| # | Contents |
|---|---|
| 1. | What is difference between Primary Keys (PK) and Primary Indexes (PI) |
| 2. | What is Primary Index? |
| 3. | The Teradata Primary Index Choice (Which Column to make as PI) |
| 4. | Types of Primary Index |
| 6. | What is Unique and Non Unique Primary Index? |
| 7. | Multi-Column Primary Index |
| 8. | What is NO Primary Index? |
| 9. | Table CREATE Examples with four different Primary Indexes |
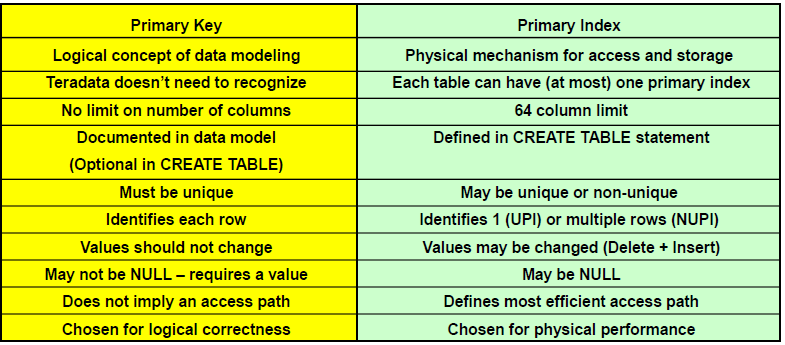
What is difference between Primary Keys (PK) and Primary Indexes (PI)
- Indexes are conceptually different from keys.
- A PK is a relational modeling convention which allows each row to be uniquely identified.
- A PI is a Teradata convention which determines how the row will be stored and accessed.
- A significant percentage of tables may use the same columns for both the PK and the PI.
- A well-designed database will use a PI that is different from the PK for some tables.
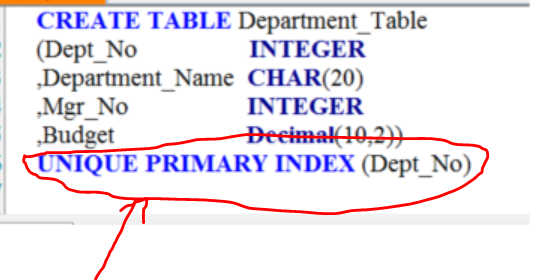
What is Primary Index?
- The Primary Index is defined when the table is CREATED
- It may consist of a single column, or a combination of columns (up to 64 columns)
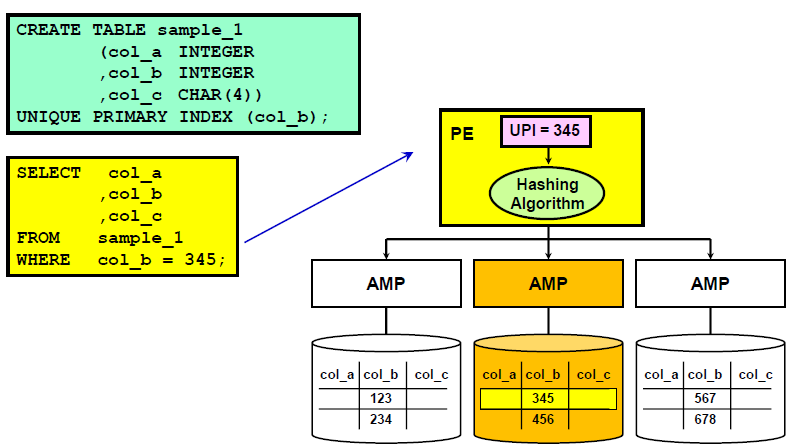
- The rows of every table are distributed among all AMPs
- For tables with a Primary Index , the uniformity of distribution of the rows of a table depends on the choice of the Primary Index. The actual distribution is determined by the hash value of the Primary Index.
- For tables without a Primary Index (Teradata 13.0 feature), the rows of a table are still distributed between the AMPs based on random generator code within the PE or AMP.
- Teradata spreads data rows for each table across the AMPs. Whenever the table needs to be read then each AMP has to read portion of the table stored on that AMP. If the AMPs start reading at the same time and there are an equal amount of rows on each AMP, then parallel processing works best. This parallel processing starts with the Primary Index(PI).
- Accessing the row by its Primary Index value is: -always a one-AMP operation and the most efficient way to access a row Other
The Teradata Primary Index Choice (Which Column to make as PI)
Consider below three criteria when selecting the primary index:
- A Good Access Path
- Even Distribution of Rows across all AMPs
- Low Volatility of the Primary Index Columns (very rare changes in PI column)
Important Points:
#The PI in a table will determine on which AMP a row will be stored.
#PI of a populated table cannot be modified but it can be altered for an empty table.
#Maximum of 64 columns can be added as PI for a table.
#PI is not Primary Key and allows NULL.
#Only one PI can be defined on a table.
Types of Primary Index
There are two types of Primary Index
- Unique Primary Index (UPI)
- Non Unique Primary Index (NUPI)
What is Unique and Non Unique Primary Index?
Unique Primary Index (UPI)
- A Unique Primary Index (UPI) spreads the rows of a table evenly across the AMPs.
- A Unique Primary Index (UPI) is always a one-AMP operation.
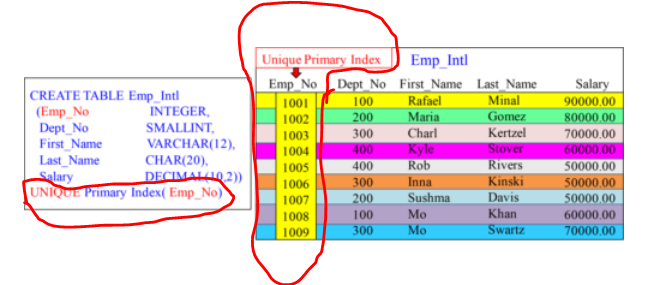
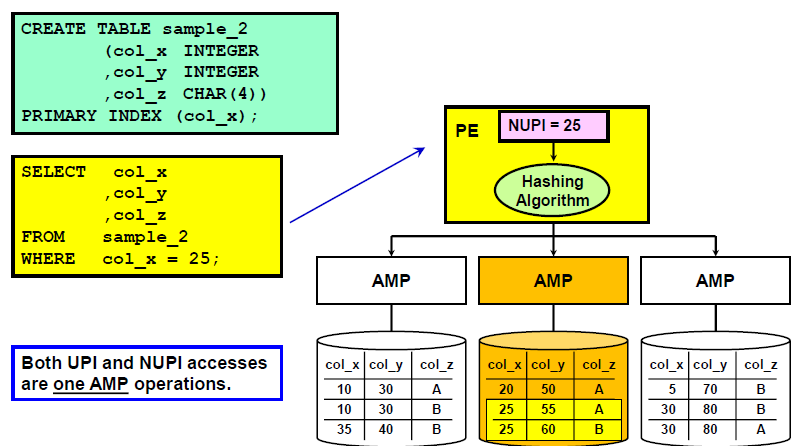
Accessing Via a Unique Primary Index
A UPI access is a one-AMP operation which may access at most a single row.
Primary Index in the WHERE Clause – Single-AMP Retrieve
Use the Primary Index column in your SQL WHERE clause and only 1-AMP retrieves.
Non Unique Primary Index (NUPI)
A Non-Unique Primary Index (NUPI) will have duplicates grouped together on the same AMP, so data will always be skewed (uneven).
Rows are not evenly distributed amongst AMP due to duplicates values.
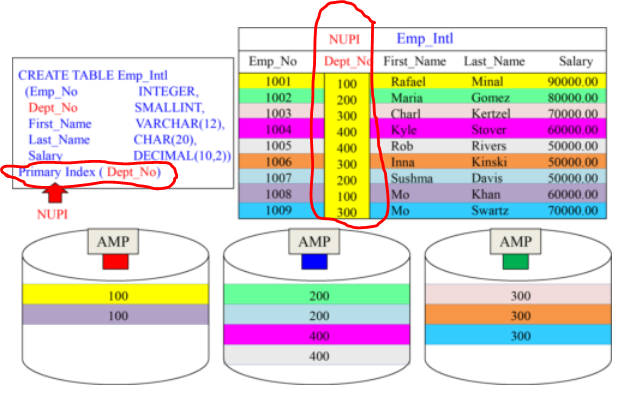
Accessing Via a Non-Unique Primary Index
A NUPI access is a one-AMP operation which may access multiple rows.
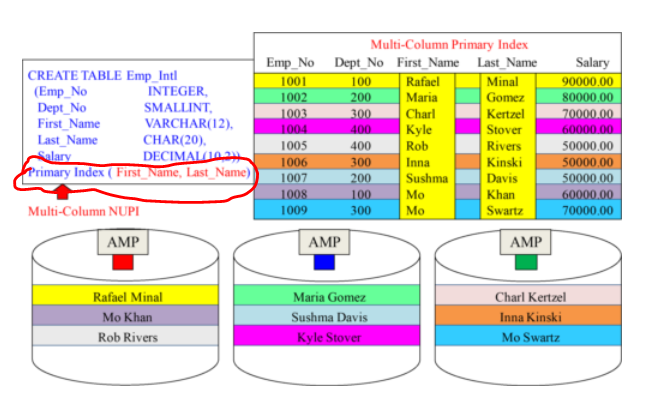
Multi-Column Primary Index
A conceptual example of a Multi-Column Primary Index
A table can have only one Primary Index, but you can combine up to 64 columns together max to form one Multi-Column Primary Index.
Here two columns have been chosen as Primary index: i.e. First_Name, Last_Name
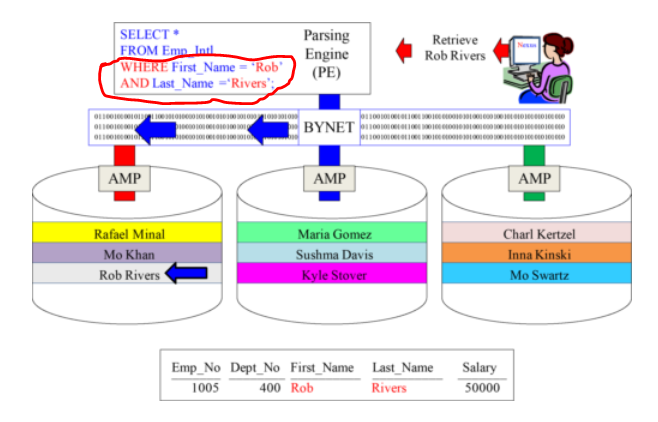
when Use the Primary Index Multi column in your SQL WHERE clause, and only 1-AMP retrieve
What is NO Primary Index?
A Full Table Scan is likely on a table with NO Primary Index.
Since a NO Primary Index (NoPI) table has no primary index, the system retrieves by performing a Full Table Scan which means All-AMPs read All-Rows they own once.
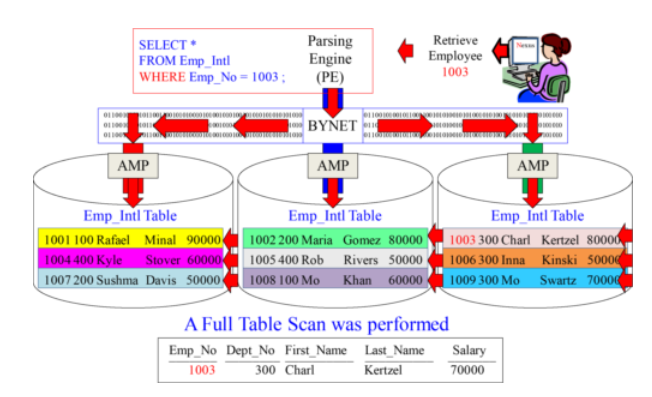
This No Primary Index (NOPI) topic will be discussed in details in another Tutorial.
Table CREATE Examples with four different Primary Indexes

IMPORTANT NOTES:
Why create a table with No Primary Index (NoPI)?
NoPI tables are designed to be staging tables. Data from a Mainframe or server can be loaded onto Teradata quickly with perfect distribution. Then, an INSERT/ SELECT can be done to move the data from the staging table (on Teradata) to the production table (also on Teradata). The data can be transformed in staging, and there are no Load Restrictions with an INSERT/ SELECT. A NoPI table usually isn’t queried, but can be!
What happens when you forget the Primary Index?
When you forget to define the Primary Index, Teradata will default to the first column in the table, and it will be defined as Non-Unique.
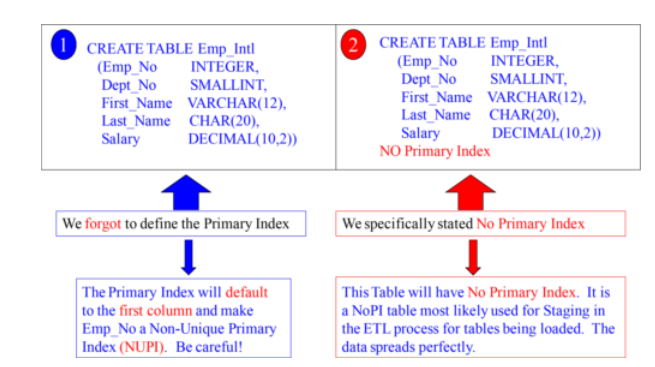
,
General rules for defining a Primary Indexes
#The PI should be selected in such a way that it should be as unique as possible ,more the unique index more evenly the rows will be distributed by the AMPs and better will be the space utilization.
#PI should be defined on as few columns as possible.
#The PI defined can have unique or non-unique values.
#Columns having more duplicates values should never be defined as PI, as it leads to more skewness (uneven data distribution on AMPs). Since data is skewed and when join is performed, it can cause the performance issue and lead to spool space error.
#PI should be chosen on the column/s which is/are frequently used in the WHERE clause for best way to retrieve rows.
MotoShare.in is your go-to platform for adventure and exploration. Rent premium bikes for epic journeys or simple scooters for your daily errands—all with the MotoShare.in advantage of affordability and ease.
