What are Natural Language Processing (NLP) Libraries?

Natural Language Processing (NLP) Libraries are software tools and frameworks that provide a set of functionalities for processing and analyzing human language data. These libraries are designed to assist in various NLP tasks, such as text preprocessing, tokenization, part-of-speech tagging, named entity recognition, sentiment analysis, machine translation, language modeling, and more. NLP libraries abstract the complexity of language processing tasks, allowing developers and data scientists to focus on building NLP applications and models.
Top 10 use cases of Natural Language Processing (NLP) Libraries:
- Text Classification: Classifying text into predefined categories, such as spam detection, sentiment analysis, or topic categorization.
- Named Entity Recognition (NER): Identifying and extracting entities like names, locations, dates, and organizations from unstructured text.
- Sentiment Analysis: Determining the sentiment or emotion expressed in a piece of text, such as positive, negative, or neutral sentiment.
- Machine Translation: Translating text from one language to another automatically.
- Language Modeling: Predicting the probability of the next word in a sentence, useful for autocompletion and speech recognition.
- Information Extraction: Extracting structured information from unstructured text, such as extracting events or relationships from news articles.
- Question Answering: Building systems that can answer questions posed in natural language based on given context.
- Text Summarization: Automatically generating concise summaries from long documents or articles.
- Text Generation: Generating human-like text using language models, often seen in chatbots and virtual assistants.
- Speech Recognition: The computer matches the spoken words to its database of known words and phrases, and then converts them into text or commands.
What are the feature of Natural Language Processing (NLP) Libraries?
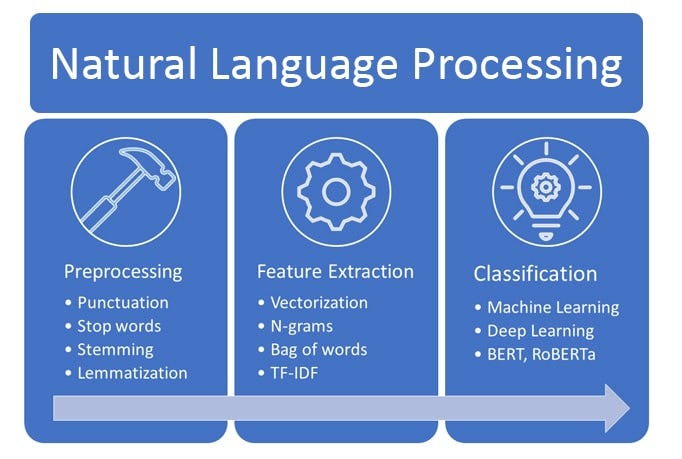
- Tokenization: Breaking text into individual words or tokens for further analysis.
- Part-of-Speech Tagging: Assigning grammatical labels (e.g., noun, verb, adjective) to each word in a sentence.
- Named Entity Recognition (NER): Identifying and categorizing named entities in text.
- Text Preprocessing: Cleaning and preparing text data for analysis, including removing stop words and punctuation.
- Sentiment Analysis: Analyzing and understanding the emotions and opinions expressed in text.
- Language Models: Providing language models for various NLP tasks, such as machine translation and text generation.
- Text Classification: Building and training classifiers to categorize text into predefined classes.
How Natural Language Processing (NLP) Libraries Work and Architecture?
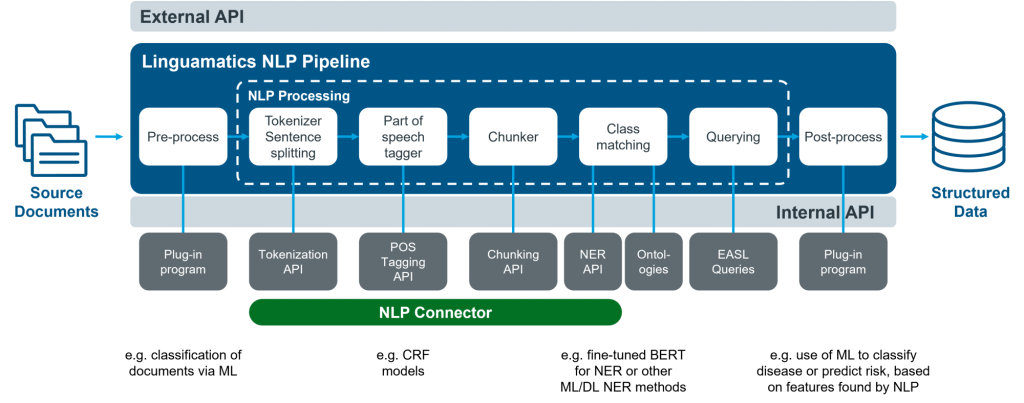
The architecture of NLP libraries can vary, but typically, they involve the following steps:
- Text Input: Input text is provided to the NLP library for processing.
- Tokenization: The library tokenizes the text into individual words or tokens.
- Text Preprocessing: The text is cleaned and preprocessed to remove noise and irrelevant information.
- NLP Tasks: The library performs specific NLP tasks, such as sentiment analysis, named entity recognition, or part-of-speech tagging.
- Output: The processed text or the results of the NLP task are returned as output.
How to Install Natural Language Processing (NLP) Libraries?
To install NLP libraries, you can use package managers like pip or conda, depending on the library you wish to use. Some popular NLP libraries include NLTK (Natural Language Toolkit), spaCy, TextBlob, Gensim, StanfordNLP, and Transformers (Hugging Face).
For example, to install NLTK using pip, you can use the following command:
pip install nltkFor spaCy, you can use:
pip install spacyFor TextBlob, you can use:
pip install textblobBefore installing an NLP library, ensure you have the required dependencies, such as language models and data resources, to support the library’s functionality.
Please refer to the official documentation and websites of the specific NLP library you wish to install for detailed and up-to-date installation instructions.
Basic Tutorials of Natural Language Processing (NLP) Libraries: Getting Started
Sure! Below are basic tutorials for getting started with Natural Language Processing (NLP) step-by-step: NLTK (Natural Language Toolkit) and spaCy.

Step-by-Step Basic Tutorial for NLP with NLTK:
- Install NLTK:
- Install the NLTK library using pip:
pip install nltk
- Import Libraries:
- Create a Python script (e.g.,
nlp_with_nltk.py) and import the NLTK library:
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
Code language: JavaScript (javascript)- Download NLTK Resources:
- Download the necessary NLTK resources (e.g., tokenizers, stopwords, etc.):
nltk.download('punkt')
nltk.download('stopwords')
Code language: JavaScript (javascript)- Tokenization and Sentence Splitting:
- Create Tokenize text into words and sentences:
text = "NLP (Natural Language Processing) is a subfield of artificial intelligence."
words = word_tokenize(text)
sentences = sent_tokenize(text)
print("Words:", words)
print("Sentences:", sentences)Code language: PHP (php)- Stopword Removal:
- Replace common stopwords from the text:
stop_words = set(stopwords.words("english"))
filtered_words = [word for word in words if word.lower() not in stop_words]
print("Filtered Words:", filtered_words)
Code language: PHP (php)- Stemming:
- Perform stemming to get the root form of words:
ps = PorterStemmer()
stemmed_words = [ps.stem(word) for word in filtered_words]
print("Stemmed Words:", stemmed_words)
Code language: PHP (php)Step-by-Step Basic Tutorial for NLP with spaCy:
- Install spaCy:
- Install the spaCy library using pip:
pip install spacy
- Download spaCy Language Model:
- Download the spaCy language model for the language you want to work with (e.g., English):
python -m spacy download en_core_web_sm
- Import Libraries:
- Create a Python script (e.g.,
nlp_with_spacy.py) and import the spaCy library:
import spacyCode language: JavaScript (javascript)- Load spaCy Language Model:
- Load the downloaded language model:
nlp = spacy.load('en_core_web_sm')Code language: JavaScript (javascript)- Tokenization and Sentence Splitting:
- Tokenize text into words and sentences using spaCy:
text = "NLP (Natural Language Processing) is a subfield of artificial
intelligence."
doc = nlp(text)
words = [token.text for token in doc]
sentences = [sent.text for sent in doc.sents]
print("Words:", words)
print("Sentences:", sentences)Code language: PHP (php)- Lemmatization:
- Perform lemmatization to get the base form (lemma) of words:
lemmatized_words = [token.lemma_ for token in doc]
print("Lemmatized Words:", lemmatized_words)Code language: PHP (php)- Part-of-Speech (POS) Tagging:
- Get the part-of-speech tags for each word in the text:
pos_tags = [(token.text, token.pos_) for token in doc]
print("POS Tags:", pos_tags)Code language: PHP (php)These tutorials will provide you with a foundational understanding of Natural Language Processing and how to use NLP libraries to perform various language processing tasks. As you progress, you can delve into more advanced topics and explore additional NLP tasks and techniques.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
