What is Spacy?

spaCy is an open-source natural language processing (NLP) library written in Python. It’s designed to be fast, efficient, and production-ready, making it a popular choice for various NLP tasks. spaCy focuses on providing high-performance, pre-trained models and efficient processing pipelines for a wide range of NLP tasks.
Top 10 use cases of Spacy:
Here are the top 10 use cases of spaCy:
- Tokenization: spaCy’s tokenization is highly accurate and efficient, breaking down text into individual words, punctuation, and other meaningful units.
- Part-of-Speech Tagging: spaCy can assign accurate part-of-speech tags to words in a sentence, helping to understand grammatical structure and word roles.
- Named Entity Recognition (NER): Spacy’s built-in named entity recognition (NER) model allows us to extract entities such as names, organizations, locations, and more from text data. This is particularly useful in information extraction, entity linking, and data analysis.
- Dependency Parsing: spaCy can perform dependency parsing, analyzing the grammatical relationships between words to create a syntactic tree that represents sentence structure.
- Text Classification: spaCy supports text classification tasks, where documents are assigned to predefined categories, making it useful for tasks like spam detection, sentiment analysis, and topic classification.
- Entity Linking: spaCy can link recognized entities to external knowledge bases like Wikipedia, providing additional context and information about the recognized entities.
- Text Summarization: spaCy can be used in conjunction with other techniques to build text summarization systems that automatically generate concise summaries of longer text documents.
- Translation: While spaCy is not primarily a machine translation library, it can assist in preprocessing and analysis steps of building translation systems.
- Information Extraction: spaCy’s NER and dependency parsing capabilities can be used to extract structured information from unstructured text data, which is useful in tasks like extracting relationships from news articles.
- Question Answering: spaCy can play a role in building question answering systems by helping to process and analyze text data for extracting answers to user queries.
These use cases demonstrate spaCy’s versatility in addressing a wide array of NLP tasks. Its efficiency, ease of use, and integration with pre-trained models make it a valuable tool for both researchers and developers working in the field of natural language processing. It’s worth noting that spaCy’s design philosophy focuses on efficiency and production-readiness, which makes it particularly well-suited for real-world applications.
What are the feature of Spacy?
spaCy is a powerful natural language processing (NLP) library that offers a wide range of features to efficiently process and analyze text data. Here are some of the key features of spaCy:
- Efficiency: spaCy is designed for high performance and efficiency, making it suitable for real-world applications and large-scale text processing tasks.
- Pre-trained Models: spaCy provides pre-trained models for various languages that can be used for tasks like part-of-speech tagging, named entity recognition, and more.
- Tokenization: spaCy’s tokenization accurately breaks down text into individual words, punctuation, and other meaningful units.
- Part-of-Speech Tagging: spaCy assigns part-of-speech tags to words in a sentence, helping analyze grammatical structure and word roles.
- Named Entity Recognition (NER): spaCy’s NER capabilities identify and classify named entities like people, organizations, locations, dates, and more.
- Dependency Parsing: spaCy performs dependency parsing, analyzing the grammatical relationships between words to create a syntactic tree representing sentence structure.
- Lemmatization: spaCy lemmatizes words, reducing them to their base or dictionary forms, which aids in text normalization and analysis.
- Text Classification: spaCy supports text classification tasks, allowing documents to be categorized into predefined classes.
- Word Vectors: spaCy can load pre-trained word vectors, which are useful for various NLP tasks like word similarity and semantic analysis.
- Customization: spaCy provides the flexibility to train and fine-tune models on domain-specific data for improved performance on specific tasks.
How Spacy works and Architecture?
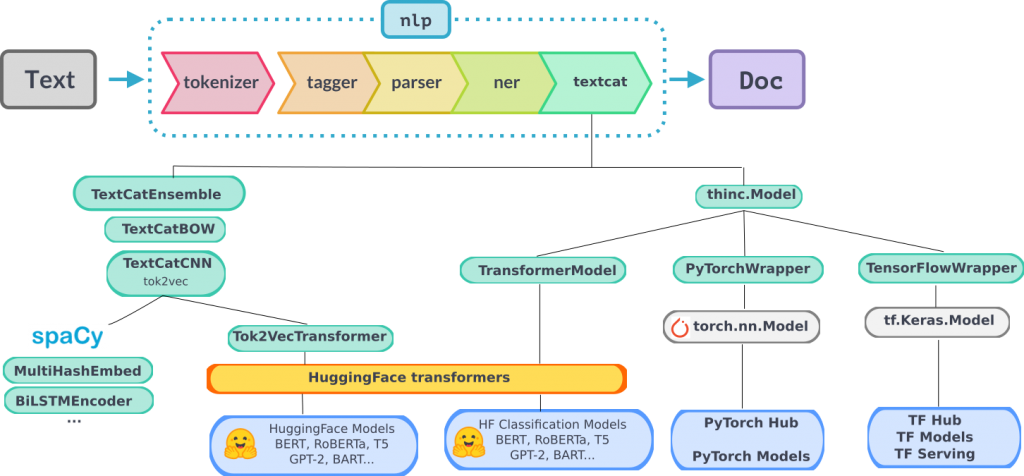
Now, let’s explore how spaCy works and its architecture:
1. Tokenization and Preprocessing:
spaCy starts by tokenizing the input text, breaking it down into individual tokens (words, punctuation, etc.) using language-specific rules and patterns.
2. Part-of-Speech Tagging and Dependency Parsing:
The tokenized text then goes through part-of-speech tagging, where each token is assigned a part-of-speech label (noun, verb, etc.). This is followed by dependency parsing, where the relationships between tokens are identified to create a syntactic tree.
3. Named Entity Recognition (NER):
The NER component identifies and classifies named entities within the text, such as names of people, organizations, dates, and more.
4. Lemmatization:
Lemmatization reduces words to their base or dictionary forms, helping to normalize text and reduce inflected forms to a common root.
5. Text Classification:
Text classification involves training models to categorize text into predefined classes. spaCy supports this through trainable pipelines.
6. Customization:
spaCy allows users to fine-tune models or train new components on domain-specific data to improve performance on specific tasks or domains.
7. Processing Pipeline:
spaCy’s processing pipeline consists of various components, each responsible for a specific NLP task. The input text flows through these components sequentially, and each component adds annotations to the document, enriching it with linguistic information.
8. Language Resources:
spaCy may use language-specific resources, such as lexicons and rule-based patterns, to enhance its processing capabilities.
9. Efficient Implementation:
spaCy’s architecture is designed for efficiency, making use of data structures and algorithms that optimize memory usage and processing speed.
Overall, spaCy’s architecture emphasizes efficiency, modularity, and production readiness, allowing developers to quickly and reliably integrate NLP capabilities into their applications.
How to Install Spacy?
There are two ways to install spaCy:
- Using pip
- Open a terminal window.
- Using the below command, Install the spaCy :
pip install spacy- Using Anaconda
- If you have Anaconda installed, you can install spaCy using the following command:
conda install spacyOnce spaCy is installed, you can verify the installation by running the following command in a Python interpreter:
import spacyCode language: JavaScript (javascript)If the installation is successful, this command will not print any output.
Here are some additional things to keep in mind when installing spaCy:
- spaCy requires Python 3.6 or higher.
- spaCy also requires some additional libraries, such as NumPy and SciPy. These libraries will be installed automatically when you install spaCy using pip or Anaconda.
- spaCy comes with a large number of pre-trained models for different languages. You can download the models you need using the
spacy downloadcommand.
For example, to download the pre-trained model for English, you would run the following command:
spacy download en_core_web_lgThe en_core_web_lg model is a large model that is suitable for a wide variety of tasks. If you are only interested in a specific task, you may want to choose a smaller model.
Basic Tutorials of Spacy: Getting Started

The following steps are the basic tutorials of spaCy:
- Importing spaCy
- Import the spaCy library:
Python
import spacy
2. Loading a pre-trained model
- Load the pre-trained model for English:
Python
nlp = spacy.load("en_core_web_lg")
3. Tokenizing a sentence
- Tokenize a sentence:
Python
sentence = "This is a sentence."
tokens = nlp(sentence)
This will return a list of tokens, each with its own properties, such as its lemma, part-of-speech tag, and dependency tag.
4. Named entity recognition
- Identify named entities in a sentence:
Python
for entity in tokens.ents:
print(entity.text, entity.label_)
This will print the named entities in the sentence, along with their labels.
5. Part-of-speech tagging
- Tag the parts of speech of the tokens in a sentence:
Python
for token in tokens:
print(token.text, token.pos_)
This will print the parts of speech of the tokens in the sentence.
6. Dependency parsing
- Parse the dependencies of the tokens in a sentence:
Python
for token in tokens:
print(token.text, token.dep_)
This will print the dependencies of the tokens in the sentence.
These are just a few of the basic tutorials available for spaCy. I encourage you to explore the documentation and tutorials to learn more about this powerful natural language processing toolkit.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
