What is Elasticsearch?

Elasticsearch is an open-source, distributed search and analytics engine built on top of Apache Lucene. It provides a powerful and scalable solution for searching, analyzing, and visualizing large volumes of data in near real-time. Elasticsearch is often used in conjunction with the ELK (Elasticsearch, Logstash, and Kibana) stack for log and event data analysis.
What is top use cases of Elasticsearch?
Top Use Cases of Elasticsearch:
- Search Engine:
- Elasticsearch is widely used as a search engine for websites, applications, and content management systems. It enables fast and relevant full-text search capabilities, making it suitable for e-commerce platforms, news websites, and document repositories.
- Log and Event Data Analysis:
- Elasticsearch is a popular choice for analyzing log and event data from applications, servers, and infrastructure. It allows organizations to index, search, and visualize logs in real-time, helping in debugging, monitoring, and troubleshooting.
- Business Intelligence and Analytics:
- Elasticsearch is used in business intelligence and analytics applications to provide a fast and scalable solution for exploring and visualizing large datasets. It supports aggregations, filtering, and complex queries for data analysis.
- Security Information and Event Management (SIEM):
- SIEM platforms leverage Elasticsearch to centralize and analyze security-related log and event data. It helps organizations detect and respond to security incidents by providing real-time insights into network activities, user behavior, and potential threats.
- Application Performance Monitoring (APM):
- Elasticsearch is integrated into APM tools to store and analyze performance metrics, traces, and logs from applications. It assists in identifying bottlenecks, optimizing performance, and troubleshooting issues in complex distributed systems.
- Geospatial Data Analysis:
- Elasticsearch supports geospatial data analysis, making it suitable for applications that involve location-based queries and mapping. This use case is applicable in scenarios such as store locators, geospatial analytics, and geographic information systems (GIS).
- Content Recommendation Systems:
- Elasticsearch is employed in content recommendation systems, helping organizations deliver personalized recommendations to users based on their preferences and behavior. It supports collaborative filtering and content-based recommendations.
- Document and Text Retrieval:
- Organizations use Elasticsearch to build systems for document retrieval and text analysis. It is valuable in legal, academic, and research domains for efficiently searching and retrieving relevant documents.
- E-commerce Product Search:
- Elasticsearch is commonly used in e-commerce platforms for product search and recommendation. Its ability to handle complex queries and filter options provides a seamless and fast search experience for users.
- Healthcare Data Management:
- In the healthcare industry, Elasticsearch is used to manage and analyze patient records, medical histories, and clinical data. It supports efficient search and retrieval of healthcare-related information.
- Monitoring and Alerting:
- Elasticsearch is integrated with monitoring and alerting systems to collect and analyze data from various sources. This use case is crucial for maintaining system health, identifying anomalies, and triggering alerts.
- Social Media Analysis:
- Social media platforms use Elasticsearch for analyzing and searching vast amounts of user-generated content. It facilitates sentiment analysis, trend identification, and searching for relevant topics.
- Inventory and Catalog Management:
- Elasticsearch is employed in inventory and catalog management systems for efficient product search, filtering, and inventory tracking. It enables users to quickly find products based on various attributes.
- Fraud Detection:
- Elasticsearch is utilized in fraud detection systems to analyze transaction data, user behavior, and patterns. It helps identify potential fraudulent activities in real-time.
- Graph Data Analysis:
- With the introduction of the Graph API, Elasticsearch supports graph data analysis. It is used in scenarios where relationships between entities need to be analyzed, such as social network analysis or fraud detection.
Elasticsearch’s versatility, scalability, and real-time capabilities make it a valuable tool across various industries and use cases for efficiently handling and analyzing large volumes of data.
What are feature of Elasticsearch?
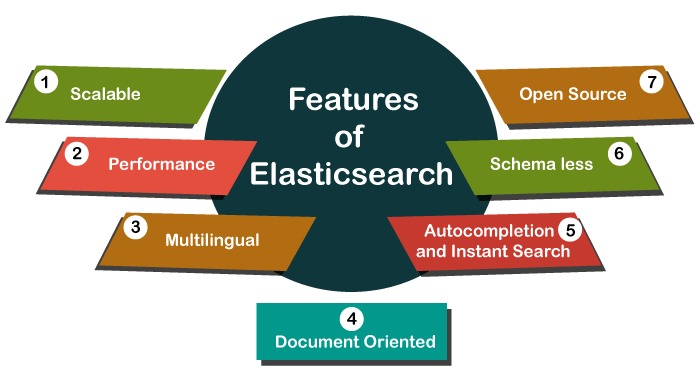
Features of Elasticsearch:
- Distributed and Scalable:
- Elasticsearch is designed to be distributed, allowing data to be distributed across multiple nodes in a cluster. This ensures scalability, high availability, and the ability to handle large amounts of data.
- Full-Text Search:
- Elasticsearch provides powerful full-text search capabilities based on the Apache Lucene search engine. It supports complex queries, relevance scoring, and fuzzy matching, making it suitable for various search applications.
- Real-Time Search:
- Elasticsearch provides near real-time search capabilities. As documents are indexed, they become searchable almost immediately, making it suitable for applications that require up-to-date information.
- RESTful API:
- Elasticsearch exposes a RESTful API, making it easy to interact with the system using standard HTTP methods. This simplifies integration with various programming languages and frameworks.
- Schema-Free JSON Documents:
- Elasticsearch is schema-free, allowing users to index and search JSON documents without the need for a predefined schema. This flexibility is beneficial in dynamic and evolving data environments.
- Document-Oriented:
- Data in Elasticsearch is stored as JSON documents. Each document represents a record with associated fields, and these documents are stored and indexed for efficient search and retrieval.
- Multi-Tenancy:
- Elasticsearch supports multi-tenancy, enabling multiple indices and document types within a cluster. This is useful for scenarios where different applications or teams need to use the same Elasticsearch cluster.
- Aggregations:
- Aggregations in Elasticsearch allow users to perform analytics on data, such as computing sums, averages, and other metrics. This feature is valuable for business intelligence and data analysis.
- GeoSpatial Search:
- Elasticsearch supports geospatial data types and queries, making it suitable for location-based search and analytics. It can be used for applications involving mapping and geographic information systems (GIS).
- Indexing and Replication:
- Elasticsearch allows users to index large volumes of data and replicate it across nodes for redundancy and fault tolerance. Indexing is the process of adding documents to Elasticsearch for search and retrieval.
- Security:
- Elasticsearch provides security features such as role-based access control (RBAC), authentication, and encryption. This ensures that access to the data and cluster is restricted to authorized users.
- Bulk Operations:
- Users can perform bulk operations in Elasticsearch, allowing them to index, update, or delete multiple documents in a single request. This is efficient for managing large datasets.
- Scoring and Relevance:
- Elasticsearch calculates relevance scores for search results based on factors such as term frequency and inverse document frequency. This helps in returning the most relevant results for a given query.
- Cross-Cluster Search:
- Elasticsearch supports cross-cluster search, enabling users to search across multiple clusters. This is beneficial in scenarios where data is distributed across different geographical locations.
- Snapshot and Restore:
- Elasticsearch provides snapshot and restore functionality, allowing users to take snapshots of indices and restore them if needed. This is crucial for backup and disaster recovery.
What is the workflow of Elasticsearch?
Workflow of Elasticsearch:
- Index Creation:
- Start by creating an index, which is a logical namespace that maps to one or more physical shards. Shards are the basic building blocks of an index and are distributed across nodes in a cluster.
- Document Indexing:
- Index documents by sending JSON data to Elasticsearch. Each document represents a record and is associated with a unique identifier (usually the document ID). Elasticsearch automatically indexes and stores the documents.
- Searching:
- Use the RESTful API to perform searches on the indexed data. Users can construct queries using the Query DSL (Domain-Specific Language) to retrieve relevant documents based on specific criteria.
- Aggregations:
- Utilize aggregations to perform analytics on the data. Aggregations allow users to compute metrics, group data, and generate insights from the indexed documents.
- Scaling and Distribution:
- As data grows, scale the Elasticsearch cluster horizontally by adding more nodes. Elasticsearch automatically distributes data across nodes for load balancing and fault tolerance.
- Cluster Monitoring:
- Monitor the health and performance of the Elasticsearch cluster. Elasticsearch provides APIs and tools for monitoring cluster status, node statistics, and index health.
- Security Configuration:
- Configure security settings such as role-based access control (RBAC), authentication mechanisms, and encryption to ensure that the Elasticsearch cluster is secure.
- Backup and Restore:
- Implement snapshot and restore procedures to create backups of indices. This ensures that data can be restored in case of accidental deletion or cluster failures.
- Cross-Cluster Search:
- Configure cross-cluster search if needed. This allows users to search and retrieve data from multiple Elasticsearch clusters.
- Optimization and Tuning:
- Continuously optimize and tune the Elasticsearch cluster for performance. This may involve adjusting settings, mappings, and configurations based on the evolving needs of the application.
- Security Updates:
- Keep the Elasticsearch cluster and its dependencies up to date with the latest security patches and updates to address potential vulnerabilities.
Understanding the workflow of Elasticsearch involves creating indices, indexing documents, searching and analyzing data, and managing the cluster to ensure optimal performance, scalability, and security.
How Elasticsearch Works & Architecture?
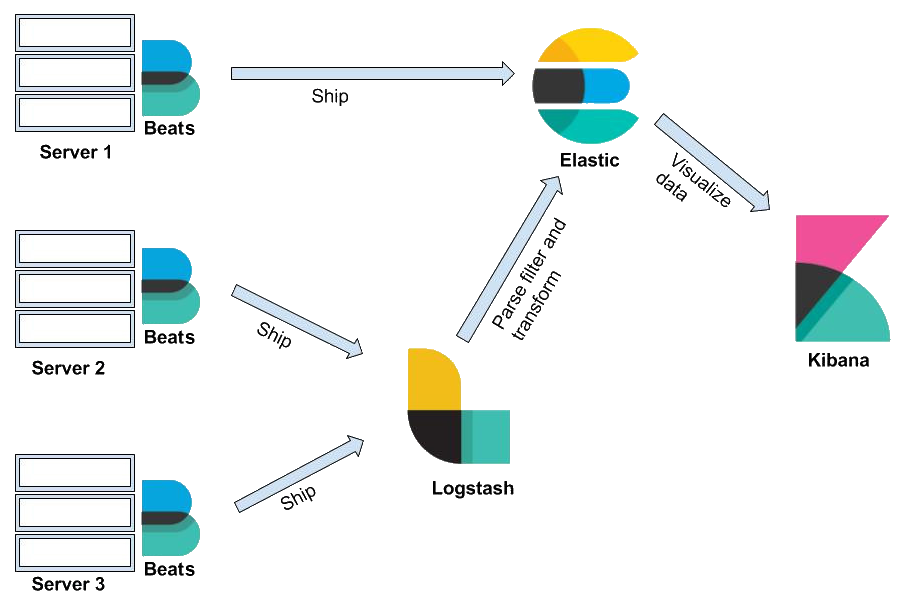
Elasticsearch is a powerful, open-source search and analytics engine built on top of Apache Lucene, a robust indexing and search library. It excels at processing data quickly and efficiently, particularly large and complex datasets, making it a popular choice for building search-driven applications, log analysis, and data visualization.
How it Works:
- Data Ingestion: Data enters Elasticsearch through various sources, like logs, databases, APIs, or directly from applications. Shipping tools like Beats send data for bulk indexing.
- Parsing and Normalization: Data is parsed and normalized to a consistent format, regardless of source. This ensures efficient indexing and searching.
- Tokenization and Analysis: Text is broken down into tokens (keywords) using linguistic analysis to understand synonyms, stemming, and other nuances.
- Indexing: Tokens are mapped to inverted indices, a data structure that maps words to documents containing those words. This enables fast text searches.
- Searching and Aggregations: Users submit queries, which are analyzed and matched against the inverted indices. Aggregations provide summaries and insights from the data.
- Results and Analytics: Searched documents and aggregated results are returned to the user, enabling insightful analysis and visualization.
Architecture:
Elasticsearch uses a distributed architecture for scalability and resilience:
- Clusters: Multiple nodes (servers) run Elasticsearch together, sharing workloads and data.
- Shards: Data is split into smaller units called shards, distributed across nodes for parallel processing and faster search.
- Replicas: Each shard has one or more replicas on other nodes, ensuring data availability in case of node failure.
- Master Node: One node acts as the master, coordinating cluster operations and shard allocation.
Key Benefits:
- Scalability: Handles large datasets with ease by adding more nodes to the cluster.
- Fault Tolerance: Replicas ensure data availability and service continuity even if nodes fail.
- Fast Search: Inverted indices enable lightning-fast text searches across your data.
- Relevance Ranking: Search results are ranked based on relevance to the query, improving user experience.
- Aggregations and Analytics: Extract valuable insights from data through powerful aggregation functions.
- Extensible: Integrates with various tools and frameworks for diverse applications.
Use Cases:
- Search-driven applications: Websites, e-commerce platforms, knowledge bases, etc.
- Log analysis and monitoring: Analyze application logs, system logs, and security logs for insights.
- Real-time analytics: Analyze streaming data or near real-time data for timely insights.
- Data visualization: Use search results and aggregations to power data visualizations with tools like Kibana.
With its robust architecture and capabilities, Elasticsearch is a powerful tool for anyone working with large amounts of data and needing fast, insightful search and analysis capabilities.
How to Install and Configure Elasticsearch?
Following is a guide on installing and configuring Elasticsearch:
Prerequisites:
- Java: Download and install Java 8 or later from Oracle’s website.
Installation Methods:
- Download and Extract:
- Get the latest Elasticsearch package from their official website.
- Extract the downloaded archive to a favored location.
- Package Manager (Recommended):
- Use a package manager like Homebrew (macOS) or apt-get (Ubuntu/Debian): Bash
# macOS (Homebrew) brew install elasticsearch # Ubuntu/Debian (apt-get) sudo apt-get install elasticsearch
- Use a package manager like Homebrew (macOS) or apt-get (Ubuntu/Debian): Bash
Running Elasticsearch:
- Navigate to the Elasticsearch directory: Bash
cd /path/to/elasticsearch - Start Elasticsearch: Bash
./bin/elasticsearch- If successful, you’ll see log messages indicating it’s running. Access it at
http://localhost:9200/in your browser.
- If successful, you’ll see log messages indicating it’s running. Access it at
Basic Configuration (Optional):
- Edit
config/elasticsearch.ymlfile:- Adjust cluster name, node name, network settings, memory allocation, etc.
Troubleshooting:
- Check logs for errors in
logs/elasticsearch.log. - Ensure no other processes are using port 9200.
- Review configuration settings for potential issues.
Additional Considerations:
- Production Environments:
- Use multiple nodes for scalability and fault tolerance.
- Configure security settings for production environments.
- Consider using tools like Kibana and Logstash for data visualization and ingestion.
Fundamental Tutorials of Elasticsearch: Getting started Step by Step

Following is a step-by-step fundamental tutorial on Elasticsearch, incorporating key concepts and hands-on examples:
1. Installation and Setup:
- Install Elasticsearch: Follow the instructions provided earlier for your operating system.
- Verify Installation: Start Elasticsearch and check if it’s running by accessing
http://localhost:9200/in your browser.
2. Using Postman or cURL:
- Install a REST client: Use Postman or cURL to interact with Elasticsearch’s REST API.
- Basic GET Request: Retrieve cluster information:
curl -X GET http://localhost:9200/
3. Creating an Index:
- An index is a collection of documents: Create one for your data:
Bash
curl -X PUT http://localhost:9200/my_index
4. Indexing a Document:
- Add a document to the index:
Bash
curl -X POST http://localhost:9200/my_index/_doc -H 'Content-Type: application/json' -d '{"name": "John Doe", "age": 30, "city": "New York"}'
5. Searching for Documents:
- Retrieve documents based on criteria:
Bash
curl -X GET http://localhost:9200/my_index/_search?q=name:John
6. Aggregations:
- Analyze and summarize data:
Bash
curl -X GET http://localhost:9200/my_index/_search?size=0&aggs={"age_buckets": {"terms": {"field": "age"}}
7. Deleting an Index:
- Remove an entire index:
Bash
curl -X DELETE http://localhost:9200/my_index
Additional Topics:
- Mapping: Define how data is stored and analyzed.
- Node and Cluster Management: Manage multiple nodes in a cluster.
- Data Ingestion: Use tools like Logstash or Beats to ingest data.
- Data Visualization: Use Kibana to create visualizations and dashboards.

👤 About the Author
Rahul is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps. Driven by a love for innovation and continuous improvement, Rahul enjoys helping engineers and organizations embrace automation, reliability, and intelligent IT operations. Connect with Rahul and stay up-to-date with the latest in tech!
🌐 Connect with Rahul
-
Website: MotoShare.in
-
Facebook: facebook.com/DevOpsSchool
-
X (Twitter): x.com/DevOpsSchools
-
LinkedIn: linkedin.com/company/devopsschool
-
YouTube: youtube.com/@TheDevOpsSchool
-
Instagram: instagram.com/devopsschool
-
Quora: devopsschool.quora.com
-
Email: contact@devopsschool.com
