pipelines and analytics workflows.
Databricks architecture consists of two main components: the Control Plane and the Data Plane (also called Compute Plane). Here’s an overview of these components and other key elements of the Databricks platform:
Control Plane
The Control Plane houses Databricks’ back-end services and is managed by Databricks in their cloud account. It includes:
- Web application interface
- Compute orchestration
- Unity Catalog for governance
- Queries and code execution
Data Plane (Compute Plane)
The Data Plane is where data processing occurs and is typically hosted in the customer’s cloud account. It has two categories:
- Classic Compute Plane: User-managed clusters in the customer’s cloud environment
- Serverless Compute Plane: Managed compute resources provided by Databricks
Key Components
Workspace
- Centralized environment for collaboration
- Contains notebooks, clusters, jobs, and data assets
Clusters
- Sets of computation resources for running jobs and notebooks
- Can be managed or serverless
Databricks Runtime
- Core components running on Databricks-managed clusters
- Includes optimized Apache Spark and additional libraries
Delta Lake
- Open-source storage layer for reliability in data lakes
- Provides ACID transactions and unifies streaming and batch processing
Unity Catalog
- Unified governance solution for data and AI assets
- Offers centralized access control, auditing, and data discovery
DBFS (Databricks File System)
- Distributed file system mounted into Databricks clusters
Databricks SQL
- Features for executing SQL queries and visualizing results
Workflows
- Managed orchestration service for scheduling and managing data pipelines
MLflow
- Platform for managing the machine learning lifecycle
By leveraging these components, Databricks provides a comprehensive platform for data engineering, analytics, and machine learning workloads in a unified environment.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
