What is Google Cloud Dataflow?

Google Cloud Dataflow is a fully managed data processing service provided by Google Cloud Platform. It allows you to design, deploy, and manage data processing pipelines for both batch and stream processing tasks. Dataflow offers a unified programming model that supports both batch processing (processing data in fixed-size chunks) and stream processing (processing data as it arrives).
Top 10 Use Cases of Google Cloud Dataflow:
- Real-Time Analytics: Perform real-time analytics on streaming data, extracting insights and patterns as data arrives.
- ETL (Extract, Transform, Load): Ingest, transform, and load data from various sources into a target data store for analysis.
- Data Enrichment: Enrich streaming or batch data with additional information from external sources, such as APIs or reference datasets.
- Fraud Detection: Analyze transaction data in real-time to detect fraudulent activities and anomalies.
- Clickstream Analysis: Analyze user clickstream data to gain insights into user behavior and website performance.
- Log Analysis and Monitoring: Process logs from applications, servers, and devices in real-time to identify issues and troubleshoot problems.
- IoT Data Processing: Process and analyze data from IoT devices, sensors, and connected devices in real-time.
- Recommendation Engines: Build recommendation systems that provide personalized recommendations to users based on their preferences and behavior.
- Market Basket Analysis: Analyze customer purchasing behavior to identify associations between products for cross-selling and upselling.
- Data Quality and Cleansing: Cleanse and validate data in real-time or in batches to ensure data quality and accuracy.
These use cases highlight the versatility of Google Cloud Dataflow in handling a wide range of data processing scenarios, whether they involve real-time streaming data or batch processing of large datasets. Dataflow’s ability to handle both modes of processing simplifies development and deployment for data engineering tasks.
What are the feature of Google Cloud Dataflow?
- Unified Model: Dataflow provides a unified programming model for both batch and stream processing, simplifying development and reducing code duplication.
- Auto-Scaling: Dataflow automatically scales up or down based on the processing requirements, ensuring optimal resource utilization and performance.
- Managed Service: It’s a fully managed service, which means Google handles infrastructure provisioning, monitoring, and maintenance.
- Windowing: For stream processing, Dataflow supports windowing, allowing you to group and analyze data within specific time intervals.
- Exactly-Once Processing: Dataflow offers exactly-once processing semantics, ensuring that data is processed reliably without duplication or loss.
- Integration: Seamlessly integrates with other Google Cloud services like BigQuery, Pub/Sub, Cloud Storage, and more.
- Flexible Sinks and Sources: Supports various data sources and sinks, making it easy to ingest and export data to/from different systems.
- Monitoring and Logging: Provides comprehensive monitoring, logging, and debugging tools to help you understand and optimize your data pipelines.
- Custom Transformations: You can create custom transformations and functions to perform complex data processing.
- Templates: Dataflow allows you to create reusable templates for common processing patterns, simplifying pipeline deployment.
How Google Cloud Dataflow Works and Architecture?
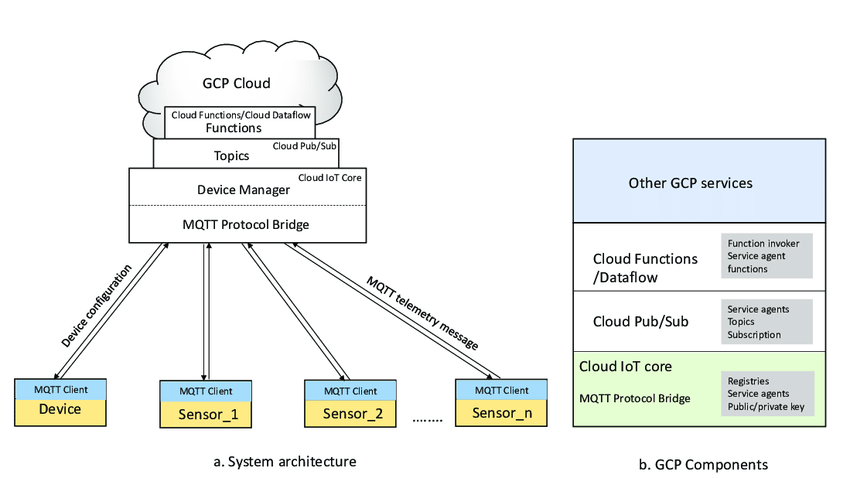
Google Cloud Dataflow processes data using a directed acyclic graph (DAG) of transformations. Here’s a clarified outline of how it works:
- Pipeline Definition: You define your data processing pipeline using the Dataflow SDK. This includes defining data sources, transformations, and data sinks.
- Distributed Execution: Dataflow takes the pipeline definition and dynamically optimizes and distributes the work across a cluster of virtual machines.
- Data Processing: Each element of input data goes through a series of transformations defined in the pipeline. Transformations can include mapping, filtering, aggregating, and more.
- Parallelism and Scaling: Dataflow automatically scales up or down based on the processing needs. It breaks down data into smaller chunks and processes them in parallel to achieve efficient processing.
- Windowing (Stream Processing): For stream processing, Dataflow supports windowing, allowing you to group data into time-based intervals for analysis.
- Data Sinks: Processed data is sent to defined data sinks, which can be storage systems like Google Cloud Storage, BigQuery, or external systems.
- Exactly-Once Processing: Dataflow ensures exactly-once processing by tracking the state of each element processed, making it resilient to failures.
- Optimization: Dataflow optimizes the execution plan to minimize data shuffling and optimize resource usage.
- Monitoring and Debugging: Dataflow provides tools for monitoring pipeline progress, performance, and identifying bottlenecks or errors.
Dataflow’s architecture abstracts much of the complexity of distributed data processing, allowing you to focus on defining your processing logic and transformations. Under the hood, it uses Google’s internal data processing technology to efficiently manage resources and deliver reliable processing capabilities.
How to Install Google Cloud Dataflow?
To install Google Cloud Dataflow, you will need to:
- Create a Google Cloud Platform project and enable the Dataflow API.
- Install the Apache Beam SDK for your programming language.
- Create a Cloud Storage bucket to store your data and output files.
- Write your Dataflow pipeline code.
- Submit your Dataflow pipeline to the Dataflow service.
Here are the detailed steps on how to install Google Cloud Dataflow:
- Create a Google Cloud Platform project and enable the Dataflow API.
- Open the Google Cloud Platform Console: https://console.cloud.google.com/.
- Click the Create Project button.
- Enter a project name and click the Create button.
- Click the APIs & Services tab.
- Search for “Dataflow” and click the Enable button.
2. Install the Apache Beam SDK for your programming language.
- The Apache Beam SDK is available for a variety of programming languages, including Java, Python, Go, and JavaScript.
- You can download the SDK for your programming language from the Apache Beam website: https://beam.apache.org/releases/.
3. Create a Cloud Storage bucket to store your data and output files.
- A Cloud Storage bucket is a place to store your data and output files.
- You can create a Cloud Storage bucket from the Cloud Storage Console: https://console.cloud.google.com/storage/.
4. Write your Dataflow pipeline code.
- Your Dataflow pipeline code is a program that describes how to process your data.
- You can write your Dataflow pipeline code in any programming language that supports the Apache Beam SDK.
- There are many examples of Dataflow pipeline code available online.
5. Submit your Dataflow pipeline to the Dataflow service.
- Once you have written your Dataflow pipeline code, you can submit it to the Dataflow service.
- To do this, you will need to use the gcloud command-line tool: https://cloud.google.com/sdk/gcloud/.
- For more information on how to submit a Dataflow pipeline, please see the Dataflow documentation: https://cloud.google.com/dataflow/docs/quickstarts/create-pipeline-java.
Basic Tutorials of Google Cloud Dataflow: Getting Started
Here are some step-by-step basic tutorials of Google Cloud Dataflow:

- Dataflow quickstart using Python: This tutorial shows you how to create a simple Dataflow pipeline using the Python SDK.
- Create a Google Cloud Platform project and enable the Dataflow API.
- Install the Apache Beam SDK for Python.
- Create a Cloud Storage bucket to store your data and output files.
- Write your Dataflow pipeline code.
- Submit your Dataflow pipeline to the Dataflow service.
- Here is an example of a simple Dataflow pipeline code in Python:
import apache_beam as beam
with beam.Pipeline() as pipeline:
(pipeline
| 'Read data' >> beam.io.ReadFromText('gs://my-bucket/my-data.txt')
| 'Count words' >> beam.Map(lambda line: len(line.split()))
| 'Write results' >> beam.io.WriteToText('gs://my-bucket/my-results.txt'))
pipeline.run()Code language: JavaScript (javascript)* This code reads the data from the file `gs://my-bucket/my-data.txt`, counts the number of words in each line, and writes the results to the file `gs://my-bucket/my-results.txt`.
* To run this code, you can use the following command:Code language: PHP (php)gcloud dataflow jobs run my-job --python-file my_pipeline.pyCode language: CSS (css)* This command will create a Dataflow job called `my-job` and run it using the Python pipeline code in the file `my_pipeline.py`.Code language: JavaScript (javascript)- Dataflow quickstart using Java: This tutorial shows you how to create a simple Dataflow pipeline using the Java SDK.
- The steps are similar to the Python tutorial, but the code is written in Java.
- Dataflow quickstart using Go: This tutorial shows you how to create a simple Dataflow pipeline using the Go SDK.
- The steps are similar to the Python tutorial, but the code is written in Go.
- Dataflow quickstart using a template: This tutorial shows you how to create a Dataflow pipeline using a template.
- A template is a pre-written Dataflow pipeline that you can use as a starting point for your own pipelines.
- To use a template, you need to first download the template from the Dataflow website.
- Once you have downloaded the template, you can edit it to customize it for your own needs.
- Finally, you can submit the template to the Dataflow service to run it.
- Dataflow with Cloud Pub/Sub: This tutorial shows you how to use Dataflow to process streaming data from Cloud Pub/Sub.
- Cloud Pub/Sub is a messaging service that can be used to send and receive streaming data.
- Dataflow can be used to process streaming data from Cloud Pub/Sub in real time.
- To use Dataflow with Cloud Pub/Sub, you need to first create a Cloud Pub/Sub topic.
- Once you have created a topic, you can send data to the topic using the Cloud Pub/Sub API.
- Dataflow can then be used to process the data from the topic in real time.
- Dataflow with BigQuery: This tutorial shows you how to use Dataflow to load data into BigQuery.
- BigQuery is a cloud data warehouse that can be applied to analyze and store huge amounts of data.
- Dataflow can be used to load data into BigQuery in a batch or streaming fashion.
- To use Dataflow with BigQuery, you need to first create a BigQuery dataset.
- Once you have created a dataset, you can use Dataflow to load data into the dataset.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
